Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Abstract: Multimodal learning has rapidly advanced visual understanding, largely via multimodal LLMs (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces MetaCanvas, a new way to help AI systems make pictures and videos that better match what we ask for. Today’s AI “understands” images and text very well (it can answer questions about pictures, reason about scenes, etc.), but when it tries to create images or videos, it often gets details wrong—like putting objects in the wrong place or mixing up colors and attributes. MetaCanvas aims to fix that by letting the “smart thinking” part of the AI plan a layout—like a sketch—before the “drawing” part creates the final image or video.
The main questions the paper asks
The authors focus on three simple questions:
- Can the reasoning part of an AI (a multimodal LLM, or MLLM) do more than just read text prompts—can it actually plan where things should go in a picture or video?
- If we let the MLLM make a kind of rough “blueprint” of the scene, will the final images and videos be more accurate and easier to control?
- Will this idea work across many tasks (image generation, image editing, video generation, video editing) and with different kinds of generator models?
How MetaCanvas works (in everyday language)
Think of AI image/video creation as having two roles:
- The planner: a “smart” model that understands language and visuals (the MLLM). It’s good at reasoning (e.g., “a red ball to the left of the blue box”).
- The builder: a “drawing” model (a diffusion model) that actually paints the pixels.
Today, the planner usually just gives the builder a short text summary and says, “Go make it.” That’s like telling a builder “Make a house with three rooms” and hoping they guess the layout you want.
MetaCanvas changes this by giving the planner a “canvas” to sketch on first:
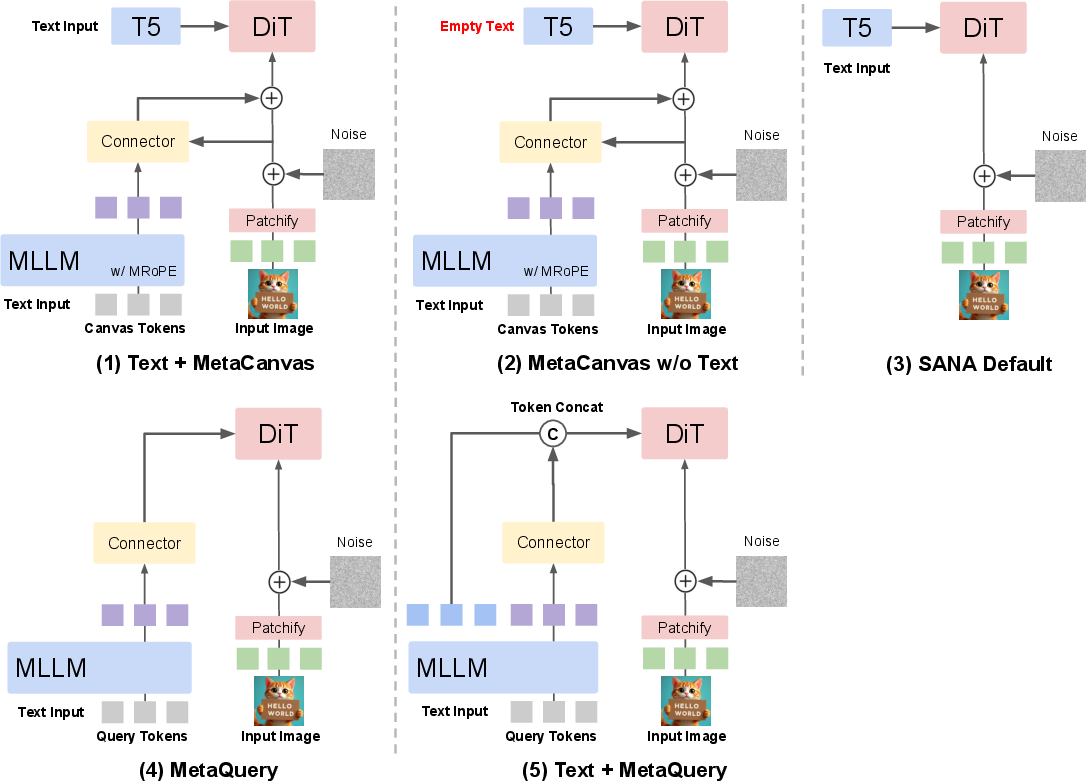
- Canvas tokens: These are like sticky notes arranged on a grid (for images) or across space and time (for videos). The MLLM writes its plan onto these tokens—where objects should go, their sizes, colors, relations, and how things should move over time.
