Matrix: Peer-to-Peer Multi-Agent Synthetic Data Generation Framework
Abstract: Synthetic data has become increasingly important for training LLMs, especially when real data is scarce, expensive, or privacy-sensitive. Many such generation tasks require coordinated multi-agent workflows, where specialized agents collaborate to produce data that is higher quality, more diverse, and structurally richer. However, existing frameworks for multi-agent synthesis often depend on a centralized orchestrator, creating scalability bottlenecks, or are hardcoded for specific domains, limiting flexibility. We present \textbf{Matrix}, a decentralized framework that represents both control and data flow as serialized messages passed through distributed queues. This peer-to-peer design eliminates the central orchestrator. Each task progresses independently through lightweight agents, while compute-intensive operations, such as LLM inference or containerized environments, are handled by distributed services. Built on Ray, Matrix scales to tens of thousands of concurrent agentic workflows and provides a modular, configurable design that enables easy adaptation to a wide range of data generation workflows. We evaluate Matrix across diverse synthesis scenarios, such as multi-agent collaborative dialogue, web-based reasoning data extraction, and tool-use trajectory generation in customer service environments. In all cases, Matrix achieves $2$--$15\times$ higher data generation throughput under identical hardware resources, without compromising output quality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Matrix, a new system that helps many AI “helpers” (called agents) work together to create synthetic data—fake but useful training examples—quickly and at very large scale. Instead of having one central “boss” computer tell everyone what to do, Matrix lets the agents pass messages directly to each other, like teammates passing a clipboard around. This makes the whole process faster, more flexible, and easier to grow.
What questions were the authors trying to answer?
The authors focused on three simple questions:
- How can we generate lots of high-quality training data for AI models without relying on slow, centralized control?
- Can multiple specialized agents work together smoothly without a single bottleneck?
- Will this approach be faster while keeping the same output quality?
How did they build it?
The authors designed Matrix around a few key ideas. Here’s what they mean in everyday terms.
The big idea: peer-to-peer teamwork
- “Peer-to-peer” means there’s no single boss coordinating everything. Each agent knows its role and can receive a task, work on it, and pass it to the next agent.
- Think of a relay team: each runner does a part and hands off the baton. The baton here is a “message” that carries both the data and what to do next.
How a task moves through the system
- Each task has a small “orchestrator” object—like a checklist with notes—that travels between agents.
- An agent reads the checklist, does its part (for example: write a response, check a fact, run a tool), updates the checklist, and sends it to the next agent.
- Because agents don’t keep their own long-term memory about tasks (they’re “stateless”), the system can easily add more agents when things get busy.
Key terms made simple:
- Agent: a small AI worker that does a specific job (e.g., generate text, verify answers).
- Orchestrator: a traveling checklist that stores the task’s progress and who should act next.
Smart use of computers and tools
- Heavy-lifting jobs like running LLMs or external tools (in containers) are handled by separate, distributed services that can scale up independently.
- Matrix uses open-source tools like Ray (for running lots of tasks), vLLM/SGLang (for running AI models), and Apptainer (for isolated tool environments).
Going row-by-row, not batch-by-batch
- Many systems process tasks in big batches, which can cause delays when a few hard tasks hold up the rest.
- Matrix moves each task forward as soon as it’s ready—like a grocery store with many single lines instead of one long line. This “row-level” scheduling keeps computers busy and reduces waiting.
Reducing heavy messages
- Conversations between agents can get big (lots of text). Sending all of that around wastes network bandwidth.
- Matrix keeps only small pointers in the traveling checklist and stores large content in a shared “object store.” It’s like keeping heavy photo albums on a shelf and passing around a note that says where to find them.
What did they find, and why does it matter?
The team tested Matrix on three different, realistic data-generation tasks and compared it to strong baselines. In each case, Matrix was much faster while keeping similar quality.
