Everything is Context: Agentic File System Abstraction for Context Engineering
Abstract: Generative AI (GenAI) has reshaped software system design by introducing foundation models as pre-trained subsystems that redefine architectures and operations. The emerging challenge is no longer model fine-tuning but context engineering-how systems capture, structure, and govern external knowledge, memory, tools, and human input to enable trustworthy reasoning. Existing practices such as prompt engineering, retrieval-augmented generation (RAG), and tool integration remain fragmented, producing transient artefacts that limit traceability and accountability. This paper proposes a file-system abstraction for context engineering, inspired by the Unix notion that 'everything is a file'. The abstraction offers a persistent, governed infrastructure for managing heterogeneous context artefacts through uniform mounting, metadata, and access control. Implemented within the open-source AIGNE framework, the architecture realises a verifiable context-engineering pipeline, comprising the Context Constructor, Loader, and Evaluator, that assembles, delivers, and validates context under token constraints. As GenAI becomes an active collaborator in decision support, humans play a central role as curators, verifiers, and co-reasoners. The proposed architecture establishes a reusable foundation for accountable and human-centred AI co-work, demonstrated through two exemplars: an agent with memory and an MCP-based GitHub assistant. The implementation within the AIGNE framework demonstrates how the architecture can be operationalised in developer and industrial settings, supporting verifiable, maintainable, and industry-ready GenAI systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI systems smarter and more trustworthy by giving them a better way to manage “context” — all the extra information an AI needs to think clearly, like notes, rules, tools, past conversations, and human advice. The authors suggest treating all this context like files in a computer’s file system (think of folders and documents), so AI and people can store, find, and use it in a consistent, trackable way.
What questions did the researchers ask?
They focused on simple, practical questions:
- How can we organize the information an AI needs so it doesn’t get lost or go stale?
- How do we choose the right pieces of information for a task when an AI can only “read” a limited amount at once?
- How can we make AI outputs traceable and verifiable, so people know where the information came from?
- How do we involve humans as editors and reviewers so AI decisions are safer and more accountable?
How did they try to solve it?
The file-system idea: “Everything is a file”
Imagine the AI’s world like a very tidy school binder:
- Each piece of knowledge, tool, or memory is a “file”.
- Files live in folders (like /context/memory/ or /tools/).
- The AI and humans can read and write files, search them, and keep track of changes.
- Every action is logged, so you can see who did what and why.
This makes different kinds of context (documents, databases, tools, notes, human feedback) look and behave the same, which keeps everything organized and easy to audit.
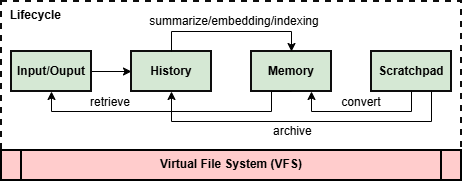
Three kinds of “memory”: History, Memory, Scratchpad
To help AI “remember” properly, they split memory into three layers:
- History: A permanent record of everything that happened (like a diary). It never gets deleted, and every entry has a timestamp and source.
- Memory: Structured summaries or facts the AI uses often (like study notes). It’s persistent but can be updated or refined.
- Scratchpad: A temporary workspace for the AI’s ongoing thinking during a task (like rough drafts or calculations). Useful stuff can be saved into Memory or History later.
This way, short-term thinking and long-term knowledge stay separate but connected.
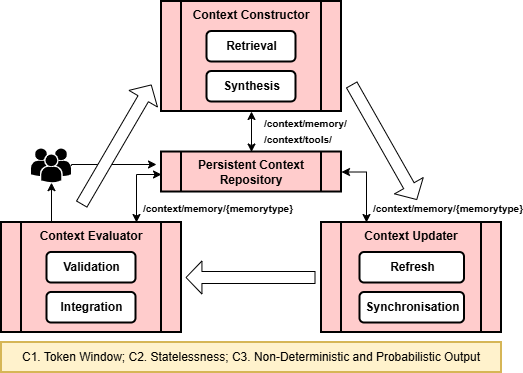
The context pipeline: Constructor, Updater, Evaluator
Because an AI can only “read” a limited amount at once (this limit is called the “token window” — think of it like the AI’s attention span or how many index cards it can hold), the paper builds a pipeline that manages what goes in and out:
- Context Constructor: Picks and compresses the most relevant files for the current task and makes a “context bundle” the AI can handle. It also respects privacy, permissions, and quality rules.