- Latent space: Before the builder draws the final high-quality picture/video, it works in a fuzzy hidden draft space called “latent space.” MetaCanvas puts the planner’s sketch directly into this hidden draft, patch by patch, so the builder has a clear guide as it draws.
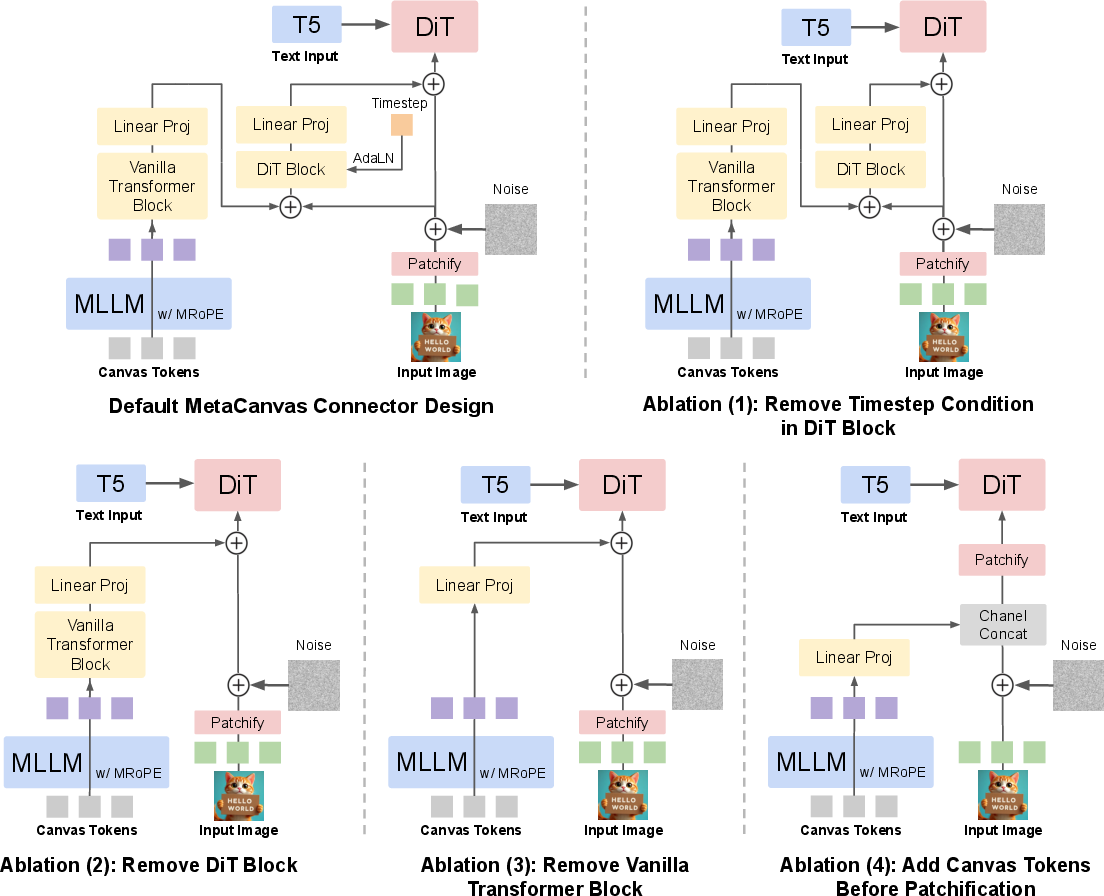
- Connector: A small add-on module acts like a translator that takes the planner’s canvas sketch and blends it into the builder’s draft. It’s “lightweight,” meaning it adds only a little extra training and computing cost.
- For videos: Instead of sketching on every frame (which would be heavy), the planner writes on a few key frames (keyframes). The system then smoothly fills in the in-between frames, keeping motion consistent and saving time.
A few extra details that help:
- Zero-initialization: At the start of training, the sketch doesn’t change the builder’s behavior. This keeps training stable and prevents early chaos.
- Minimal changes to the planner: The MLLM stays mostly frozen (unchanged), so it keeps its strong understanding skills. Small, cheap updates (like LoRA) can be added only where needed.
- Works with different builders: The idea was tried with multiple diffusion models (image- and video-focused) and across several tasks.
What they found and why it matters
Across six tasks—text-to-image, image editing, text-to-video, image-to-video, video editing, and in-context video generation—MetaCanvas showed clear benefits.