Here are the highlights:
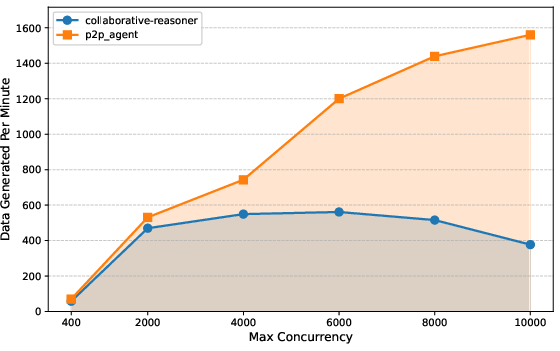
- Collaborative dialogue data (two agents reasoning together): Matrix was about 6.8× faster in token generation while keeping the same correctness level.
- Building a reasoning dataset from web pages (NaturalReasoning): Matrix was about 2.1× faster than a batch-based system, thanks to its “row-by-row” scheduling.
- Tool-use conversations in customer support scenarios (Tau2-bench): Matrix was about 15.4× faster, and the final quality (measured by a reward score) stayed just as good.
Also, a networking optimization (offloading large messages) reduced network load by around 20%, which helps the system scale smoothly.
Why this matters:
- Faster data generation means we can train AI models more cheaply and quickly.
- Keeping quality steady means speed doesn’t come at the cost of bad data.
- The system works across very different tasks, showing it’s flexible.
What could this change in the future?
- Better, cheaper training data: When real data is sensitive, expensive, or limited, synthetic data helps. Matrix makes creating that data much faster.
- More flexible AI pipelines: Teams can plug in new agents, tools, or models without rebuilding everything.
- Open-source and community-friendly: It’s built on open tools (like Ray and vLLM) and is designed to be shared, so researchers and developers can adopt and improve it.
- Ready for bigger, richer data: The same ideas should work for multi-modal data too (like text plus images or audio), and for “always learning” systems that keep generating and refining their own training data.
In short, Matrix shows that letting many small AI workers coordinate directly—without a central bottleneck—can make synthetic data generation both fast and reliable at massive scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper presents Matrix as a scalable peer-to-peer agentic framework and reports throughput gains across several case studies. The following items summarize what remains missing, uncertain, or unexplored, focusing on actionable directions for future research:
- Quantify end-to-end data quality beyond throughput: conduct systematic human and automatic evaluations (accuracy, validity, diversity, bias) for outputs across all case studies, not just agreement correctness or average reward.
- Demonstrate downstream impact on model performance: fine-tune LLMs on Matrix-generated datasets and report controlled improvements on held-out benchmarks vs. strong baselines, including ablations on data size and composition.
- Ensure reproducibility and determinism: define seeding, deterministic scheduling, and log replay mechanisms so random agent selection and asynchronous execution yield reproducible runs.
- Strengthen fault tolerance semantics: specify and evaluate exactly-once vs. at-least-once delivery, orchestrator checkpointing, idempotent tool calls, and recovery from partial progress or agent/container crashes.
- Implement adaptive backpressure and concurrency control: move beyond static max_concurrency to dynamic policies that auto-tune concurrency per agent based on queue depths, latencies, and GPU utilization.
- Improve load balancing policies: replace random agent instance selection with queue-aware or latency-aware routing, and evaluate its impact on hotspots, tail latency, and throughput.
- Clarify message ordering and consistency: define per-task FIFO guarantees, handling of out-of-order updates, and race conditions; validate that Ray RPC plus the current design prevents state corruption under high concurrency.
- Provide security and privacy guarantees: analyze risks of message injection, cross-tenant leakage, and tool misuse; add authentication, authorization, encryption (TLS for gRPC/HTTP), and audit logs for agent-to-agent and service calls.
- Report cost and energy efficiency: measure $tokens/\$ $, energy per token, and CPU/GPU utilization to substantiate scalability claims with cost and sustainability metrics.
- Characterize network and memory ceilings: quantify head-node and per-node network saturation points, object-store memory footprints, eviction/GC behavior, and the latency impacts of message offloading under extreme loads.
- Establish scalability bounds: demonstrate and explain limits beyond the reported 12.4k–14k concurrent tasks (e.g., 50k+), including failure modes and resource bottlenecks on heterogeneous clusters (A100/H100 mix).
- Address stateful agent/container failure and migration: evaluate consistency when containers restart, define state migration or rehydration policies, and measure the penalty of container-level isolation vs. in-process tools.
- Explore richer orchestration policies: go beyond SequentialOrchestrator to data-dependent branching, graph-based control, and learned/RL-based orchestrators; measure how these impact utilization and data quality.
