SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Abstract: LLM agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SCOPE, a way to help AI “agents” (text-based helpers like smart chatbots) get better while they are working, not just before they start. Instead of keeping one fixed set of instructions (a “prompt”), SCOPE lets the agent update its own instructions by learning from its recent actions and the feedback it gets. Think of it like a coach who writes new tips into the team playbook during the game, so the team avoids repeating mistakes and finds better strategies on the fly.
What questions are the authors asking?
The authors focus on two simple questions:
- Why do AI agents fail even when they have the information they need?
- Can we make agents fix their mistakes and improve their strategies during a task by letting their prompts (instructions) evolve?
They point out two common failure types:
- Corrective failures: The agent makes an error, the system shows a helpful error message, but the agent treats it like a vague alarm and keeps doing the same wrong thing.
- Enhancement failures: The agent doesn’t make a clear mistake, but it misses chances to do better (for example, using only one search phrase when trying a few synonyms would work much better).
How does SCOPE work?
In everyday terms, SCOPE turns the agent’s “experience” (what it tried and what happened) into clear, written “guidelines” that get added to its instructions. These guidelines help the agent avoid the same errors and try smarter tactics next time—even during the same task.
Here’s the approach with simple analogies:
- The agent’s “prompt” = its rulebook or playbook.
- The agent’s “execution trace” = its activity log: what it tried, what it saw, and what worked or failed.
- “Guidelines” = short tips added to the rulebook, like “If you see this error, do X” or “Try more than one keyword when searching.”
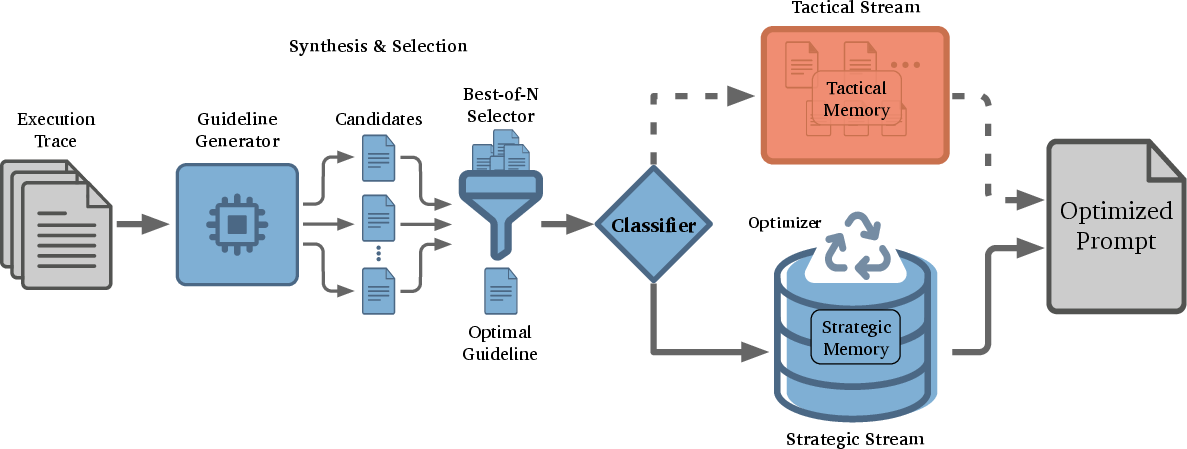
1) Learning from experience (Guideline Synthesis)
SCOPE watches the agent’s steps. When something important happens (an error, or a sub-step finishes), it:
- Reads the trace (what happened) and the current rules.
- Generates several possible “guidelines” (like a brainstorm of tips).
- Picks the best one using simple judging rules (so it keeps useful tips and discards the weak ones).
Analogy: A writer drafts a few short advice notes; an editor picks the clearest, most helpful one.
Two kinds of guidelines get created:
- Corrective guidelines: Quick fixes when errors happen (e.g., “If the tool says your argument is invalid, read its list of valid options and pick one of those.”)
- Enhancement guidelines: Upgrades when things “kind of work” but could be better (e.g., “If search results are weak, try synonyms or related phrases.”)
2) Two streams of memory (Dual-Stream Routing)
SCOPE stores guidelines in two “buckets”:
- Tactical (short-term): Tips that probably only help with the current task.
- Strategic (long-term): General tips that will likely help across many tasks.
Analogy: Sticky notes for today’s problem vs. golden rules kept in the permanent playbook.
