- The paper demonstrates that leveraging negative policy gradients and chaining asymmetric skills enables models to extrapolate test-time compute effectively.
- It introduces a coupled curriculum that systematically adjusts data difficulty and token budgets to drive longer, more exploratory reasoning chains.
- Empirical results show that the e3-trained Qwen3-1.7B model outperforms comparable models on benchmarks like AIME'25 by discovering new solution strategies.
Introduction
This paper provides a systematic investigation of test-time compute scaling in LLMs for reasoning tasks, focusing on extrapolating beyond the maximum context lengths or token budgets seen in post-training. The authors identify a failure mode in standard LLM post-training recipes—models do not realize substantial gains by simply increasing test-time output length beyond their train-time regimes. They propose and analyze the e3 recipe, which combines (1) identifying and exploiting skill asymmetries in LLMs (such as better verification ability than generation), (2) harnessing negative policy gradients in RL fine-tuning to amplify in-context exploration, and (3) a coupled curriculum over data hardness and token budget to structure the learning of exploration strategies.
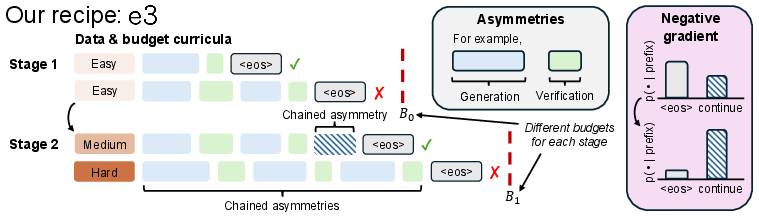
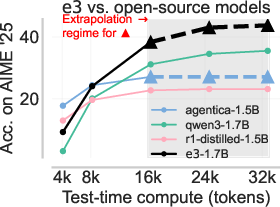
Figure 1: In-context exploration enables extrapolation at test time by chaining asymmetric abilities, leveraging negative gradients, and using a coupled curriculum.
Test-time compute scaling, wherein models generate longer completions or perform more steps of reasoning, was initially hypothesized to provide continual performance improvement, particularly on more difficult or longer-horizon reasoning problems. However, the authors empirically demonstrate that, for a diverse set of open-source models and training paradigms (RL, SFT, RLHF), pass@1 accuracy on the AIME-2025 benchmark saturates well before the full compute budget is exhausted, with minimal improvement when extrapolating output length from 16k to 32k tokens.
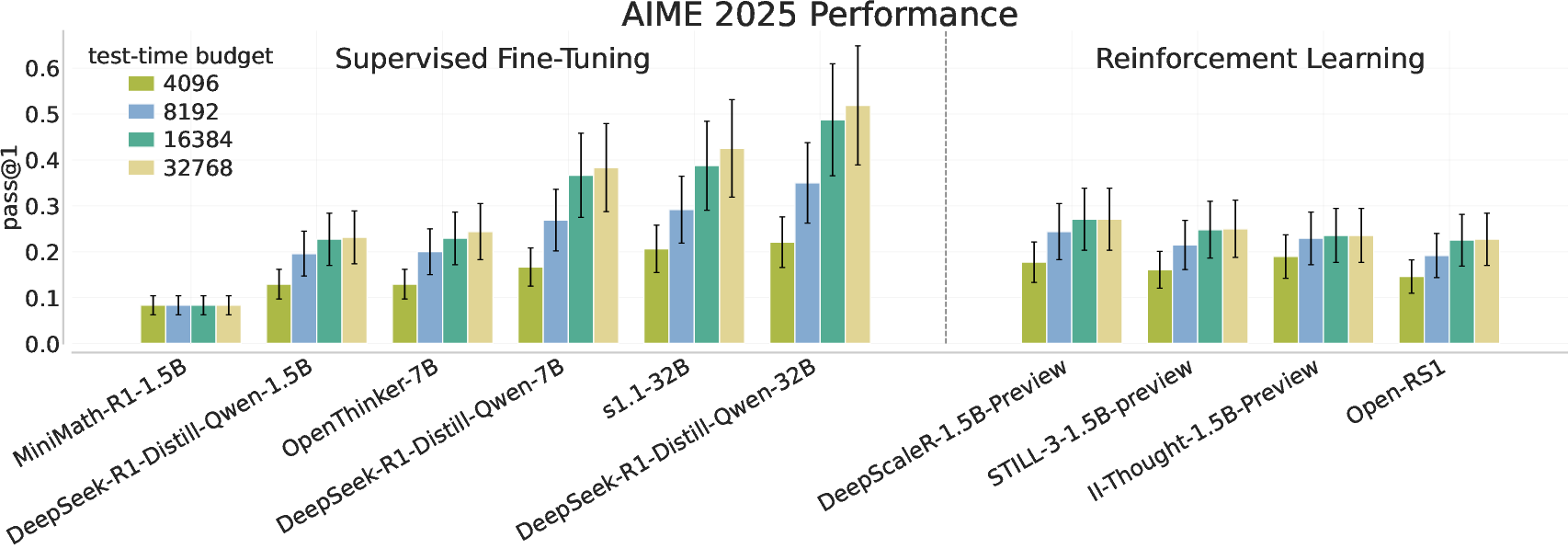