- Analyze interaction with LLM continuous batching: study how row-level scheduling aligns or conflicts with token-level batching in vLLM/SGLang, and quantify effects on latency, throughput, and prompt caching.
- Validate NaturalReasoning curation quality: report classifier precision/recall, question correctness, reasoning validity, deduplication, domain coverage, and contamination with downstream evaluation sets.
- Ensure fairness in baseline comparisons: standardize concurrency, resource allocation, and tuning across baselines (e.g., Coral, Tau2-agent) and include comparisons against general frameworks (Autogen, LangGraph, CrewAI) at scale.
- Expand Tau2-bench evaluation: report full reward distributions, failure rates, trajectory lengths, tool/API error rates, and robustness to API outages; verify idempotency and transactional correctness of tool operations.
- Provide latency and tail behavior: report per-agent, per-service latency distributions and tail metrics under load; define SLOs and show compliance with alerts/mitigations.
- Substantiate multi-modal readiness: run image/audio/video agents, quantify bandwidth/storage demands, and evaluate message offloading and orchestration under multi-modal payloads.
- Test multi-region, cross-AZ deployments: evaluate gRPC and object-store behavior across WAN links, consistency under network partitions, and failover strategies.
- Address data governance and safety: detail licensing, PII handling, toxicity/safety filters for web-derived data, and red-teaming results; document compliance practices for synthetic data pipelines.
- Implement autoscaling policies: integrate with Ray autoscaler/SLURM to scale agents, containers, and LLM replicas on demand; validate stability, cost savings, and convergence of scaling decisions.
- Enhance monitoring and tracing: define standardized KPIs (queue depth, retries, drops, per-hop latency), end-to-end tracing across agent hops, and actionable alerts for bottlenecks or degraded quality.
- Improve developer ergonomics: provide schema validation, configuration linting, static analysis for orchestrator correctness, and debugging tools for message flows and state transitions.
- Standardize benchmarking: release unified workloads/scripts/configs that enable apples-to-apples system-level comparisons (throughput, quality, cost, latency) for multi-agent synthesis frameworks.
- Manage object-store resource risks: study fragmentation, spill-to-disk, eviction impacts on latency/quality, and implement proactive cleanup or compression of large conversation payloads.
- Harden container security: evaluate sandboxing in Apptainer, apply least-privilege policies, and verify protection against malicious tool calls or environment escape.
- Measure quality-concurrency trade-offs: assess whether very high concurrency degrades LLM behavior (e.g., context truncation, retrieval delays) and define safe operating points that preserve output quality.
Practical Applications
Immediate Applications
The following items can be deployed now, based on the framework, results, and artifacts described in the paper. Each bullet specifies sectors, potential tools/products/workflows, and practical assumptions or dependencies.
- High-throughput synthetic data factory for LLM post-training
- Sectors: software, education, general AI
- Tools/workflows: Matrix + Ray Serve + vLLM/SGLang; Hydra-configured agent teams; Coral-style self-collaboration and NaturalReasoning-style curation
- What to do: Stand up a shared “synthetic data factory” to generate instruction, dialogue, and reasoning datasets at 2–15× higher throughput without quality loss; use row-level scheduling and peer-to-peer orchestration to avoid centralized bottlenecks
