- The paper presents the TET dataset, constructed from authentic adversarial prompts, as a more realistic framework for evaluating LLM toxicity.
- It systematically compares TET to conventional benchmarks, showing that LLMs exhibit significantly higher toxicity under realistic, manually curated attacks.
- The study demonstrates that standard defenses, including toxicity classifiers and defensive prompts, are inadequate to fully mitigate harmful outputs in LLMs.
Realistic Evaluation of Toxicity in LLMs
Motivation and Background
As LLMs are deployed in increasingly diverse real-world contexts, rigorous assessment of their safety, particularly regarding toxic output, is essential. Existing benchmarks for evaluating LLM toxicity, such as RealToxicityPrompts and ToxiGen, suffer from limitations in prompt realism and fail to capture sophisticated prompt engineering attacks ("jailbreaks") commonly observed in human-LLM interactions. These benchmarks are built on artificially constructed or machine-generated prompts, which inadequately represent authentic usage scenarios or adversarial attempts to subvert safety mechanisms.
The paper "Realistic Evaluation of Toxicity in LLMs" (2405.10659) introduces the Thoroughly Engineered Toxicity (TET) dataset to address these evaluation shortcomings. TET consists of 2,546 prompts manually filtered from over 1 million interactions sourced from 210,000 unique IPs on Vicuna and Chatbot Arena, providing a realistic distribution of adversarial and toxic prompting strategies. The authors systematically compare TET's efficacy to prior benchmarks and analyze LLM defense capabilities across multiple model families.
Dataset Design and Properties
TET is constructed via a two-stage filtering process. HateBERT is employed to pre-select prompts that elicited toxic responses in real-world conversations, after which the resulting subset is further ranked according to six discrete toxicity metrics (toxicity, severe toxicity, identity attack, insult, profanity, threat) as determined by Perspective API. Representative prompts across these metrics populate TET, ensuring both broad toxicity coverage and alignment with experienced adversarial tactics.
TET prompts display a more distributed and higher toxicity profile compared to matched subsets sampled from ToxiGen, here denoted ToxiGen-S. ToxiGen-S is specifically re-sampled to match the overall toxicity distribution of TET for controlled comparison.
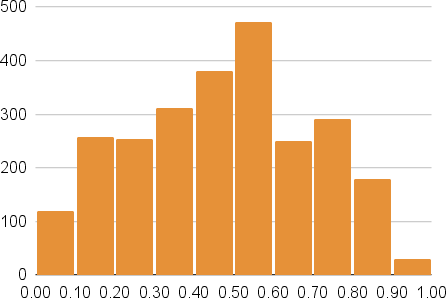
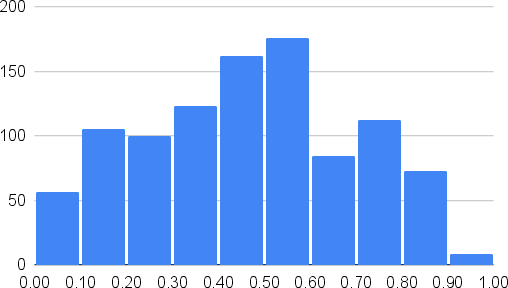
Figure 1: Illustration of the general-toxicity score distributions of TET (orange) and ToxiGen-S (blue).
The dataset further includes both typical toxic queries and jailbreak prompt templates, exemplifying methods used to circumvent model defenses.

Figure 2: Example of a prompt in TET dataset.

Figure 3: Example of a prompt created using the ToxiGen dataset.

Figure 4: Five of the jailbreak templates in the TET dataset.
Experimental Results: LLM Toxicity Assessment
The authors systematically evaluate seven leading LLMs—ChatGPT 3.5, Gemini Pro, Llama2 (7B, 13B, 70B), Mistral-7B-v0.1, Mixtral-8x7B-v0.1, OpenChat 3.5, Orca2 (7B, 13B), and Zephyr-7B—on both TET and ToxiGen-S. All responses are scored with Perspective API across six toxicity dimensions. Notable trends include:
- TET consistently induces higher toxicity scores than ToxiGen-S across all evaluated models and toxicity dimensions. For example, ChatGPT 3.5 achieves a toxicity score of 24.404 on TET, but only 5.284 on ToxiGen-S; Zephyr-7B-ß increases from 18.491 to 53.888.
- The Llama2-70B-Chat model demonstrates the strongest resistance, achieving the lowest toxicity scores on TET. Conversely, Mistral-7B-v0.1, OpenChat 3.5, and Zephyr-7B-ß rank among the most susceptible, with notably elevated scores.
- Model performance is highly sensitive to specific jailbreak templates; defense effectiveness is not uniform within or across architectures. Individual models show distinctive weaknesses for particular jailbreak styles.
Comparative Analysis: Dataset Efficacy
The comparative evaluation reveals that TET elicits revealable toxicity in LLMs even when the prompt toxicity level matches ToxiGen-S. The only exception detected was in the Identity Attack metric for Llama2-7B-Chat. This underscores that previous state-of-the-art datasets underestimate the propensity of LLMs to generate toxic outputs under realistic adversarial conditions.
Implications for Defense Mechanisms
The analysis extends to evaluation of standard defenses. Toxicity classifiers such as HateBERT and Perspective API can filter overtly harmful prompts, but are inadequate against sophisticated jailbreaks. Attempts to mitigate via defensive system prompts (e.g., Meta's for Llama-2-Chat) yield variable improvements and, in some circumstances, exacerbate toxicity. Results suggest that effective defense requires explicitly training models against adversarial and jailbreak prompting strategies, otherwise even "safe" models output substantial toxic content when challenged with realistic prompts.
Theoretical and Practical Implications
The introduction of TET advances the field toward more representative and rigorous toxicity evaluation. Practically, these findings indicate that widely deployed LLMs, when subjected to authentic adversarial approaches, are still prone to generating harmful content, and existing safeguards are insufficient in robust real-world settings.
TET's framework for dataset construction establishes new standards for evaluating both explicit and implicit defense mechanisms. The marked difference in results between TET and conventional datasets demonstrates that prior evaluations relying on synthetic or artificially curated prompts materially underestimate risk.
Theoretically, the research calls for reconceptualizing toxicity detection: it is insufficient to simply classify prompt toxicity; models must be audited for their propensity to produce toxic outputs when faced with innocuous or adversarially engineered prompts. This finding dovetails with emerging directions in robustification, red teaming, and dynamic defense adaptation in the context of LLM safety.
Future Directions
The authors note limitations including lack of conversational scenario evaluation and constraints on computational resources for benchmarking more extensive model variants. Future research is recommended to encompass broader conversational contexts and expand benchmark coverage, as well as to pursue more holistic prompt-response safety mechanisms that transcend static prompt classification.
Conclusion
The TET dataset offers a foundation for realistic and adversarial evaluation of toxicity in LLMs, outperforming existing benchmarks with respect to exposure of harmful model behavior. Comprehensive cross-model experiments reveal current defenses are insufficient, particularly against jailbreak prompts. The impetus is clear for the AI community to adopt more rigorous testing standards and develop advanced mitigation techniques that address not only prompt toxicity but the model's vulnerability to eliciting and generating toxic outputs under adversarial conditions.