A small classifier decides if a tip is short-term or long-term (and how confident it is). Low-confidence “maybe” tips stay short-term until they prove themselves.
3) Keeping the rulebook tidy (Memory Optimization)
If you keep adding tips forever, the rulebook gets messy. SCOPE cleans it up by:
- Merging conflicting tips,
- Removing overly specific tips that are already covered by a broader rule,
- Combining similar tips into one clear guideline.
Analogy: Tidying a binder by removing duplicates and organizing sections so it’s easy to follow.
4) Trying different styles in parallel (Perspective-Driven Exploration)
SCOPE evolves more than one version of the prompt at the same time, each with a different “style,” such as:
- Efficiency: Move quickly; fail fast and switch tactics.
- Thoroughness: Be careful; try more steps and cross-check.
At the end, it picks the best result. This covers more types of problems because some tasks reward speed, while others reward careful digging.
Analogy: Two teammates approach the same puzzle: one is a sprinter, the other a detective. You accept whichever solution succeeds.
What did they find?
The authors tested SCOPE on tough, multi-step benchmarks where agents have to search, reason, and use tools:
- HLE (2,500 expert-level questions),
- GAIA (165 tasks for general AI assistants),
- DeepSearch (complex research tasks).
Key results (higher is better):
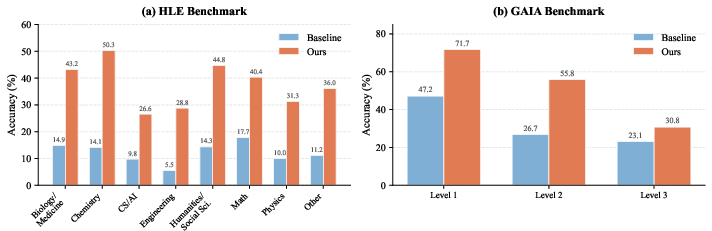
- On HLE: success rate jumped from 14.23% (baseline agent) to 38.64% with SCOPE.
- On GAIA: from 32.73% to 56.97%.
- On DeepSearch: from 14.00% to 32.00%.
Why this matters:
- The agent improved a lot without any human stepping in mid-task.
- SCOPE reduces error loops (doing the same wrong thing again).
- It also boosts performance when there’s no error, by finding smarter strategies (like better search terms).
- Running two styles (Efficiency and Thoroughness) in parallel added a big boost, because different problems need different tactics.
The authors also found:
- Putting guidelines into the agent’s core system instructions worked best overall (it made the agent “internalize” the advice).
- The exact model used to generate/choose tips wasn’t critical—quality filtering mattered more than having more tips.
Why does this matter?
In many real tasks—coding, research, browsing the web—AI agents face lots of changing, noisy information. Just giving them more data isn’t enough; they need better ways to manage it.
SCOPE shows a practical path forward:
- Agents can learn, mid-task, from what just happened.
- They can store quick fixes for now and general rules for later.
- They can explore different styles (fast vs. thorough) at the same time.
- They become more reliable and effective without needing a human to fix their prompts.
In short, instead of relying on one perfect, static prompt, SCOPE turns the prompt into something that evolves—helping AI agents get smarter as they work. This could make future AI assistants more dependable in long, complex jobs like deep research, multi-step problem solving, and tool-based workflows.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps the paper leaves unresolved and that future work could address:
- Formal guarantees and objectives
- Lack of a formal objective or surrogate reward for prompt evolution; no regret bounds or convergence/stability analysis for online updates to discrete prompts.
- No guarantees on monotonic performance improvement; absence of safeguards against catastrophic prompt drift during an episode.
- Triggering and detection mechanisms
- Unclear, unvalidated criteria for when “suboptimal” success triggers enhancement synthesis; needs precise detectors and false positive/negative analysis.
- No sensitivity study on trigger timing/frequency and its impact on performance vs. overhead.
- Quality control, rollback, and negative transfer
- No mechanism to demote or roll back harmful strategic guidelines once promoted; need automatic unlearning/undo and quarantine tests.
- No measurement of negative transfer rates (cases where added guidelines hurt performance), nor policies for conflict resolution beyond heuristic consolidation.
- Tactical vs. strategic routing
- The tactical/strategic classifier relies on LLM judgements and a fixed confidence threshold (0.85); no calibration procedure, ablation on threshold sensitivity, or robustness to misclassification.