- Assumptions/dependencies: Access to GPUs/LLM replicas; well-formed Hydra configs; prompt templates; observability (Grafana); content licenses for any web data
- Tool-use trajectory farms for enterprise assistants and automation
- Sectors: telecom, retail/e-commerce, finance (customer support, troubleshooting), IT operations
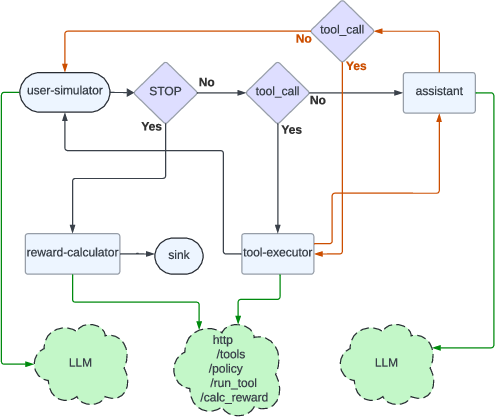
- Tools/workflows: Tau2-bench agents (assistant, user-simulator, tool-executor, reward-calculator) deployed via Apptainer; gRPC-based LLM services; validated reward functions
- What to do: Generate large volumes of verifiable agent trajectories for tool-use and reasoning to fine-tune or evaluate assistants; achieve 15× token throughput over single-node baselines; automatically filter by reward
- Assumptions/dependencies: Containerized and versioned APIs; deterministic environment state; reward calculators; load-balanced LLM replicas; network bandwidth management (message offloading)
- Privacy-preserving synthetic conversation/data generation in regulated domains
- Sectors: healthcare (PHI-safe dialogues), finance (KYC/AML simulations), public-sector services
- Tools/workflows: P2P agents replacing human data pipelines; domain-specific tool executors with audits; reward validators to ensure compliance and quality
- What to do: Replace or augment sensitive data collection with synthetic equivalents to reduce privacy risk and cost; create policy-compliant datasets for training and evaluation
- Assumptions/dependencies: Domain-specific tools and rule engines; governance reviews; synthetic-to-real performance validation; provenance logging
- Web-scale reasoning dataset curation and enrichment
- Sectors: search/QA platforms, education content providers, academic benchmarking
- Tools/workflows: Filter/Score/Question agents (3B classifier → 70B scorer/generator); batched ingestion of licensed web corpora (e.g., DCLM); row-level scheduling
- What to do: Scale filtering and generation to millions of items; rapidly create diverse, difficult reasoning sets for improved sample efficiency
- Assumptions/dependencies: Data licensing; robust English/document filters; prompt stability across domains; GPU capacity planning
- Migration path from centralized agent orchestrators to peer-to-peer message-driven scheduling
- Sectors: enterprise ML ops, agentic tools vendors
- Tools/workflows: Serialize per-task orchestrator state; replace single control loop with Matrix’s team-of-actors; enable row-level progress and continuous batching
- What to do: Refactor legacy orchestration to reduce idle time and CPU/GPU underuse; elastically scale agent instances and services
- Assumptions/dependencies: Ability to serialize workflow state; RPC compatibility; minimal code changes to agent logic; existing model-serving endpoints
- Observability, tuning, and SRE workflows for agentic data generation
- Sectors: ML ops, cloud service providers
- Tools/workflows: Grafana dashboards for queue length, async tasks, token throughput; concurrency/semaphore tuning; offloading thresholds
- What to do: Put in place real-time monitoring and systematic tuning recipes to maintain high utilization; identify bottlenecks (I/O vs inference vs control)
- Assumptions/dependencies: Metric ingestion; reliable cluster management (SLURM/Ray); alerting for inference replica health
- Message offloading to object stores to reduce network pressure
- Sectors: large-scale generation and evaluation pipelines
- Tools/workflows: Ray Object Store integration; configurable content-size thresholds; immutable object lifecycle for orchestrator histories
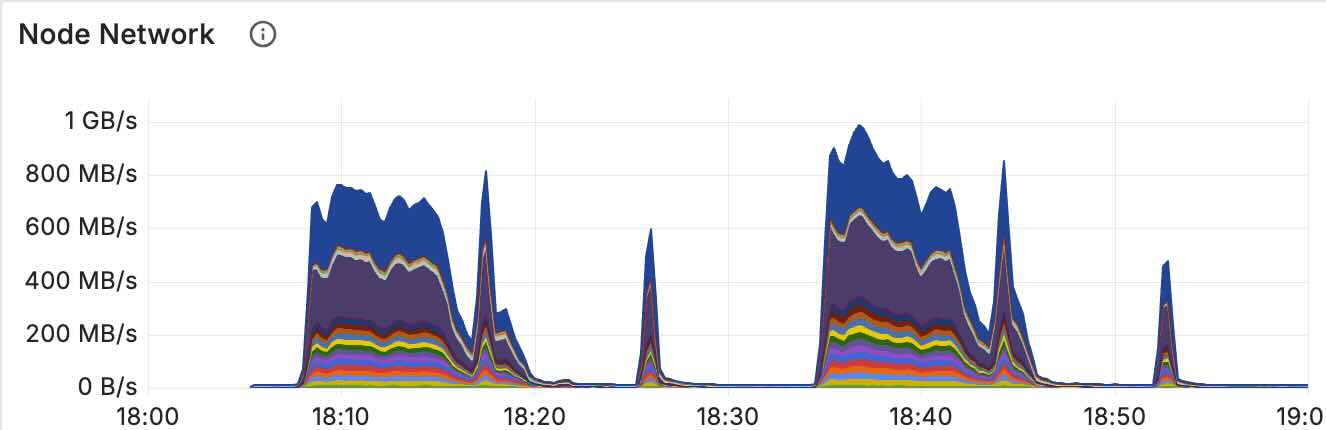
- What to do: Store large conversation payloads out-of-band to cut cluster bandwidth (≈20% reduction observed); keep orchestrators compact and responsive
- Assumptions/dependencies: Stable object store; cleanup of history-related objects on task completion; threshold tuning per workload