Here are the key results, in plain terms:
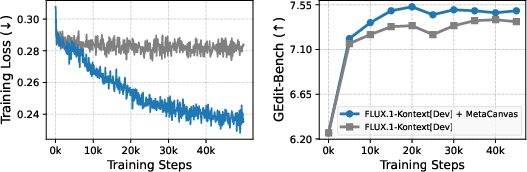
- More accurate layouts and attributes: Images and videos better matched what was asked (e.g., correct counts, colors, positions). On a standard image test (GenEval), MetaCanvas learned faster and beat other design choices.
- Stronger editing: For image editing (changing or adding parts of a picture), MetaCanvas improved both quality and how well edits matched the prompt on popular tests (GEdit and ImgEdit). It did this with only small, efficient add-on modules.
- Video generation stays strong: When used for video generation, MetaCanvas stayed on par with well-known open-source models, while also unlocking strong editing abilities.
- Much better video editing control: On a custom video editing benchmark, MetaCanvas reached top scores in both AI-based evaluations and human judgments, especially for “did it edit the right thing in the right place?”—the hardest part of editing.
- Works in context: With reference images (like “make a video using this character and this object”), MetaCanvas performed competitively, especially on scenes where people interact with objects.
Why this matters: It shows that treating the planner as a “layout artist” and not just a “text writer” gives the builder much better guidance. That leads to images/videos that are more faithful, more controllable, and more reliable.
What this could mean going forward
- Better creative tools: Photo and video editors could get precise, easy controls—“make the car move from left to right behind the tree”—and expect the model to follow that structure.
- Smarter, safer content creation: When details matter (like scientific visuals or instruction videos), planning in a structured canvas can reduce mistakes.
- A general recipe: The approach works across different generator models and tasks. That makes it a promising building block for future AI systems that both understand and create complex visual scenes.
- Closer link between “understand” and “create”: By letting the reasoning model plan inside the builder’s space, the gap between understanding (what should be made) and generation (how it’s made) gets much smaller.
In short, MetaCanvas is like letting the architect draw a real blueprint on the exact grid the construction team uses. With that shared plan, the final building—the image or video—matches the idea much more closely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the main unresolved issues and opportunities for future research that emerge from the paper.
- Interface placement and depth: The paper fuses canvas tokens with latents “after patchification” via a two-block connector, but does not explore optimal injection schedules (e.g., early vs. late layers, multiple layers, timestep-dependent routing, or multi-block injection across the DiT), nor quantify trade-offs in quality vs. controllability across these choices.
- Adaptive spatiotemporal canvas design: Keyframes are fixed and linearly interpolated; there is no exploration of adaptive keyframe selection (learned or prompt-dependent), non-linear temporal interpolation, or spatially variable canvas resolution/token density based on scene complexity, motion, or region importance.
- Structural supervision for canvas tokens: Canvas embeddings are trained end-to-end without explicit structure; the paper does not test auxiliary losses or supervision (e.g., bounding boxes, segmentation, depth, optical flow, scene graphs) to enforce geometric grounding, attribute binding, or motion consistency.
- Applying canvas to reference frames: For video tasks, canvas tokens are excluded from reference frames; the impact of injecting or modulating canvas on reference latents (or conditioning frames) is not evaluated and may affect preservation and alignment.
- Joint MLLM training vs. frozen core: The MLLM is mostly frozen (with optional LoRA only after <EoS>), leaving open whether partial/full fine-tuning, layer-wise adapters, or instruction-tuning targeted at spatial/temporal planning would improve canvas quality without degrading understanding.
- LoRA activation strategy: Activating MLLM LoRA only after <EoS> is a design choice; the paper does not compare alternative strategies (e.g., continuous activation, gated activation per layer/timestep, or task-specific adapters) and their impact on reasoning vs. generation trade-offs.
- Positional encoding sensitivity: Canvas tokens rely on multimodal RoPE; there is no ablation on positional encoding variants (e.g., learned 2D/3D positional embeddings, disentangled spatial vs. temporal encodings) or their effects on layout precision and temporal coherence.
- Scaling laws and capacity: The work lacks systematic analysis of how performance scales with the number/dimension of canvas tokens, connector size, model sizes (MLLM and DiT), and training data volume; actionable scaling laws to guide resource allocation are missing.
- Inference overhead and latency: Training overhead is briefly reported, but inference-time latency, memory footprint, and throughput (especially for long videos or high resolutions) are not quantified, limiting deployability assessments.