- No study of cross-agent interference (a strategic guideline for one role degrading another), nor role-aware conflict detection across agents.
- Memory growth, pruning, and scalability
- Strategic memory capped at 10 guidelines per domain without a principled allocation scheme; no study of scaling behavior as domains/agents grow or as horizons lengthen.
- Consolidation/pruning pipeline is LLM-heuristic; lacks quantitative fidelity metrics (precision/recall of dedup/conflict merging) or reproducibility across models.
- Cost, latency, and token budget
- No end-to-end accounting of additional tokens, latency, or dollar costs introduced by synthesis, selection, classification, and consolidation steps.
- No policy for budget-aware operation (e.g., turning off synthesis under tight latency/cost constraints) or trade-off curves between accuracy and overhead.
- Placement policy generality
- Guideline placement results are only shown on GAIA; unclear if system-vs-user placement findings generalize to HLE/DeepSearch or other agent stacks.
- No adaptive placement strategy that selects placement per step/task/model based on predicted benefit vs. risk of over-compliance.
- Perspective-driven exploration
- Uses two hand-picked perspectives (Efficiency, Thoroughness); no method to automatically discover, adapt, or prune perspectives, or to select K optimally.
- The “global ensemble” relies on an oracle-like success evaluator at test time; no deployable, label-free selector to choose among perspectives online.
- Robustness and safety
- No analysis of adversarial or noisy trace poisoning (e.g., misleading errors) and its effect on synthesized guidelines or strategic memory integrity.
- No safety/ethics controls preventing the codification of biased, insecure, or harmful behaviors into persistent prompts.
- No privacy guarantees: synthesized guidelines could leak sensitive trace content; absence of redaction, PII filtering, or data governance.
- Generalization across models, modalities, and settings
- Tested only with GPT-4.1 and Gemini-2.5-Pro; unclear performance with smaller, open, or on-device models, and cost-accuracy trade-offs there.
- Limited evidence for multimodal robustness (e.g., images, code execution artifacts) and domains beyond the selected benchmarks (e.g., SWE-bench, robotics).
- No multilingual evaluation; unclear if guidelines transfer across languages or require language-specific memories.
- Interaction with existing components
- Unexplored synergy with RAG, summarization, and context compression: should guidelines steer retrieval/compression, or vice versa?
- No comparison or integration with planning/search scaffolds (e.g., tree search, debate) or with RL/DPO-style policy updates.
- Evaluation design and metrics
- Pass@2 union metric and step-level online evolution within the same benchmark may conflate learning and evaluation; need protocols that isolate cross-task generalization without “evaluation-time training” leakage.
- No breakdown of improvements by failure class tied to specific guideline types (causal attribution); limited beyond anecdotal “language adoption.”
- No measurement of hallucination rates, factuality, or calibration shifts introduced by evolving prompts.
- Parameterization and hyperparameters
- Fixed N=2 for Best-of-N without scaling study; unclear accuracy vs. cost frontier as N increases.
- Confidence thresholds, memory caps, and consolidation heuristics are set ad hoc; missing principled tuning or meta-learning of these controls.
- Lifelong and non-stationary settings
- No study of continual learning over long horizons with distributional shift, tool changes, or domain drift; mechanisms for aging out stale guidelines are unspecified.
- No evaluation of stability–plasticity trade-offs (e.g., preserving hard-won strategic principles while adapting to new regimes).
- Interpretability, governance, and audit
- While guidelines are human-readable, there is no tooling for versioning, provenance, diff-based auditing, or compliance checks prior to promotion to strategic memory.
- No human-in-the-loop protocols for high-stakes domains where autonomous prompt evolution may require review or approval.
- Deployment realism
- The success-selection function in perspective ensemble presumes access to ground-truth evaluators; real deployments often lack immediate verifiable success signals.
- No results under tight step limits or partial observability, where synthesis latency could preclude in-episode updates.
- Reproducibility and portability
- Heavy reliance on proprietary LLMs (for both base and meta-agents) raises questions about reproducibility across providers and versions.
- Portability to different agent frameworks/toolchains is untested; open question how much performance depends on the specific hierarchical system used.
These gaps suggest concrete directions: define formal objectives and rollback policies; develop calibrated, budget-aware triggering and routing; add adversarial/safety/privacy defenses; create oracle-free selectors for perspective ensembles; quantify cost–benefit frontiers; and validate generalization across models, modalities, languages, and agent frameworks.