- Academic replication and extension of agentic benchmarks at scale
- Sectors: academia, research labs
- Tools/workflows: Open-source stack (SLURM, Ray, vLLM, SGLang, Apptainer); plug-in reference agents (Tau2, Coral); Hydra configs for reproducibility
- What to do: Run large agentic experiments with thousands of concurrent workflows; compare scheduling granularities; publish throughput-quality trade-offs
- Assumptions/dependencies: Access to cluster resources; benchmark licenses; standardized evaluation scripts; dataset cards and provenance
- Stress testing of LLM inference backends and cluster configurations
- Sectors: cloud AI providers, platform teams
- Tools/workflows: gRPC-based LLM serving with replica caches; load-balanced worker-to-replica routing; continuous batching behavior assessments
- What to do: Use Matrix to generate controlled high-load traffic patterns; validate serving engines, placement strategies, and fault tolerance on opportunistic compute
- Assumptions/dependencies: Health checks; spot/permanent node labels; retry strategies; capacity for replica refresh and failover
Long-Term Applications
These items are feasible but require further research, scaling, or productization beyond the current paper.
- Continuous, on-policy synthetic data loops tightly integrated with training
- Sectors: foundation model training, enterprise model ops
- Tools/workflows: Closed-loop pipelines where models generate data, get fine-tuned, and re-generate on updated policies; automated reward/verification gates
- Why long-term: Needs robust stability controls, automated curriculum design, and guardrails to avoid data collapse or error reinforcement
- Assumptions/dependencies: Continuous training infra; safe update strategies; dataset drift monitoring; governance
- Multi-modal synthetic data generation (text + images/audio/video/tables)
- Sectors: robotics, autonomous driving, education tech, creative tools
- Tools/workflows: Containerized simulators; multi-modal inference engines; message offloading for larger payloads; tool-use over rich environments
- Why long-term: Requires multi-modal agents, simulators, and scalable storage/transport; prompts and reward functions are more complex
- Assumptions/dependencies: Multi-modal model serving; high-throughput object storage; standardized multi-modal tool APIs
- Federated/edge peer-to-peer agent networks for privacy-preserving generation
- Sectors: healthcare, finance, public-sector
- Tools/workflows: Secure transport; per-node privacy budgets; local tool executors with global reward criteria; decentralized provenance
- Why long-term: Needs stronger security, DP guarantees, and robust peer discovery/coordination across heterogeneous nodes
- Assumptions/dependencies: Cryptographic protocols; privacy accounting; audited containers; resilient networking
- Matrix-as-a-Service (MaaS) — a managed synthetic data platform
- Sectors: enterprises, startups, ML platform vendors
- Tools/workflows: Hosted Matrix clusters with turnkey configs, serving, monitoring, SLAs, cost-aware scheduling on spot/permanent nodes
- Why long-term: Productization and operations maturity needed (billing, quotas, multi-tenancy)
- Assumptions/dependencies: Cloud orchestration; customer data governance; integration with org MLOps stacks
- Standardized tool marketplace and reward schemas for agent training
- Sectors: telecom, retail, finance, logistics, IT ops
- Tools/workflows: Community-curated tool executors and reusable reward calculators; versioned environment snapshots for reproducibility
- Why long-term: Requires consensus on schemas, licensing, and validation standards across domains
- Assumptions/dependencies: Governance bodies; test harnesses; artifact registries