- Quality vs. semantics trade-off: Results suggest improved editing semantics sometimes coincide with slight drops in video quality (e.g., VBench); the paper does not analyze or propose methods to balance semantic accuracy and perceptual quality (e.g., multi-objective losses, curriculum schedules).
- Robustness and failure modes: There is no systematic characterization of failure cases (temporal drift, flicker, occlusions, attribute swaps, multi-object interactions, crowded scenes) or robustness to out-of-distribution prompts, long/ambiguous instructions, or extreme motion.
- Task breadth and benchmarks: Evaluation relies on GenEval (small-scale), curated video-editing sets (300 prompts), and GPT-4o-based VLM assessment; broader, standardized, and open benchmarks for layout binding, temporal reasoning, and complex composition (e.g., TIFA, DrawBench, long-horizon video datasets) are not covered.
- Multilingual generalization: Although Qwen2.5-VL is multilingual, the paper does not evaluate cross-lingual prompts, code-switching, or multilingual semantics-grounding for image/video generation/editing.
- Interpretability of canvas embeddings: Beyond PCA visualizations, there is no rigorous analysis of what canvas channels encode (e.g., geometry, semantics, motion) or causal probing to understand how canvas edits map to generative outcomes.
- Hierarchical planning: The approach is patch-wise; hierarchical coarse-to-fine planning (global layout → local details → temporal refinements) and multi-scale canvas fusion are not explored, which may improve structure and reduce artifacts.
- Connector variants: The connector uses a vanilla Transformer and DiT block with AdaLN and zero-init; alternative designs (FiLM, hypernetworks, learned gates, mixture-of-experts, modulation at attention keys/values, multi-branch connectors) and their efficacy remain untested.
- Compatibility with other controls: Interaction with external controls (ControlNet styles like depth/edge/pose, masks, camera paths) is not studied; how canvas complements or conflicts with explicit control signals is unknown.
- Reference-guided generation breadth: While reference image-to-video is demonstrated, complex multi-reference setups (conflicting visual cues, style + identity + layout constraints), reference prioritization, and conflict-resolution strategies are not evaluated.
- Long-horizon and high-res limits: Experiments use 121-frame videos at 720p; scalability to longer sequences, higher frame rates/resolutions (e.g., 4K), and streaming/incremental generation remains unaddressed.
- Safety and content governance: There is no discussion of safety filters, bias/fairness, misuse mitigation, or dataset provenance for the large-scale curated training sets—all critical for real-world deployment.
- Data curation and coverage: Training data sources and distributions (domains, motion types, rare scenes) are only sketched; quantitative coverage analysis, license compliance, and strategies for reducing biases/data leakage are not provided.
- Preservation of MLLM understanding: The claim that understanding is preserved (via freezing and <EoS>-activated LoRA) is not empirically validated on standard multimodal understanding benchmarks, leaving potential regressions unmeasured.
- Generality across backbones: Although tested on three diffusion backbones (MMDiT and cross-attention), generalization to flow-matching, rectified flows, token-based video decoders, autoregressive image/video transformers, or hybrid pipelines is not shown.
- User-controllable canvases: The canvas is implicit (MLLM-written); interactive or constraint-driven canvases (user edits, bounding boxes, spatial/temporal masks, motion paths) and authoring tools are not explored.
- Training stability and initialization: Zero-initialized residuals stabilize training, but the paper does not examine alternative initializations, curriculum strategies, or connector warm-starts and their impact on convergence and final quality.
- Scheduling across timesteps: AdaLN modulates canvas influence by timestep, but optimal control schedules (e.g., stronger early layout guidance, decaying late influence, or adaptive per-prompt schedules) are not investigated.
- Combination with explicit planning outputs: The approach does not compare canvas-only planning versus mixed interfaces (textual scene graphs, layouts, scripts + canvas) to test whether hybrid planning improves controllability or reduces ambiguity.
- Evaluation with open-source metrics: Heavy reliance on GPT-4o (closed-source) for evaluation introduces opacity; adoption of open, reproducible VLM metrics and human studies with detailed rubrics would strengthen conclusions.
Practical Applications
Practical Applications of MetaCanvas
Below are practical, real-world applications derived from the paper’s findings and innovations. Each application is grouped by deployment horizon and tied to relevant sectors, with indicative tools/workflows and feasibility notes.