Figure 2: The pass@1 performance on AIME 2025 plateaus as test-time compute is scaled, with only minor extrapolation gains for most models regardless of size or training approach.
The authors further note that standard RL post-training mainly sharpens the model distribution over high-reward traces but does not reliably incentivize longer or more exploratory solution strategies in-context, unless particular inductive biases are present in the base model or fine-tuning procedure.
Asymmetry: The Catalyst for In-Context Exploration
The paper introduces and formalizes the notion of asymmetric skill gaps in LLMs—specifically, the verification-generation (VG) gap, where the LLM is consistently more accurate in verifying solutions than in generating correct solutions ab initio. By constructing controlled experiments on tasks such as Countdown (Cdown) and multi-digit multiplication, the authors show that only when a substantial VG gap is present does RL training amplify response length and enable extrapolative performance on extended budgets.
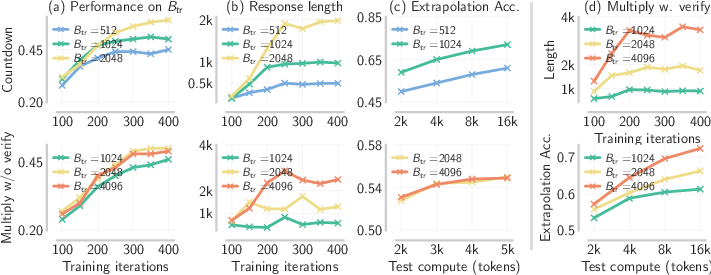
Figure 3: Length and accuracy increase with training budget only when the base model exhibits a VG gap (Cdown and Mult-V), but not for tasks lacking this asymmetry (Mult).
Crucially, empirical evidence shows that chaining asymmetric sub-skills—i.e., interleaving generation and verification in the output trajectory—yields sharply improved pass@k rates, and this effect is amplified as the number of chained asymmetries grows.
Negative Policy Gradients Drive In-Context Exploration
The authors demonstrate that the negative component of the policy gradient—gradient contributions from failed or incorrect traces, which decrease probability mass on those completions—plays a pivotal role in in-context exploration. In the presence of strong VG gaps, negative gradients increase both the entropy and the expected length of model outputs, encouraging the model to try additional solution attempts in a single forward pass (i.e., to search the solution space more thoroughly in-context before terminating).