- Policy frameworks for synthetic data quality, provenance, and audit
- Sectors: regulators, compliance teams, policymakers
- Tools/workflows: Dataset cards with detailed generation logs; traceable orchestrator histories; verifiable rewards; audit tooling
- Why long-term: Needs coordinated standards-setting and adoption; alignment with evolving regulations
- Assumptions/dependencies: Organizational buy-in; standardized reporting; third-party audits
- Simulation-driven digital twins for complex decision-making
- Sectors: energy grid operations, robotics, smart cities, supply chain
- Tools/workflows: Containerized simulators connected via tool-executor; large-scale trajectory generation for planning and RL
- Why long-term: High-fidelity simulators and domain reward functions required; substantial compute and integration effort
- Assumptions/dependencies: Access to accurate simulators; domain-specific metrics; integration with RL training loops
- Enterprise knowledge-base auto-curation and continuous Q&A refresh
- Sectors: enterprise software, internal IT, customer support platforms
- Tools/workflows: Scheduled Filter/Score/Question agents over KB changes; validation via tool-use checks and reward assertions
- Why long-term: Needs robust change detection, deduplication, and policy-compliant content updates
- Assumptions/dependencies: KB connectors; licensing and IP controls; drift monitoring
- Cost-aware and reliability-aware scheduling research for agentic workloads
- Sectors: academia, cloud MLOps, cost optimization tools
- Tools/workflows: Advanced schedulers that factor spot interruption risk, network congestion, and replica health into row-level decisions
- Why long-term: Requires new algorithms, evaluators, and real-world validations beyond the paper’s scope
- Assumptions/dependencies: Telemetry depth; policy engines; adaptive placement strategies
- Synthetic regulatory compliance and risk conversation simulators
- Sectors: finance (AML, KYC), insurance (claims), legal-tech
- Tools/workflows: Domain-specific rule engines and reward calculators; reproducible audit traces; scenario generation at scale
- Why long-term: Needs expert-curated rules and strong evaluation contracts to avoid harmful biases
- Assumptions/dependencies: Access to regulatory expertise; risk controls; transparent traceability
- Semi-automated licensing, deduplication, and quality gates for synthetic-to-real integration
- Sectors: data providers, content aggregators
- Tools/workflows: Scoring and filtering agents; provenance attachments; compatibility checks with real data pipelines
- Why long-term: Requires legal tooling, continual updates, and multi-party coordination
- Assumptions/dependencies: Licensing metadata; dedup services; legal review workflows
In practice, the paper’s innovations (peer-to-peer message orchestration, row-level scheduling, distributed services, and message offloading) immediately unlock higher-throughput, scalable synthetic data workflows for LLM training and evaluation. Longer-term opportunities expand this foundation into multi-modal, privacy-preserving, and productized platforms with standardized tools, governance, and simulation-rich domains.
Glossary
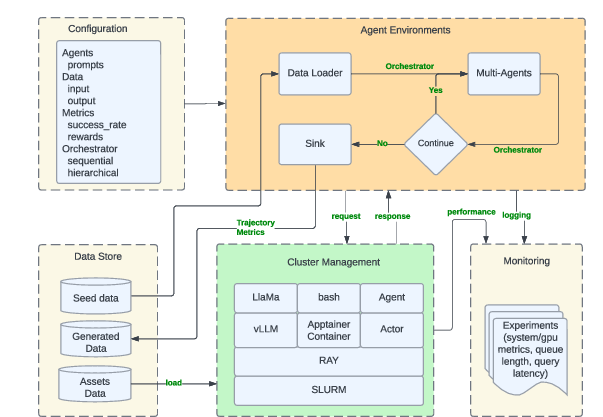
- Agent parallelism: Scaling an agent role horizontally by running multiple instances with configured CPU/GPU/memory to process tasks in parallel. "Agent parallelism. Each agent role is implemented as Ray actors with configurable CPU, GPU, and memory allocations."
- Apptainer: A container platform for running stateful, isolated environments and tools efficiently in distributed/HPC settings. "Containerized execution is supported through Apptainer~\cite{kurtzer2017singularity}, enabling stateful environments to be launched on demand."