Immediate Applications
Industry
- Creative production (film, animation, games, advertising): layout-accurate text-to-image/video previsualization and storyboarding; continuity-preserving edits across shots
- Sectors: media/entertainment, advertising, game development
- Tool/product: “Keyframe Canvas Planner” plugin for DCC tools (e.g., Blender, Unreal, Adobe After Effects)
- Workflow: prompt → MLLM reasoning → multi-dimensional canvas tokens → diffusion generation (image/video) → iterative refinement
- Assumptions/dependencies: access to a capable MLLM (e.g., Qwen2.5-VL) and diffusion backbone (e.g., FLUX/Wan), GPU resources; licensing for model weights
- E-commerce product visualization: batch background replacement, colorway generation, attribute-locked edits; creating short product showcase videos from reference photos
- Sectors: retail/e-commerce
- Tool/product: “Product Visualizer” service with structured, attribute-bound edits
- Workflow: ingest catalog images + text specs → MLLM-generated canvas priors → patch-wise diffusion editing → quality checks via VLM evaluators
- Assumptions/dependencies: domain-specific fine-tuning for brand aesthetics; content safety and QA pipelines
- Marketing A/B content generation: structured variants (layout, color, copy-aligned visuals) with tight attribute binding for controlled experiments
- Sectors: marketing, advertising technology
- Tool/product: “Layout-locked Variant Generator” integrated with ad ops platforms
- Workflow: campaign brief → templated layout plan via canvas → batch generation → automated scoring (GenEval/VBench/VLM evaluators) → deployment
- Assumptions/dependencies: integration with ad tooling, governance for brand safety and claims substantiation
- Precision video editing in commercial suites: region-specific edits (replace/remove objects, style transfers), per-frame consistency with sparse keyframe canvases
- Sectors: post-production, creator economy
- Tool/product: “MetaCanvas Editing Plugin” for Premiere/Resolve; SDK for mobile apps
- Workflow: text/image/video prompt → canvas tokens added post-<EoS> → patch-wise fusion in diffusion latents → export and review
- Assumptions/dependencies: GPU/accelerators for near-real-time edits; UI for keyframe selection; reliable temporal consistency (validated in VBench/GPT-4o-based evals)
- Synthetic scenario generation for simulation/training: image/video scenes with precise object placement, spatial relations, and attribute locks for perception models
- Sectors: autonomous driving, security, robotics simulation
- Tool/product: “Scenario Composer” with spatial-temporal planning via canvas tokens
- Workflow: scenario spec → MLLM layout/motion plan → diffusion generation → dataset integration
- Assumptions/dependencies: domain adaptation (traffic rules/lighting/weather), dataset governance; careful validation to avoid spurious correlations
Academia
- Reproducible research on MLLM–diffusion interfaces: benchmarking structured control (layout, attribute binding, motion coherence); ablation of connectors and canvas designs
- Sectors: academic ML research
- Tool/product: open-source MetaCanvas connectors and evaluation harness (GenEval, VBench, OmniContext-Video)
- Workflow: swap backbones (MMDiT/cross-attention), vary canvas keyframes, test zero-init and AdaLN effects, report VLM/human eval
- Assumptions/dependencies: public datasets or synthetic data; licensing for backbones
- Interpretability of multimodal planning: visualizing canvas features (e.g., PCA of connector outputs) to study spatial-temporal reasoning priors
- Tool/product: “Canvas Feature Explorer” for latent-space interpretability
- Assumptions/dependencies: access to connector internals; consistent visualization protocols
Policy and Compliance
- Privacy-preserving editing and moderation: precise per-region/patch redaction (blur faces, remove PII signs) with consistent temporal handling across frames
- Sectors: platforms, compliance, safety
- Tool/product: “Policy-Driven Redaction Engine” using canvas for spatiotemporal control
- Workflow: detection → canvas constraints → diffusion edits → audit log with prompts and edit footprints
- Assumptions/dependencies: robust detection (faces/plates/logos), human-in-the-loop review; governance for edit provenance
Daily Life
- Consumer photo/video apps: “describe your edit” with fine spatial control; turn an image into a short video with stable layout and attribute consistency
- Sectors: consumer apps, social media
- Tool/product: mobile editing app with canvas-driven precision controls and reference-guided I2V
- Workflow: user prompt/reference → MLLM planning → keyframe canvas → diffusion → quick share