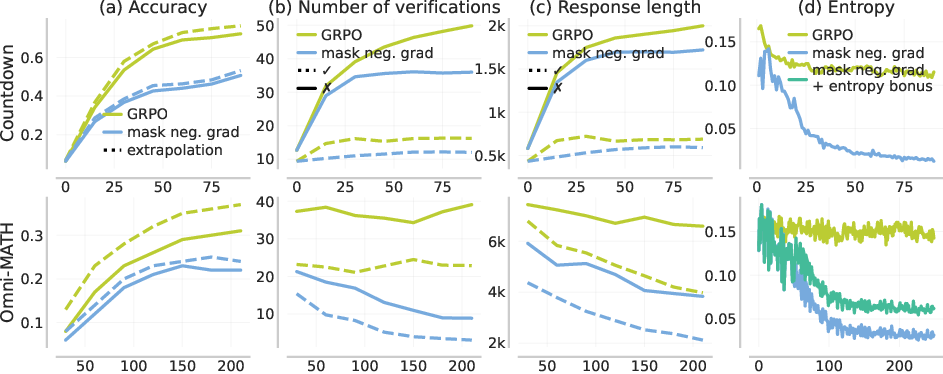
Figure 4: With negative gradients, response length, coverage (verification attempts), and entropy all increase, improving both performance and extrapolation.
This contrasts with standard SFT or RL variants lacking negative gradients, in which models quickly converge to short, low-entropy solutions ("early stopping" mode), and fail to utilize additional test-time compute for further reasoning or self-correction.
Didactic Analysis Using the pk Model
To provide theoretical insight, the authors introduce a didactic Markov chain model—the pk model—where the model makes up to k sequential guesses with per-guess failure probability p, terminating upon success or on EOS. In this model, when the verifier is perfect and the generator is imperfect, increasing k results in exponentially improving task success rates, mirroring the chain-of-verification benefit observed in LLMs with VG gaps.
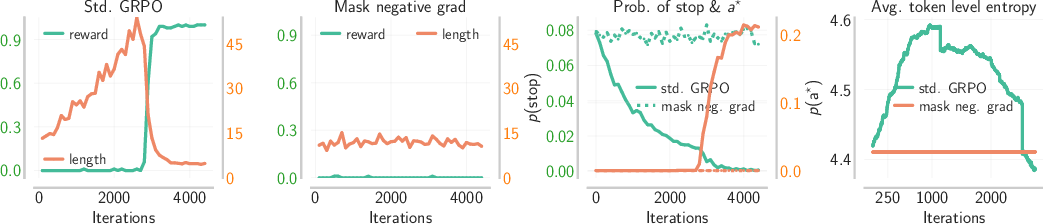
Figure 5: In the pk model, negative gradients increase sequence length and entropy, mirroring the exploration phenomenon seen in LLMs.
Mathematical analysis reveals that in this regime, negative gradients systematically push the policy toward higher-entropy, longer trajectories until a sharp "phase transition" occurs—after which the model sharpens on best traces.
Coupled Curriculum: Structuring Exploration to Overcome Optimization Challenges
Scaling RL post-training to very large token budgets leads to high variance in gradient estimates and poor optimization. Conversely, too-small budgets prevent learning longer exploratory traces, as solution attempts are prematurely truncated. A static data or curriculum over either budget or data difficulty alone is insufficient, and can bias the model toward either under-exploration or pathological verbosity.
The e3 recipe introduces a coupled curriculum spanning both input difficulty and training budget. At each curriculum stage, one selects the smallest budget such that chaining further asymmetries beyond the current budget yields marginal further gain, then escalates to harder data and longer budgets adaptively.
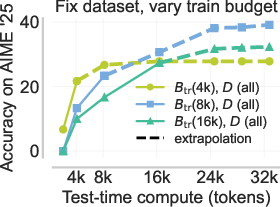
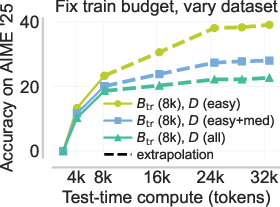
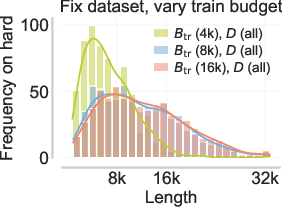
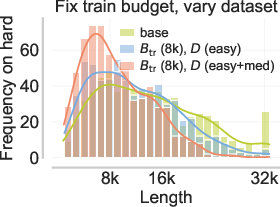
Figure 6: Static or incorrectly coupled curricula lead to failure of extrapolation due to either optimization pathologies or strangulated exploratory behavior.
