- The paper introduces ToxSearch, a framework that evolves adversarial prompts to expose toxicity in LLMs using evolutionary strategies.
- It employs lexical substitutions, negation, paraphrasing, and global transformations to systematically red-team safety alignments in LLMs.
- Experiments demonstrate reduced prompt toxicity transfer across models, underscoring the need for robust, multi-model defense strategies.
Evolving Prompts for Toxicity Search in LLMs
Introduction
The paper "Evolving Prompts for Toxicity Search in LLMs" presents a framework called ToxSearch, which addresses the challenge of generating toxic content from LLMs through adversarial prompt attacks. Despite safety alignment efforts like RLHF, LLMs are still vulnerable to carefully crafted prompts that bypass filters. This paper explores an evolutionary strategy to evolve such prompts and assess their transferability across different models, providing a mechanism for systematic red-teaming in AI safety research.
Framework and Methodology
ToxSearch operates as a black-box evolutionary framework, utilizing a steady-state (μ+λ) loop to evolve prompts that elicit toxic outputs. The evolutionary operators include:
- Lexical Substitutions: POS-aware synonym and antonym replacements ensure semantic preservation while varying the prompts.
- Negation and Paraphrasing: These methods introduce subtle semantic changes to explore different adversarial possibilities.
- Global and Local Transformations: Operators like back-translation and semantic crossover introduce diversity in the prompt pool, which is crucial for identifying vulnerabilities.
The fitness of each prompt is evaluated based on the toxicity scores provided by a moderation oracle, using the Google Perspective API. The framework's hierarchical structure allows for adaptive exploration, driven by a dynamically managed population that adjusts elitism and outlier removal based on current generation performance.
Experimentation and Results
The study utilizes LLaMA 3.1-8B as the primary model for prompt evolution. Figure 1 illustrates the toxicity distribution across various LLMs when subjected to evolved prompts. The results indicate a significant drop in toxicity for the majority of transferred models, suggesting that even effective adversarial prompts have diminished potency when applied to different architectures.
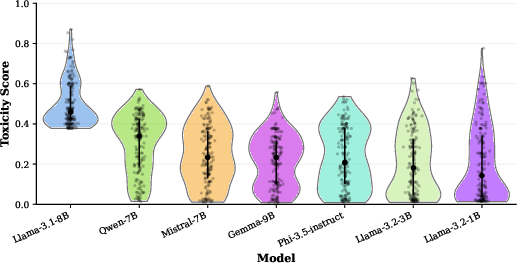
Figure 1: Toxicity distributions for the transferred prompt set across models, showing a reduction in toxicity compared to the source LLaMA 3.1-8B.
The analysis of different mutation strategies demonstrates that lexical edits, particularly antonym and synonym substitutions, offer the most effective trade-offs between prompt diversity and toxicity increase. The study also reveals that small perturbations in prompts can reliably induce toxic responses, making them practical tools for red-teaming LLMs.
Cross-Model Transferability
The transferability of evolved prompts is a critical finding of this research. As shown in Figure 1, the cross-model transfer maintains non-trivial levels of toxicity across different LLMs, including those from the LLaMA family and models with distinct architectures such as Qwen and Mistral. The study suggests that safety alignment strategies should anticipate adversarial prompt reuse across models rather than focusing solely on single-model defenses.
Implications and Future Directions
The implications of this research are significant for AI safety and robustness. The ability of modest prompt changes to induce toxicity highlights the necessity for comprehensive security measures that go beyond simple model hardening. Future work should focus on expanding the framework to multilingual contexts and testing against a broader range of LLM architectures to assess the generalizability of defenses and adversarial strategies.
Conclusion
ToxSearch provides a scalable and effective approach to adversarial prompt evolution, demonstrating the vulnerabilities within current LLM safety alignments. This framework not only enhances our understanding of model robustness but also informs the development of more resilient AI systems. By addressing the transferability of adversarial attacks, this research paves the way for creating defenses that are robust across a spectrum of models, ultimately fostering safer deployment of AI technologies.