- Context Updater: Keeps the AI’s active context fresh during longer sessions by streaming in more info or replacing parts as needed, all within the token limit.
- Context Evaluator: Checks the AI’s results against sources to catch mistakes or contradictions. Good results get saved into Memory with clear metadata. When things look uncertain, humans are asked to review and correct.
Together, this pipeline keeps the AI’s “headspace” accurate, efficient, and accountable.
Building it for real: The AIGNE framework
They implemented all this in an open-source framework called AIGNE. Key pieces:
- AFS (Agentic File System): The “virtual folders” where context lives. It supports reading, writing, searching, and safe access.
- Plugins (“mounts”) can attach external tools or services (like GitHub) into the file system so the AI can use them like files.
- Two demos:
- An agent that remembers conversations across sessions.
- A GitHub assistant that uses MCP (Model Context Protocol) tools to search repos and list issues as if they were files.
What did they find and why is it important?
They showed that treating context like files:
- Makes AI systems more reliable: everything is stored, labeled, and linked to its source.
- Helps trace and verify decisions: you can see where info came from and how it was used.
- Supports human oversight: people can review, correct, and add knowledge directly.
- Scales better for industry: instead of random prompts and hacks, teams get a repeatable system they can maintain.
- Works across different tools and data types: databases, APIs, documents, and memory all look and feel the same.
The demos prove the idea is practical: an AI can remember and use tools in a clean, trackable way.
Why does this matter? What could it change?
- Trustworthy AI: With clear history and verification, AI decisions become more auditable and safer.
- Better teamwork: Humans act as curators, editors, and co-thinkers, reducing AI mistakes and bias.
- Stronger systems for companies: Easier to maintain, update, and reuse context across projects.
- Future growth: The authors plan to let agents “navigate” the file system on their own, organize their knowledge, and build smarter indexes — like turning the context space into a living, evolving knowledge fabric.
In short, this paper turns messy AI context into a tidy, rule-based system. That helps AI think better, humans stay in control, and teams build trustworthy AI that lasts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes a file-system abstraction and a context engineering pipeline implemented in AIGNE, but several aspects remain unspecified or unevaluated. The following list highlights concrete gaps and open questions that future research should address:
- Lack of empirical evaluation: no quantitative comparison against baselines (e.g., LangChain, AutoGen, MemGPT) on latency, cost, retrieval quality, and reasoning correctness.
- Scalability is uncharacterized: how the system performs with large context repositories (millions of artefacts), many concurrent agents, and high-throughput workloads.
- Access control and governance are underspecified: no formal RBAC/ABAC model, policy language, enforcement mechanisms, or multi-tenant isolation guarantees.
- Missing threat model and security hardening: risks from tool execution (sandbox escape), supply-chain dependencies, privilege escalation, and model-injected code are not analyzed.
- Provenance and verifiability detail is thin: no cryptographic audit logging, tamper-evident mechanisms, or trust models for audit trails and lineage integrity.
- Regulatory compliance is unresolved: immutable history conflicts with GDPR/CCPA “right to erasure”; PII detection, redaction, and deletion workflows are unspecified.
- Memory deduplication/consolidation is only noted as needed: no concrete algorithms, thresholds, or evaluation for controlling memory growth and redundancy.
- Context selection/compression strategies are undefined: how relevance is ranked, token budgets optimized (e.g., knapsack formulations), and trade-offs managed.
- Relevance metrics and decay functions are not specified: no formalization of how recency, provenance, confidence, or usage signals influence selection priorities.
- Consistency semantics for mounted external resources are unclear: caching policies, staleness management, eventual consistency, retries, and fallback behavior.
- Concurrency and conflict resolution for multi-agent writes to shared memory are missing: locking, CRDTs, merge policies, and contention handling are not described.
- Handling contradictions and drift in memory is unaddressed: reconciliation workflows, consensus protocols among agents, and human override procedures need specification.
- Metadata schema is not formalized: standard fields, ontologies, validation rules, and interoperability standards across mounts and tools are not defined.
- Mapping non-hierarchical structures to paths lacks guidance: how knowledge graphs, APIs, and streaming feeds should be represented; limits of “everything is a file.”
- Token-window streaming strategies are unquantified: batch sizing, scheduling, backpressure, and their effects on latency and reasoning quality.