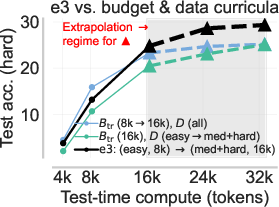
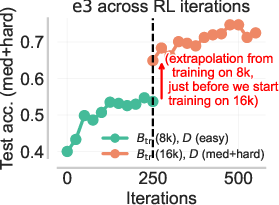
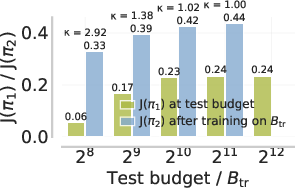
Figure 7: The coupled curriculum of e3 outperforms naive difficulty or budget-only curricula and unlocks test-time extrapolation.
Final Empirical Results and Extrapolation Capability
The e3-trained Qwen3-1.7B model achieves state-of-the-art performance among all <2B GPT-like models on the AIME'25 and HMMT'25 datasets, significantly outperforming other models even at twice its training sequence length. Importantly, e3 improves not only pass@1 but pass@k for larger k, indicating that the model discovers new solution modes rather than simply sharpening around existing successful traces—a direct contradiction to the "only sharpens" hypothesis often attributed to RL post-training.
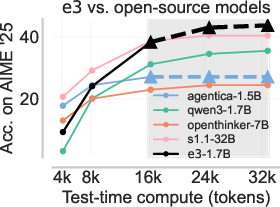
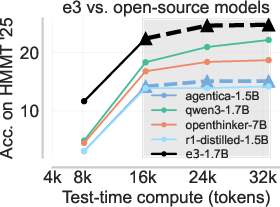
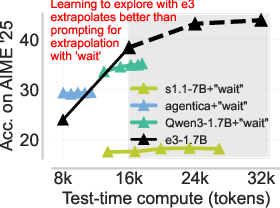
Figure 8: e3 achieves the best test-time compute scaling on AIME'25 and HMMT'25, overtaking larger models and all other <2B open-source alternatives for long-form reasoning.
Discussion and Implications
The analysis provides strong evidence and a mechanism for why RL post-training on open-ended reasoning requires three ingredients: (1) base models with exploitable skill asymmetries, (2) the inclusion of negative policy gradients, and (3) a coupled curriculum tuning both problem hardness and token budget. Notably, if these are not satisfied—e.g., for tasks lacking a VG gap or for models trained only with positive gradients—LLMs trained with standard RL or SFT cannot leverage extrapolated test compute.
Contradictory empirical finding: The paper counters prevailing claims that RL fine-tuning "only sharpens the base model," providing both empirical and theoretical support that, in the presence of the right preconditions, RL with negative gradients actually unlocks new modes of in-context exploration.
The results also imply that further scaling of output length, especially with ever-larger context windows, will require addressing base-model repetition biases and may benefit from explicit exploration bonuses. Indeed, the chain of skill asymmetries used in e3 could generalize to other forms of asymmetric reasoning, as long as these are reliably present in the base model or can be instilled during base pretraining.
Conclusion
The e3 recipe systematically addresses the failings of current post-training approaches for LLM test-time compute scaling. By targeting base model asymmetries, leveraging negative gradients, and enforcing a coupled curriculum, it unlocks structured in-context exploration—enabling models to solve harder problems with longer, more varied reasoning chains as test-time budgets increase, and outperforming all comparably sized open-source LLMs on challenging benchmarks. Future directions include better identifying and instilling exploitable skill asymmetries, extending this paradigm to larger models and multimodal tasks, and bridging coupled curriculum methods with dense reward architectures to further boost long-horizon reasoning.