- Batch-level scheduling: Executing tasks in synchronized batches, which can cause idle resources when task lengths diverge. "We refer to this phenomenon as batch-level scheduling."
- Containerized environments: Packaged runtime environments for tools/services that run in containers, improving isolation and reproducibility. "Matrix integrates naturally with modern inference engines such as vLLM~\cite{vllm}, SGLang~\cite{zheng2024sglangefficientexecutionstructured}, and leverages Ray~\cite{ray} for distributed execution and containerized environments via Apptainer~\cite{kurtzer2017singularity} for complex services such as software and tools execution."
- Continuous batching: An LLM serving technique that dynamically replaces completed requests in a batch to keep slots full and maximize throughput. "Similar behaviour has been observed in LLM inference systems, where “continuous batching” or token-level scheduling can replace completed requests dynamically to avoid idle slots and maintain high throughput."
- Data parallelism: Partitioning input datasets into shards to process them concurrently across workers for higher throughput. "Data parallelism. Similar to distributed processing systems such as Spark~\cite{zaharia2012rdd} and Ray Data~\cite{ray}, Matrix can partition large input datasets consisting of many small files for independent processing."
- Distributed object store: A cluster-wide, immutable object storage enabling efficient sharing and retrieval of large data among workers. "Matrix instead retains the history structure within the orchestrator, while storing large conversation content that exceed a configurable size threshold in Ray’s distributed object store."
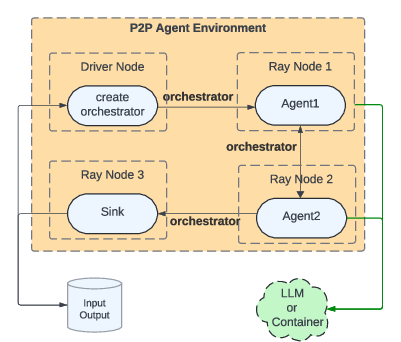
- Distributed queues: Queuing mechanisms spread across nodes that deliver serialized messages among agents without a central orchestrator. "We present Matrix, a decentralized framework that represents both control and data flow as serialized messages passed through distributed queues."
- Distributed services: External, scalable services (e.g., LLM inference, containers) that offload heavy computation from agents. "Matrix offloads computationally intensive tasks to distributed services, allowing them to scale independently of the agents."
- Event-driven process: A long-running loop that reacts to incoming messages/events, processes them, and forwards results. "Each agent runs as a persistent event-driven process (Lines 3–9) implemented by the AgentActor class."
- gRPC: A high-performance, HTTP/2-based remote procedure call framework used for efficient service communication. "For LLM inference, Matrix employs gRPC-based communication to avoid HTTP overhead."
- Hydra: A configuration framework that composes modular settings for agents, schemas, metrics, and resources. "System configurability is managed through Hydra~\cite{Yadan2019Hydra}, which specifies agent roles, input–output schemas, generation metrics, and resource requirements (e.g., LLM engine selection)."
- LLM inference: Serving LLMs to generate tokens and outputs for agent workflows. "Ray Serve provides high-throughput LLM inference services, backed by vLLM~\cite{vllm}, SGLang~\cite{zheng2024sglangefficientexecutionstructured}, and FastGen~\cite{fastgen2025}."
- Max_concurrency: A runtime parameter that limits the number of concurrently active tasks to control resource usage. "Advanced runtime features (not shown for brevity) include task-level concurrency control through a max_concurrency parameter and semaphore-based scheduling."
- Message Offloading: Storing large message contents externally (e.g., in an object store) to reduce network transfer during agent routing. "Compare Total Node Network with and without Message Offloading."
- Object identifiers: References stored in metadata that point to objects in a distributed store instead of embedding full content. "The history holds only the object identifiers, and content is retrieved on demand."
- Opportunistic compute: Preemptible, lower-priority resources (e.g., spot instances) that offer cheap capacity with possible interruptions. "Modern cloud providers offer a large amount of opportunistic compute, such as low-quality-of-service queues in SLURM and AWS spot instances."