Practical Applications
Immediate Applications
The following applications can be deployed now using SCOPE’s mechanisms (trace-based guideline synthesis, dual-stream routing, memory optimization, and perspective-driven exploration), with modest engineering effort to instrument agents and prompts.
- Software/DevOps (software)
- Actionable use case: Self-healing agentic coding copilots that synthesize corrective guidelines from stack traces (e.g., “use valid tool arguments listed in error message”) and enhancement guidelines (e.g., “try API synonyms, backoff, and retry budgets”), reducing error loops in CI, issue triage, and code generation.
- Tools/products/workflows: “Prompt Evolution Engine” for LangChain/AutoGen; Guideline Synthesizer microservice; Step-level system-prompt updater; Audit trail dashboards showing guideline diffs applied per step.
- Assumptions/dependencies: High-fidelity execution logging; APIs that support updating system prompts mid-episode; domain-specific rubrics for code/tool usage; cost/latency budget for meta-agent calls.
- Web Research Assistants (education, research, software)
- Actionable use case: Browsing agents that auto-learn query rewriting and synonym expansion (e.g., “base on balls” vs “walks”), fail-over rules for HTTP 403, and verification checklists for domain terms (Eulerian vs Hamiltonian), raising success rates on long-horizon research tasks.
- Tools/products/workflows: Query Rewriter Guidelines; Perspective manager (Efficiency vs Thoroughness) for Pass@2-style ensembles; Strategic memory per agent role (search, analyzer, browser).
- Assumptions/dependencies: Reliable web tooling; trace capture of search results and browser errors; guideline placement in system prompt (paper shows best performance).
- Customer Support & Helpdesk Bots (software, customer support)
- Actionable use case: Bots that integrate corrective guidelines from tool and policy errors (e.g., “map complaint categories to valid resolution codes”) and enhancement guidelines (e.g., “probe for missing customer attributes before escalation”), cutting repeated failure cycles.
- Tools/products/workflows: Dual-Stream Memory (tactical per ticket, strategic across tickets); Selector for best-of-N guidelines; Conflict resolution in strategic memory for evolving policies.
- Assumptions/dependencies: Access to policy and tool error logs; confidence thresholds tuned to avoid premature promotion; compliance guardrails for guideline content.
- Retrieval-Augmented Generation (RAG) and Knowledge Management (software, enterprise knowledge)
- Actionable use case: Adaptive RAG pipelines that evolve prompts to improve chunk retrieval, deduplication, and validation (“cross-check with second source” guidelines), optimizing both precision and recall.
- Tools/products/workflows: Guideline Optimizer that consolidates retrieval strategies; Placement controller preferring system-prompt storage for persistent principles.
- Assumptions/dependencies: Persistent stores for strategic guidelines per domain; instrumentation of retrieval errors and false positives.
- Financial Operations Assistants (finance)
- Actionable use case: Reconciliation agents that synthesize corrective rules from validation failures (e.g., “recompute totals with rounding policy X”) and enhancement guidelines (e.g., “try alternate date ranges”), reducing manual intervention.
- Tools/products/workflows: Per-agent strategic memory (ingestion vs reconciliation); Perspective ensemble for time-sensitive fail-fast vs thorough audit passes.
- Assumptions/dependencies: Access to detailed failure traces; strict audit logging of prompt evolution; domain-specific selection/classification rubrics.
- Clinical Documentation & Knowledge Agents (healthcare)
- Actionable use case: Documentation and literature search assistants that evolve adherence guidelines (“always include contraindications, dosage units, sources”) and corrective rules from tool/API errors, improving protocol compliance and retrieval reliability.
- Tools/products/workflows: Strategic guideline libraries per specialty; Memory consolidation to resolve conflicts across protocols.
- Assumptions/dependencies: Strong guardrails and human oversight; HIPAA/PHI constraints for trace storage; conservative confidence thresholds for promotion.
- Data Analytics & BI Assistants (software, enterprise)
- Actionable use case: Agents that learn enhancement guidelines for data validation (“check missingness before interpreting trend”), terminology mapping, and fail-over rules for API rate limits, reducing silent quality issues.
- Tools/products/workflows: Selector + Classifier tuned to elevate generalizable data hygiene practices to strategic memory; in-episode prompt refresh to recover mid-analysis.
- Assumptions/dependencies: Clean error signals from BI tools; rubric coverage for data quality checks.
