Qwen2.5-1M Technical Report
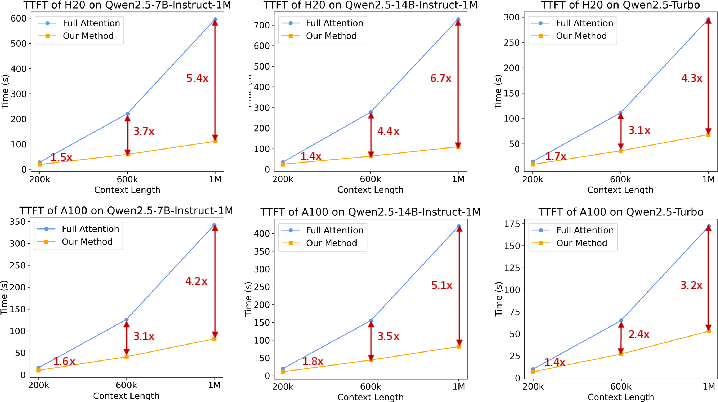
Abstract: We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