- Cost-aware context engineering is absent: policies for token budget control, rate-limit adaptation, and cloud billing optimization under varying workloads.
- Human-in-the-loop design is underdeveloped: UI/UX for curation/verification, workload estimates, annotation quality controls, and inter-rater reliability protocols.
- Hallucination detection and factuality checks are not evaluated: methods, thresholds, metrics (precision/recall), and error-handling paths are unspecified.
- Reproducibility under model non-determinism is unclear: deterministic decoding policies, seed control, and replay guarantees for audits and tests.
- DevOps/dataops integration needs detail: CI/CD for context artefacts, versioning workflows, rollback strategies, and migration paths from existing stacks.
- Portability beyond AIGNE is not demonstrated: standardized APIs, adapter patterns, and compatibility guidance for other ecosystems and vendors.
- Distributed deployment concerns remain open: networked file systems, partitioning/sharding, synchronization, failure recovery, and geo-replication strategies.
- Reliability and observability are unaddressed: SLAs, failure modes, monitoring metrics, alerts, and tracing for the context pipeline components.
- Domain-specific validation is missing: case studies in regulated sectors (e.g., healthcare, finance) to test governance, ethics, and human-centered workflows.
- Formal guarantees are absent: correctness or optimality bounds for selection/compression, complexity analysis, and conditions for verifiable reasoning.
- Benchmarking resources are lacking: public datasets, tasks, and standardized metrics to enable comparative studies of context engineering methods.
Practical Applications
Immediate Applications
Below are deployable use cases that leverage the paper’s “Agentic File System” (AFS) abstraction and the Context Engineering Pipeline (Constructor, Updater, Evaluator) as implemented in the open-source AIGNE framework.
- Software engineering and LLMOps
- Auditable agent workflows for developers
- Use AFS to mount code, docs, tools (MCP servers), and memory as a unified namespace; generate a context manifest per task to trace which files, tools, and memory were injected into the model’s token window.
- Tools/products/workflows: “ContextOps” step in CI/CD; context manifest stored alongside code; replayable agent sessions; model-agnostic context loaders; evaluation logs for regression testing.
- Dependencies/assumptions: Adoption of AIGNE or equivalent AFS; proper IAM/ACLs for mounted repos; stable LLM APIs; developer buy-in for context manifest reviews.
- GitHub developer assistant via MCP
- Mount the official GitHub MCP server into AFS to search repositories, triage issues, draft PRs, and perform code-aware operations as file-like actions.
- Sector: Software/DevTools.
- Dependencies/assumptions: GitHub PATs/permissions; sandboxed execution; governance to prevent destructive actions (e.g., branch protection).
- Tool composition without heavy prompt boilerplate
- Mount REST/OpenAPI/GraphQL services, databases, and vector stores as AFS modules; expose them as files/actions that agents can discover and execute with typed schemas instead of long tool descriptions in prompts.
- Sector: Enterprise IT, Platform engineering.
- Dependencies/assumptions: Declarative resolvers for backends; metadata quality; schema alignment and versioning.
- Enterprise knowledge assistants with governance
- Verifiable RAG and memory with provenance
- Persist history, memory, and scratchpads via AFS; Constructor selects and compresses relevant context, Updater streams under token budgets, Evaluator writes back validated facts with lineage for audit.
- Sectors: Knowledge management, Customer support, IT service desks.
- Dependencies/assumptions: Metadata tagging (recency, source, access); vector DB / full-text plugin; policy-compliant retention and aging.
- Compliance-grade context logging
- Record exactly what context was visible at decision time (inputs, model version, manifest, outputs, overrides) for audit and e-discovery.
- Sectors: Finance (compliance documentation), Government, Legal operations.
- Dependencies/assumptions: Retention policies; secure storage; legal review of admissibility; PII/PHI handling where applicable.
- Human-in-the-loop evaluation and curation
- Curated knowledge bases with human overrides
- Evaluator routes low-confidence or contradictory outputs for human review; accepted annotations are stored as first-class context elements with provenance.
- Sectors: Regulated industries, Corporate policy teams, Editorial teams.
- Dependencies/assumptions: Review tooling/UI; clear escalation thresholds; workforce availability; training for consistent annotation.
- Persistent-memory conversational agents
- Stateful chatbots that “remember” safely
- Use AFS-backed memories (episodic, fact, user profiles) to sustain multi-session context while enforcing ACLs and token budgets via the Constructor/Updater.