- Security & Red-Teaming (security)
- Actionable use case: Agents that evolve restrictive guidelines from unsafe tool use attempts (“disallow shell commands without approval”) and enhancement rules (“prefer read-only queries on initial probe”), reducing risky behaviors in agentic workflows.
- Tools/products/workflows: Guideline Editor with policy templates; Conflict resolution mechanisms to maintain strictness; System-prompt placement for enforceable guardrails.
- Assumptions/dependencies: Policy-aligned rubrics; robust auditing; human-in-the-loop approvals for guideline promotion.
- Personal Productivity Assistants (daily life)
- Actionable use case: Assistants that learn user-specific search phrasing, supplier synonyms, and planning checklists (e.g., “verify itinerary constraints before booking”), switching perspectives for fast vs thorough outcomes.
- Tools/products/workflows: Local strategic memory keyed to user preferences; lightweight perspective toggle in UI; audit of prompt changes.
- Assumptions/dependencies: User consent for trace storage; small memory caps with periodic consolidation to avoid drift.
- Academic Use (academia)
- Actionable use case: Research groups instrument agents to collect traces and auto-evolve prompts for long-horizon tasks (datasets curation, multi-source synthesis), replicating SCOPE’s gains without bespoke fine-tuning.
- Tools/products/workflows: Open-source SCOPE components (Generator, Selector, Classifier, Optimizer); benchmarking harness for Pass@2 and subcategory analyses.
- Assumptions/dependencies: Availability of trace data; standardized rubrics; compute budget for meta-agents.
Long-Term Applications
These applications require further research, scaling, or development (e.g., enterprise-wide adoption, robust governance, or deeper integration with tooling and policy).
- Enterprise AgentOS with Self-Evolving Prompts (software, cross-industry)
- Vision: A platform where all internal agents (search, analytics, coding, support) maintain role-specific strategic memories and evolve prompts online, with federation across teams.
- Potential tools/products/workflows: Federated GuidelineBank; Organization-level perspective ensembles; Prompt Diff + Risk Scoring; Policy-aware promotion pipelines.
- Assumptions/dependencies: Cross-team data-sharing agreements; privacy-preserving trace aggregation; standardized rubric taxonomies; governance for prompt drift.
- Regulated-Sector Compliance Automation (healthcare, finance, public sector)
- Vision: Guideline evolution integrated with compliance frameworks (SOX, HIPAA, GDPR), with auditors reviewing guideline history and conflict resolution outcomes.
- Potential tools/products/workflows: Compliance-grade audit trails; “Guideline Approval Workflows” with multi-level sign-off; Safety classifiers gating promotions.
- Assumptions/dependencies: Clear regulations for dynamic instruction changes; certifiable logging; human oversight; testing sandboxes.
- Adaptive RPA/BPM with Self-Healing Workflows (software, operations, robotics-adjacent)
- Vision: Business processes that recover from tool/API failures via corrective guidelines and tune throughput via enhancement guidelines, managed by perspective streams.
- Potential tools/products/workflows: RPA adapters for trace capture; policy-driven placement controllers; real-time prompt refresh; ensemble orchestrators.
- Assumptions/dependencies: Mature observability; consistent error semantics across tools; real-time update capabilities without breaking SLAs.
- Cross-Organization Knowledge Networks (education, research, enterprise)
- Vision: Shared but privacy-preserving strategic guideline libraries capturing best practices (e.g., domain term disambiguation, verification steps), distributed via hubs.
- Potential tools/products/workflows: Federated learning with guideline-level aggregation; de-identified trace sampling; meta-rubric marketplaces.
- Assumptions/dependencies: Data governance and IP agreements; differential privacy for traces; versioned guideline standards.
- Automated Perspective Selection and Meta-Optimization (software, AI tooling)
- Vision: Systems that learn when to deploy Efficiency vs Thoroughness (or other perspectives) based on task features, and automatically tune N, K, confidence thresholds.
- Potential tools/products/workflows: Meta-controller trained on outcome data; task classifier to pre-route perspective; adaptive memory caps.
- Assumptions/dependencies: Sufficient labeled outcomes; robust generalization across domains; safeguards against mode collapse.
- Safety-Aware, Policy-Infused Prompt Evolution (policy, safety, governance)
- Vision: Formal guardrails embedded into evolution pipelines (e.g., prohibited content, risk scoring), ensuring guideline synthesis never weakens safety constraints.