- Assumptions/dependencies: on-device optimization or cloud inference; safety filters for harmful content
Long-Term Applications
Industry
- Studio-grade generative pipelines: multi-scene productions with character/prop continuity, shot-to-shot spatial alignment, and editable plans across production stages
- Sectors: film/TV/AAA gaming
- Tool/product: “Generative Previz Suite” with canvas versioning and diff patches
- Workflow: script → MLLM breakdown → canvas storyboards → iterative diffusion drafts → final compositing
- Assumptions/dependencies: large-scale training and high-res video backbones; rights-managed datasets; pipeline standardization
- 3D and XR content generation: extending canvas to 3D latent volumes for precise geometry and camera motion planning (beyond 2D/temporal)
- Sectors: AR/VR, digital twins
- Tool/product: “3D Canvas Controller” for 3D diffusion/NeRF-like generators
- Assumptions/dependencies: mature 3D diffusion backbones; multimodal 3D MLLMs; high-quality 3D datasets
- Industrial inspection and digital twins: controlled synthetic data for fault detection in infrastructure (powerlines, pipelines) and manufacturing QA
- Sectors: energy, manufacturing
- Tool/product: “Synthetic Twin Data Generator” with attribute-locked anomalies
- Assumptions/dependencies: domain-specific physics, standards compliance, validation against real-world data
- Healthcare imaging augmentation: structured synthetic medical images and videos for training (e.g., segmentation, detection) with controlled attributes
- Sectors: healthcare
- Tool/product: “Regulated Synthetic Imaging Suite”
- Assumptions/dependencies: specialized backbones for medical modalities; rigorous clinical validation; regulatory approvals and guardrails
Academia
- Standardization of interfaces: a “latent canvas protocol” for MLLM-to-generator control, enabling cross-model interoperability and benchmarking
- Tool/product: open specification and reference implementations
- Assumptions/dependencies: community adoption; consensus across labs/vendors
- Multimodal curriculum learning: jointly training MLLMs and generators to write, revise, and execute spatial-temporal plans with self-supervised signals
- Workflow: plan → generate → critique → revise cycles
- Assumptions/dependencies: scalable datasets and training compute; reliable evaluators
Policy and Governance
- Provenance and watermarking at patch-level: embedding structured provenance metadata via canvas-guided edits for robust traceability
- Sectors: trust & safety, legal
- Tool/product: “Canvas-Embedded Watermarking” protocols
- Assumptions/dependencies: watermark research maturity; ecosystem buy-in; legal frameworks recognizing technical provenance signals
- Region-aware safety guardrails: dynamic, policy-driven constraints (e.g., disallow edits in sensitive regions) enforced at the canvas planning stage
- Tool/product: “Policy Compiler” mapping rules to canvas constraints
- Assumptions/dependencies: accurate region identification; robust policy translation; oversight mechanisms
Daily Life
- Accessible creative assistants: story-to-video and lesson-to-visual pipelines that maintain spatial-temporal coherence for education and hobbyists
- Sectors: education, creator tools
- Tool/product: “Lesson Visualizer” with step-by-step canvas plans
- Assumptions/dependencies: alignment of visuals with accurate pedagogical content; safety checks for misinformation
- Real-time mobile inference: hardware-accelerated canvas connectors enabling on-device high-quality edits and short video generation
- Tool/product: “Canvas-on-Chip” acceleration libraries
- Assumptions/dependencies: specialized kernels for linear attention/patch fusion; device memory constraints; model compression
Cross-Cutting (Tools and Workflows that may emerge)
- Canvas-driven version control: track and diff canvas plans across iterations for auditability and collaboration
- Unified evaluation stacks: standardized VLM/human-in-the-loop assessment for semantics, quality, and consistency across tasks (T2I/T2V/I2V/V2V)
- Multi-agent co-creation: planner (MLLM), executor (diffusion), and critic (VLM) loop with structured canvas handoffs
Notes on general feasibility:
- The framework is “lightweight” relative to end-to-end retraining, but still depends on quality pretrained MLLMs and diffusion backbones, GPU resources, and domain-aligned data.
- For specialized domains (e.g., medical, industrial), performance and safety require additional fine-tuning, validation, and governance.
- Reported gains (e.g., GEdit, ImgEdit, VBench, GPT-4o-based eval) suggest strong immediate utility for editing, layout control, and reference-guided generation; scaling to 3D or strict regulatory contexts is a longer-term effort.