- Sectors: Customer success, Internal help desks, Retail.
- Dependencies/assumptions: Consent and privacy safeguards; deduplication/consolidation policies to combat memory bloat and “context rot.”
- Education and training
- Personal tutors with auditable learning records
- Store student progress and scratchpads in AFS; selectively load summaries for sessions; enable educators to inspect provenance (what was shown, when, and why).
- Sector: Education/EdTech.
- Dependencies/assumptions: FERPA/GDPR compliance; parental consent; exportability and data portability.
- Healthcare (non-diagnostic knowledge operations)
- Policy/procedure assistants with provenance
- Mount hospital SOPs and non-PHI materials; generate verified summaries and checklists; log context used for each guidance session.
- Sector: Healthcare operations.
- Dependencies/assumptions: Strict exclusion of PHI unless compliant; approvals for deployment; staff training; bounded scope (no clinical decision making).
- Research and academia
- Reproducible LLM experiments
- Persist prompts, contexts, manifests, and outputs; replay to compare model versions and sampling settings; shareable, verifiable experiment bundles.
- Sector: Academia/Industrial research.
- Dependencies/assumptions: Storage quotas; model version pinning; dataset licensing; ethics and IRB alignment where applicable.
Long-Term Applications
These opportunities require further research, scaling, standardization, or sector-specific validation and certification.
- Agentic operating system for knowledge and tools
- Self-organizing agents within a “living” knowledge fabric
- Agents autonomously browse AFS mounts, construct indices, restructure context graphs, and evolve memory under governance—moving toward the LLM-as-OS vision.
- Sectors: Enterprise IT, Knowledge management, Software platforms.
- Dependencies/assumptions: Robust guardrails and policy engines; reliable model planning; stronger verification of agent-led refactoring.
- Cross-agent, cross-organization context exchange
- Federated, provenance-preserving context sharing
- AFS-like manifests and lineage standards enable supply-chain and inter-agency collaboration with fine-grained access controls and auditability across boundaries.
- Sectors: Public sector, Manufacturing, Healthcare networks, Finance.
- Dependencies/assumptions: Interop standards (MCP, schema conventions); legal frameworks for data sharing; differential privacy or secure enclaves.
- Sector-certified decision support with full traceability
- Healthcare clinical support with validated pipelines
- Integrate EHRs as mounted resources; certify Constructor/Updater/Evaluator workflows; maintain tamper-evident lineage for clinical audits.
- Sector: Healthcare.
- Dependencies/assumptions: Regulatory approvals (FDA/EMA where relevant); clinical trials; PHI security; model robustness and bias controls.
- Risk and compliance assistants accepted by regulators
- Regulator-friendly audit trails detailing context windows and decision justifications; standardized reporting based on context manifests.
- Sector: Finance/Insurance.
- Dependencies/assumptions: Supervisory guidance acceptance; red-teaming and stress-testing; data retention and right-to-be-forgotten mechanisms.
- Robotics and IoT as file-like resources
- Sensor/actuator mounting with verifiable action logs
- Expose robot sensors and control APIs as AFS nodes; agents reason over telemetry and invoke safe actions as typed functions; Evaluator records outcomes for safety audits.
- Sectors: Robotics, Industrial automation, Logistics.
- Dependencies/assumptions: Real-time constraints; certified safety layers; deterministic fallbacks; latency-aware context streaming.
- Energy and critical infrastructure operations
- Context-aware monitoring and response with guardrails
- Mount grid telemetry, forecasts, and procedures; agents propose actions; Evaluator enforces policy and human approval before execution.
- Sector: Energy/Utilities.
- Dependencies/assumptions: OT/IT integration; safety certification; incident response processes; fail-safe designs.
- Privacy-preserving, policy-driven context governance
- Dynamic masking and policy enforcement at context load time
- Constructor enforces organizational and legal policies (e.g., purpose limitation, role-based access) before data enters the token window.
- Sectors: All regulated industries.
- Dependencies/assumptions: Machine-readable policy engines (OPA-like); identity propagation; robust metadata quality and lineage integrity.
- Automated context quality management at scale
- Context rot detection, deduplication, and consolidation
- Background agents detect stale memories, merge redundant facts, and re-summarize histories using Evaluator feedback loops.
- Sectors: Enterprise knowledge management.