- Potential tools/products/workflows: Policy-checker microservice; conflict resolution that prioritizes safety; red-team feedback loops.
- Assumptions/dependencies: Machine-readable policy specs; reliable safety classifiers; periodic third-party audits.
- Standardization of Trace-to-Guideline Rubrics (academia, standards bodies)
- Vision: Community-agreed rubric suites for corrective/enhancement synthesis, selection, classification, and optimization, enabling reproducible results across platforms.
- Potential tools/products/workflows: Benchmark suites for long-horizon tasks; open catalogs of rubric templates per sector; reference implementations and evaluation protocols.
- Assumptions/dependencies: Broad consortium participation; evolving standards to match new tool ecosystems; funding and governance.
- Hybrid Learning: Prompt Evolution + RL/Finetuning (software, AI research)
- Vision: Systems that use SCOPE-style evolved guidelines to shape reward functions, curricula, or finetuning datasets, blending online prompt evolution with model-level learning.
- Potential tools/products/workflows: Guideline-to-reward translators; dataset generators from strategic memory; iterative training pipelines.
- Assumptions/dependencies: Stable mapping from guidelines to training signals; safe data curation; compute resources for periodic retraining.
- Consumer-Grade Agents with Preference-Conditioned Evolution (daily life)
- Vision: Agents that continuously adapt to personal styles and constraints (budget, risk tolerance) via strategic memory and automated consolidation, with clear opt-in controls.
- Potential tools/products/workflows: Preference rubrics; memory visibility and rollback; portable strategic memories across devices.
- Assumptions/dependencies: Transparent consent flows; on-device or encrypted storage; simple UX for managing perspective and guideline history.
In all cases, feasibility hinges on core dependencies highlighted in the paper: access to rich execution traces; step-level update capability (prefer system-prompt placement for general principles); robust rubric design; confidence thresholds to control guideline promotion; memory consolidation to avoid drift or conflict; and cost/latency budgets for the Generator/Selector/Classifier/Optimizer meta-agents.
Glossary
- ACE (Agentic Context Engineering): A playbook-based method that maintains and evolves structured strategy lists for LLMs. "Agentic Context Engineering (ACE): A playbook-based learning approach that maintains bullet-point strategies across predefined categories and updates them via a reflector-curator loop."
- alarm-based approach: A correction style where errors are surfaced but not translated into actionable fixes. "We characterize this as an alarm-based approach: the agent is alerted to errors but not taught how to fix them."
- Agent-Specific Optimization: Tailoring optimization and prompt evolution to each agent role independently. "Additionally, we implement Agent-Specific Optimization, step-level updates, and place Synthesized guidelines in the system prompt (see Section~\ref{sec:placement} for ablation)."
- Best-of-N selection: Choosing the best guideline from multiple candidates to reduce variance. "We configure SCOPE with candidates for Best-of-N synthesis and parallel streams (Efficiency and Thoroughness) for global exploration."
- Corrective Failures: Failures where agents ignore actionable error information and repeat mistakes. "(a) Corrective Failure: The agent treats errors as generic alarms, entering error loops despite the error message containing the solution."
- DC (Dynamic Cheatsheet): A test-time learning framework that accumulates and updates persistent memory for LLMs. "(1) Dynamic Cheatsheet (DC): A test-time learning framework that endows LLMs with persistent, evolving memory."
- DeepSearch: A benchmark for multi-step, real-world agent tasks focused on deep research and browsing. "We analyzed over 1.5 million lines of execution logs from baseline agents on the GAIA~\cite{mialon2023gaia} and DeepSearch~\cite{chen2025xbench} benchmarks."
- Dual-Stream Routing: A mechanism that routes synthesized guidelines into tactical or strategic memory based on scope and confidence. "A Dual-Stream Routing mechanism balances tactical updates (immediate error correction) with strategic updates (long-term principles), ensuring the agent not only survives the current task but becomes smarter for future ones."
- Enhancement Failures: Failures where agents miss optimization opportunities despite no explicit errors. "(b) Enhancement Failure: The agent persists with suboptimal strategies (e.g., single-term search) when no error is raised."
- execution trace: The logged sequence of actions and observations produced during agent execution. "SCOPE operates on the insight that the agent's own execution trace serves as the perfect training signal."
