I Think, Therefore I Diffuse: Enabling Multimodal In-Context Reasoning in Diffusion Models
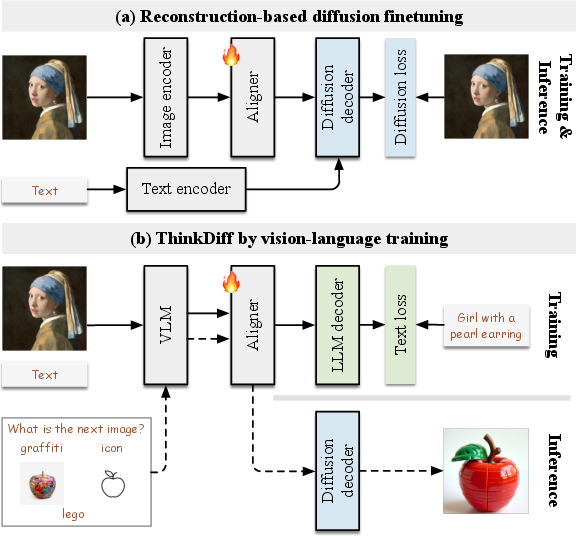
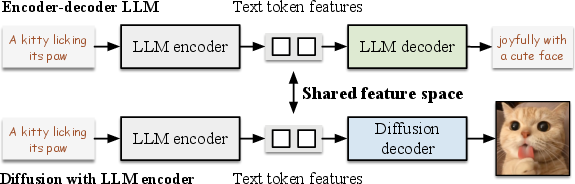
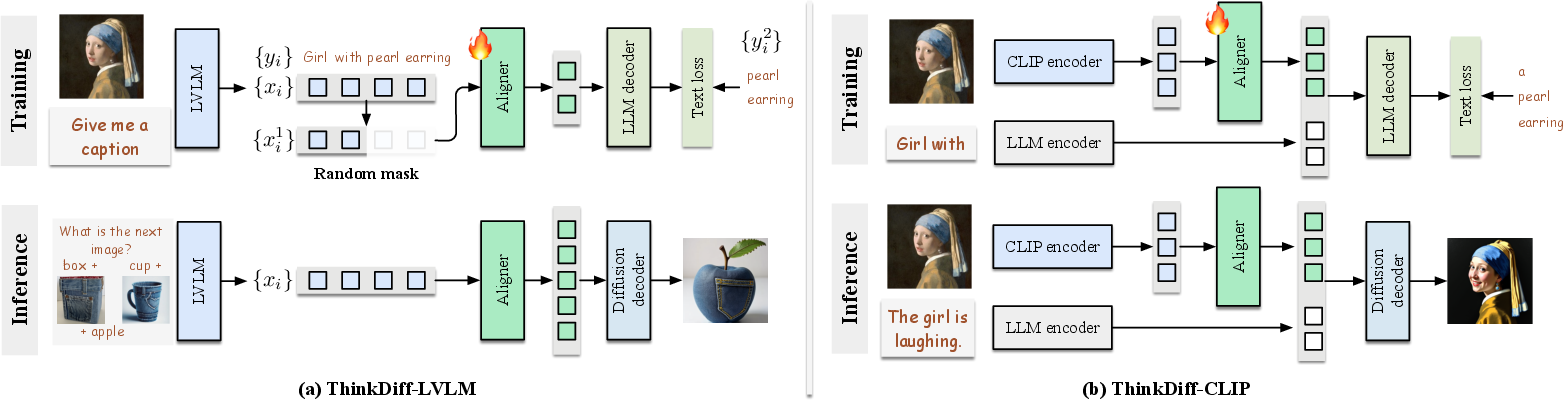
Abstract: This paper presents ThinkDiff, a novel alignment paradigm that empowers text-to-image diffusion models with multimodal in-context understanding and reasoning capabilities by integrating the strengths of vision-LLMs (VLMs). Existing multimodal diffusion finetuning methods largely focus on pixel-level reconstruction rather than in-context reasoning, and are constrained by the complexity and limited availability of reasoning-based datasets. ThinkDiff addresses these challenges by leveraging vision-language training as a proxy task, aligning VLMs with the decoder of an encoder-decoder LLM instead of a diffusion decoder. This proxy task builds on the observation that the $\textbf{LLM decoder}$ shares the same input feature space with $\textbf{diffusion decoders}$ that use the corresponding $\textbf{LLM encoder}$ for prompt embedding. As a result, aligning VLMs with diffusion decoders can be simplified through alignment with the LLM decoder. Without complex training and datasets, ThinkDiff effectively unleashes understanding, reasoning, and composing capabilities in diffusion models. Experiments demonstrate that ThinkDiff significantly improves accuracy from 19.2% to 46.3% on the challenging CoBSAT benchmark for multimodal in-context reasoning generation, with only 5 hours of training on 4 A100 GPUs. Additionally, ThinkDiff demonstrates exceptional performance in composing multiple images and texts into logically coherent images. Project page: https://mizhenxing.github.io/ThinkDiff.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.