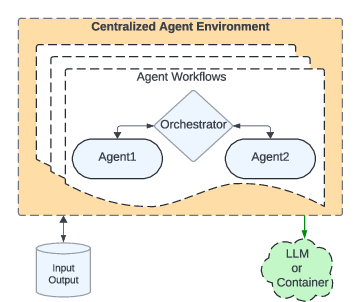
- Orchestrator: A serialized state holder that carries control logic, intermediate results, and history through agents. "The configuration also defines the orchestrator responsible for control and data flow management."
- Peer-to-peer (P2P) orchestration: Decentralized scheduling where agents pass serialized state directly, avoiding a central controller. "Using P2P orchestration, Matrix avoids bottlenecks, improves scalability, and enables fully asynchronous execution among agents."
- Ray Actor: A stateful, addressable compute unit in Ray used to implement agents with fine-grained resource control. "Each agent is implemented as a Ray Actor, allowing scalable parallelization and fine-grained resource placement across worker nodes."
- Ray Data: Ray’s distributed data processing library for batch-based transformations and parallel execution. "Unlike traditional batch-level scheduling in distributed execution engines such as Spark~\cite{zaharia2012rdd} and Ray Data~\cite{ray}, where the pipeline controls progress across synchronized batches, Matrix performs row-level scheduling..."
- Ray head node: The central coordinator in a Ray cluster responsible for scheduling and metadata; can become network-bound. "Because the Ray head node can become network-bound, Matrix maintains a local cache of active model replica URLs, enabling direct load-balanced traffic through worker nodes."
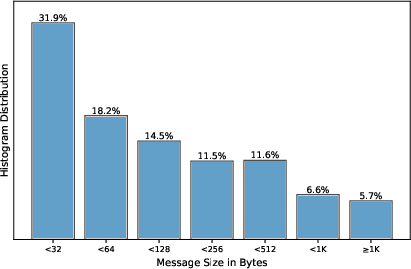
- Ray Object Store: Ray’s shared, immutable object storage layer used to cache large contents and reference them by ID. "In this case, contents exceeding 512~bytes are stored in Ray object store and retrieved on demand, which corresponds to about 12\% of the conversations."
- Ray Serve: Ray’s scalable, high-throughput model serving system for exposing inference endpoints. "Ray Serve provides high-throughput LLM inference services, backed by vLLM~\cite{vllm}, SGLang~\cite{zheng2024sglangefficientexecutionstructured}, and FastGen~\cite{fastgen2025}."
- Row-level pipelining: Advancing each individual task as soon as it completes a step, improving utilization over batch barriers. "Row-level pipelining, combined with distributed services and asynchronous agent execution, is a key factor in Matrix's scalability and efficiency for large-scale data synthesis tasks."
- Row-level scheduling: Dispatching and progressing tasks independently rather than synchronizing them in batches. "In contrast, Matrix schedules each task independently as soon as prior tasks complete, a mechanism called row-level scheduling."
- Semaphore-based scheduling: Using semaphores to enforce concurrency limits and ensure stable resource usage. "Advanced runtime features (not shown for brevity) include task-level concurrency control through a max_concurrency parameter and semaphore-based scheduling."
- SGLang: A structured generation engine that optimizes LLM execution for efficient inference and tool interactions. "Matrix integrates naturally with modern inference engines such as vLLM~\cite{vllm}, SGLang~\cite{zheng2024sglangefficientexecutionstructured}..."
- SLURM: A widely used HPC workload manager for cluster job scheduling and resource allocation. "The framework is deployed atop SLURM~\cite{slurm}, a widely adopted distributed computing environment, with a Ray~\cite{ray} cluster serving as the execution substrate."
- Token throughput: The rate of tokens generated per second, used as a performance metric for data generation systems. "Matrix achieves 2--15 higher token throughput than specialized baseline systems while maintaining comparable output quality."
- Tool-use trajectory: A sequence of tool/API calls and decisions that forms a verifiable path to solve a task. "tool-use trajectory generation in customer service environments."
- vLLM: A high-throughput LLM serving system that enables efficient inference with features like continuous batching. "Matrix integrates naturally with modern inference engines such as vLLM~\cite{vllm}, SGLang~\cite{zheng2024sglangefficientexecutionstructured}..."
Collections
Sign up for free to add this paper to one or more collections.