Glossary
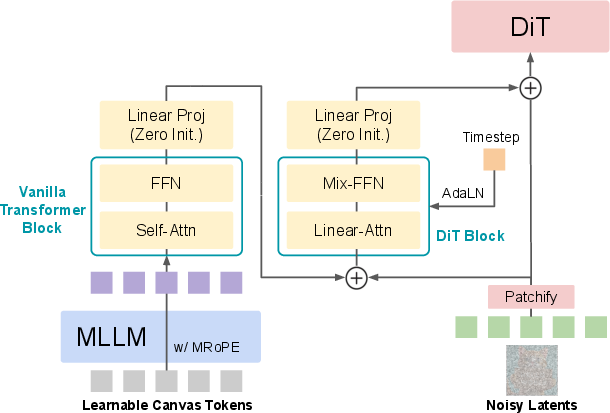
- Adaptive LayerNorm (AdaLN): A conditioning normalization that modulates layer behavior based on input or timestep to control generation dynamics. "The second DiT block adopts a ControlNet-style design, where the transformed canvas tokens and the noisy latents are first combined and then passed through a DiT block with Adaptive LayerNorm~\citep{perez2018film}."
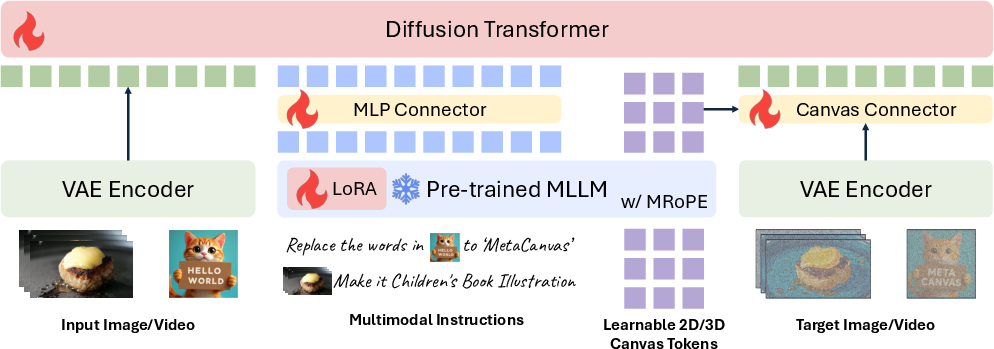
- Canvas Connector: A lightweight transformer-based module that aligns and injects canvas embeddings into diffusion latents for structured control. "The resulting canvas embeddings are then fused additively with the noisy latents through a lightweight Canvas Connector (see~\Cref{subsec:method_connector_design}), ensuring strong alignment between the MLLM-drafted canvas and the actual generation latents."
- Canvas tokens: Learnable multidimensional tokens appended to MLLM input that act as implicit spatial or spatiotemporal sketches guiding diffusion. "We append a set of learnable multidimensional canvas tokens to the MLLM input, which are processed using multimodal RoPE~\citep{Qwen2.5-VL}."
- ControlNet: An auxiliary control pathway for diffusion models enabling structured, externally guided conditioning signals. "The second DiT block adopts a ControlNet-style design, where the transformed canvas tokens and the noisy latents are first combined and then passed through a DiT block with Adaptive LayerNorm~\citep{perez2018film}."
- Cross-attention: An attention mechanism where diffusion latents attend to external condition tokens to integrate guidance. "Embeddings of the multimodal input tokens produced by the MLLM (i.e., context tokens for generation) are passed through a lightweight two-layer MLP connector and given to the DiT via cross-attention or self-attention, depending on the DiT’s architecture."
- Diffusion Transformer (DiT): A transformer-based diffusion backbone that operates on latent patches to synthesize images or videos. "The text embeddings produced by the MLLM are passed through a lightweight MLP connector and used as conditioning for the DiT."
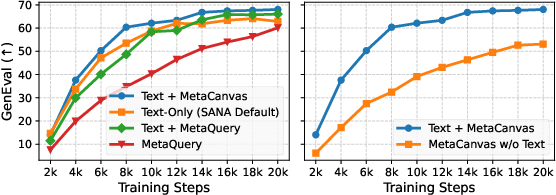
- GenEval: A text-to-image benchmark focused on attribute binding and spatial relations for compositional generation. "MetaCanvas converges faster and consistently outperforms other design variants on the GenEval~\citep{ghosh2023geneval} benchmark."
- In-context learning: The ability of models to adapt behavior from prompts/examples without parameter updates. "with improved performance in transferring LLM knowledge and in-context learning capabilities to reasoning-augmented image generation."