- Dependencies/assumptions: Reliable semantic similarity/dedup metrics; safe summarization with minimal information loss; cost controls.
- Products and ecosystems
- ContextOps platforms and marketplaces
- AFS-as-a-Service for mounting enterprise systems, MCP tool marketplaces, policy packs, and observability dashboards that monitor context health and provenance.
- Sectors: Software/SaaS, Platform engineering.
- Dependencies/assumptions: Vendor-neutral standards; plugin security vetting; long-term API stability.
- Education: lifelong learning records
- Portable learner memory and competency maps
- Institution-agnostic, provenance-rich education records mounted into tutors and career guidance agents.
- Sector: Education/Workforce development.
- Dependencies/assumptions: Inter-institution data standards; consent and portability rights; bias and fairness oversight.
- Legal and evidence workflows
- Court-admissible logs of AI-assisted research and drafting
- Immutable lineage of sources and context used in legal research and filings; reproducible workflows for discovery.
- Sector: Legal services.
- Dependencies/assumptions: Jurisdictional acceptance; chain-of-custody guarantees; secure timestamping/notarization (e.g., cryptographic proofs).
Notes on Feasibility and Dependencies
- Model and token constraints: Applications depend on effective selection/compression strategies to fit LLM token windows; large-context models reduce but do not remove this constraint.
- Governance and security: Fine-grained ACLs, sandboxed tool execution, and policy enforcement are prerequisites, especially in regulated sectors.
- Metadata quality: The pipeline’s effectiveness hinges on accurate, consistent metadata (provenance, timestamps, ownership, confidence).
- Interoperability standards: Broader adoption benefits from common schemas for manifests, lineage, and MCP-like tool descriptors.
- Human-in-the-loop capacity: Many high-stakes uses require scalable review workflows and trained reviewers.
- Cost and performance: Persistent logging, embeddings, and streaming impose compute and storage costs; observability and cost controls are needed.
Glossary
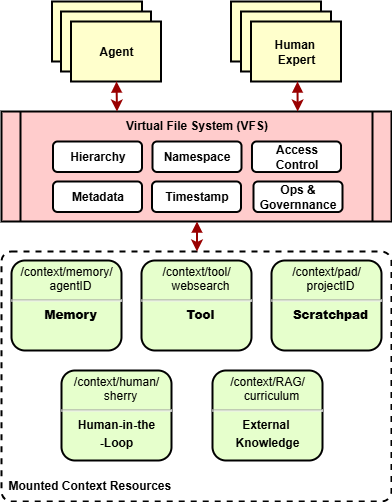
- Agentic File System (AFS): A virtual, mountable file-system layer that exposes heterogeneous context resources as addressable nodes for agents. "In the AIGNE framework, the AFS (Agentic File System) module serves as the primary file system interface."
- Agentic systems: AI systems in which autonomous agents perform tasks using tools, memory, and contextual reasoning. "Context engineering is emerging as a central concern in software architecture for Generative AI (GenAI) and Agentic systems"
- AIOS: An LLM Agent Operating System paradigm and project that treats the LLM like an OS kernel managing agents, memory, and tools. "AIOS project operationalises this paradigm through OS-like primitives for scheduling, resource allocation, and memory management for multi-agent systems"
- AIGNE framework: An open-source framework implementing the proposed file-system abstraction and context pipeline for GenAI agents. "Implemented within the open-source AIGNE framework, the architecture realises a verifiable context-engineering pipeline"
- Context Constructor: The pipeline component that selects, prioritizes, and compresses relevant context for the model’s active window. "The Constructor defines how relevant context is selected, prioritized, and compressed from the persistent context repository"
- Context engineering: The discipline of capturing, structuring, and governing knowledge, memory, tools, and human input to ground AI reasoning. "Context engineering is emerging as a central concern in software architecture for Generative AI (GenAI) and Agentic systems"
- Context Evaluator: The pipeline component that verifies outputs, updates long-term memory, and enforces governance and provenance. "The Context Evaluator closes the loop by verifying model outputs, updating the persistent context repository"
- Context rot: The degradation or staleness of long-term AI memory over time, undermining reliability. "raising challenges of context rot and knowledge drift in industrial-setting"
- Context Updater: The pipeline component that synchronizes and refreshes the bounded context within the model’s token window. "The Context Updater manages the transfer and refresh of constructed context into the bounded reasoning space of the GenAI model."