- GAIA: A benchmark for evaluating general AI assistants on multi-step tasks. "We analyzed over 1.5 million lines of execution logs from baseline agents on the GAIA~\cite{mialon2023gaia} and DeepSearch~\cite{chen2025xbench} benchmarks."
- Global Ensemble: Combining results from multiple evolved prompts or perspectives to maximize success. "The Global Ensemble captures the union of these strengths."
- Guideline Synthesis: Generating optimization instructions from traces to improve agent behavior. "Our framework, illustrated in Figure~\ref{fig:method_overview}, consists of four components: (1) Guideline Synthesis, (2) Dual-Stream Routing, (3) Memory Optimization, and (4) Perspective-Driven Exploration."
- HLE: Humanity’s Last Exam, an expert-level benchmark for multi-step reasoning. "Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention."
- hierarchical agent system: An architecture with a planning agent and specialized sub-agents coordinating over many steps. "We implement a hierarchical agent system with a planning agent that delegates to specialized subordinate agents (web search, analyzer, browser), each equipped with domain-specific tools."
- in-context correction methods: Approaches that insert feedback and errors into the conversation context to guide subsequent actions. "In-context correction methods feed errors and self-generated feedback back into the agent's context to guide future steps."
- infinite context windows: Model capability to handle very large context lengths, reducing the need for retrieval or truncation. "Innovations such as Retrieval-Augmented Generation (RAG)~\cite{lewis2020retrieval} or infinite context windows~\cite{team2024gemini} focus on feeding more data to the agent."
- long-horizon scenarios: Tasks requiring extended, multi-turn planning and robustness over many steps. "confirming that dynamic prompts prevent error propagation and maintain coherence in long-horizon scenarios."
- meta-agent: A higher-level component (e.g., generator, classifier) that evolves or optimizes other agents. "each meta-agent uses the same model as the base agent it optimizes."
- online optimization problem: Framing prompt evolution as an optimization that occurs during execution rather than offline training. "SCOPE frames context management as an online optimization problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt."
- Pass@2: An evaluation metric where a task is considered solved if any of two runs succeeds. "All methods are evaluated with two independent runs per task; a task is considered solved if either run succeeds (Pass@2)."
- per-agent optimization: Evolving prompts separately for each agent role to capture role-specific patterns. "Per-agent optimization: Each agent role evolves its own prompt based on role-specific patterns."
- Perspective-Driven Exploration: Running multiple concurrent evolution streams under distinct strategic perspectives. "Finally, Perspective-Driven Exploration evolves multiple parallel prompts guided by distinct perspectives (e.g., Efficiency vs. Thoroughness), maximizing strategy coverage."
- Retrieval-Augmented Generation (RAG): Augmenting generation with retrieved documents to provide grounding and knowledge. "Innovations such as Retrieval-Augmented Generation (RAG)~\cite{lewis2020retrieval} or infinite context windows~\cite{team2024gemini} focus on feeding more data to the agent."
- strategic memory: Persistent memory of general, high-confidence guidelines applied across tasks. "We maintain a strategic memory $\mathcal{M}_{\text{strat} = \{g_1, g_2, \ldots\}$ for long-term guidelines and a tactical memory $\mathcal{M}_{\text{tact}$ for task-specific guidelines."
- Subsumption Pruning: Removing specific guidelines that are subsumed by broader ones during memory consolidation. "(2) Subsumption Pruning: removing specific guidelines covered by general ones."
- system prompt: The instruction space used as background guidance for agent behavior. "A counter-intuitive finding emerges: system prompt placement achieves the highest accuracy (46.06\%) despite more tasks hitting the step limit than user prompt (227 vs. 130)."
- tactical memory: Task-specific guidelines valid only within the current episode. "We maintain a strategic memory $\mathcal{M}_{\text{strat} = \{g_1, g_2, \ldots\}$ for long-term guidelines and a tactical memory $\mathcal{M}_{\text{tact}$ for task-specific guidelines."
- Trace-Based Guideline Synthesis: Generating guidelines by analyzing the agent’s own action-observation history. "Through Trace-Based Guideline Synthesis, SCOPE analyzes these traces online to generate guidelines that teach the agent how to handle specific context patterns."
- user prompt: The instruction channel provided directly in the conversation, which can lead to over-compliance. "Conversely, user prompt placement leads to over-compliance---the agent follows instructions too strictly, terminating early rather than continuing exploration, which results in fewer errors but lower task success."
Collections
Sign up for free to add this paper to one or more collections.