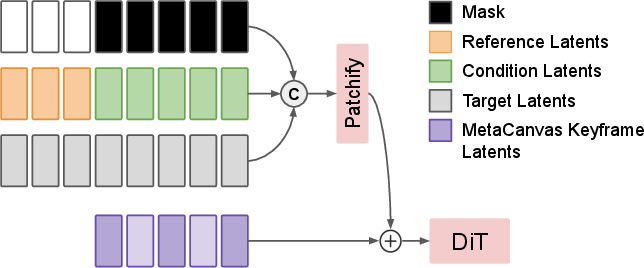
- Keyframe canvas tokens: Sparse temporal canvas tokens that are interpolated across frames to guide video synthesis efficiently. "we introduce learnable sparse keyframe canvas tokens that capture representative temporal information and are then linearly interpolated to the full latent-frame space before being incorporated into the DiT latents."
- Latent canvas: A learnable spatial or spatiotemporal layout in latent space for patch-wise generation planning. "enforcing explicit, patch-by-patch control over the generation process using a learnable latent canvas whose layout is planned by the (M)LLM."
- Latent diffusion model: A diffusion framework that operates in compressed latent space instead of pixel space for efficiency. "the text conditioning tokens $\bm{c}_{\text{text}$ in the latent diffusion model are replaced by the output tokens from the MLLM."
- Linear-Attn (Linear attention): An attention variant with linear complexity used to reduce memory and compute costs. "We adopt Linear-Attn and Mix-FFN design from~\citep{xie2024sana} to reduce memory usage."
- LoRA: Low-Rank Adaptation; an efficient fine-tuning method that injects trainable low-rank updates into pretrained weights. "To increase MLLM's model capacity, we apply LoRA with rank of 64 to the MLLM backbone."
- Mix-FFN: A feed-forward network variant combining multiple pathways/activations for efficient transformer processing. "We adopt Linear-Attn and Mix-FFN design from~\citep{xie2024sana} to reduce memory usage."
- MMDiT: A multimodal diffusion transformer backbone variant used for structured image/video generation. "three diffusion backbones (i.e., MMDiT and cross-attention)."
- Multimodal LLM (MLLM): An LLM capable of processing and reasoning over text, images, and videos. "multimodal LLMs (MLLMs) that use powerful LLMs as cognitive cores."
- Patch embedding: The layer that maps latents to patch tokens for transformer processing in diffusion backbones. "The resulting tensor is then passed through the patch embedding layer and combined with MetaCanvas keyframes after interpolation."
- Patchify layer: The operation/layer that partitions latents into patches before transformer blocks. "Next, we add the canvas tokens to the DiT noisy latents after the patchify layer."
- Reference frames: Provided frames used as fixed conditions during video generation/editing. "For video tasks, as shown in \Cref{fig:video_patch_embed_design}, we only add canvas tokens to the noisy latent frames while avoiding any modification of the reference frames."
- Rotary Positional Embedding (RoPE): A positional encoding method applying rotations to queries/keys; extended here to multimodal inputs. "processed using multimodal RoPE~\citep{Qwen2.5-VL}."
- Spatiotemporal latent space: Joint spatial-temporal latent representations underpinning structured planning across space and time. "lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators."
- Variational Autoencoder (VAE): A generative model used to encode/decode media into latents for diffusion-based synthesis. "while images or videos are encoded by the MLLM’s visual encoder and also by the diffusion model’s VAE encoder for both semantic and low-level details."
- VBench: A benchmark suite for evaluating video generation quality and semantics. "For T2V and I2V generation tasks, we use VBench~\citep{huang2023vbench, huang2024vbench++} as the evaluation benchmark."
- Visual instruction tuning: Fine-tuning that aligns MLLMs with perception encoders and instruction following for visual tasks. "enabled by visual instruction tuning~\citep{liu2023visual} that aligns them with perception encoders~\citep{Radford2021CLIP, siglip}."
- Zero-initialized linear projection: A stabilization technique where connector outputs start at zero to avoid perturbing the base model early in training. "The outputs of both blocks are followed by a zero-initialized linear projection layer, ensuring that at the beginning of training, the learnable canvas tokens have no influence on the DiT’s latent inputs."
- Zero-initialization strategy: Initializing control branches to produce null residuals so they do not affect latents at training start. "To stabilize training, we follow the zero-initialization strategy from~\citep{zhang2023controlnet}, ensuring the injected signals initially leave the diffusion model’s inputs unchanged."
Collections
Sign up for free to add this paper to one or more collections.