- Context window: The short-term working memory of an LLM, i.e., the tokens it can attend to during a single inference. "MemGPT introduces a memory hierarchy that coordinates both short-term (context window) and long-term (external storage) memory."
- Episodic memory: Medium-term, session-bounded summaries or case histories used to sustain coherence across tasks. "such as episodic memory (task-bounded summaries) and fact memory (persistent atomic facts)."
- Experiential Memory: Long-term records of observation–action trajectories supporting learning from experience. "Experiential Memory & Long-term, cross-task & Observation-action trajectories & Structured logs or database"
- Fact Memory: Long-term, fine-grained storage of atomic factual statements for reliable recall. "such as episodic memory (task-bounded summaries) and fact memory (persistent atomic facts)."
- Foundation models: Large pretrained models that act as subsystems with bounded token windows shaping system design. "Foundation models act as pre-trained subsystems with limited token windows that constrain reasoning."
- Knowledge drift: Gradual divergence between stored knowledge and current reality, leading to outdated or misleading context. "raising challenges of context rot and knowledge drift in industrial-setting"
- Knowledge Graph (KG): Structured graph representations of entities and relations used for long-term memory and retrieval. "Knowledge Graph (KG) based solutions, like Zep/Graphiti and Cognee"
- LLM-as-OS: A paradigm conceptualizing the LLM as an operating-system kernel orchestrating memory, tools, and agents. "operating-system paradigm for LLMs (LLM-as-OS), which conceptualises the LLM as a kernel orchestrating context, memory, tools, and agents."
- MemGPT: A system that augments LLMs with layered memory to emulate OS-like behavior. "MemGPT introduces a memory hierarchy that coordinates both short-term (context window) and long-term (external storage) memory."
- Memory hierarchy: A coordinated structure of short-term and long-term memory layers enabling scalable reasoning. "MemGPT introduces a memory hierarchy that coordinates both short-term (context window) and long-term (external storage) memory."
- Model Context Protocol (MCP): A protocol for integrating external tools and services as context-accessible modules. "AIGNE provides native integration with multiple mainstream LLMs (e.g., OpenAI, Gemini, Claude, DeepSeek, Ollama) and external services via the built-in Model Context Protocol (MCP)"
- Persistent Context Repository: The governed store unifying history, memory, and scratchpads across sessions. "The Persistent Context Repository enabled by the File System fulfills this role."
- Prompt engineering: The practice of crafting instructions for LLMs; contrasted with broader context engineering. "In contrast to prompt engineering, which focuses on crafting individual instructions, context engineering focuses on the entire information lifecycle"
- Prompt schema: A structured input format specifying how curated context is organized for model inference. "before being aligned with the modelâs prompt schema, a structured input format specifying how context elements are organized for inference."
- Provenance: Metadata about the origin and lineage of context and outputs supporting traceability. "so that reasoning by LLMs and agents is grounded in the right information, constraints, and provenance."
- Retrieval-Augmented Generation (RAG): A technique that injects retrieved external knowledge into LLM prompts for grounded outputs. "Existing practices such as prompt engineering, retrieval-augmented generation (RAG), and tool integration remain fragmented"
- Scratchpad: A temporary workspace for intermediate reasoning artefacts during a task. "Scratchpads serve as temporary workspaces where agents compose intermediate hypotheses, computations, or drafts during reasoning."
- Self-attention mechanism: The transformer operation whose quadratic complexity scales with input length. "due to the quadratic complexity of the self-attention mechanism"
- Semantic indexing: Organizing and accessing data based on meaning rather than exact keywords. "an LLM-based semantic file system that enables natural-language–driven file operations and semantic indexing"
- Statelessness: The property of LLMs not retaining memory across sessions without external storage. "GenAI models are inherently stateless, which do not retain conversational history or memory across sessions."
- Token window: The hard limit on the number of tokens a model can process in a single pass. "The token window of GenAI model introduces a hard architectural constraint"
- Vector databases: Stores optimized for embedding vectors and similarity search used in semantic retrieval. "new backends, such as full-text indexers, vector databases, or knowledge graphs"
- Verifiability: The ability to audit and confirm the correctness and lineage of context and actions. "support verifiability by allowing changes, reasoning steps, and tool invocations to be audited retrospectively."
Collections
Sign up for free to add this paper to one or more collections.

