Depth Anything 3: Recovering the Visual Space from Any Views
Abstract: We present Depth Anything 3 (DA3), a model that predicts spatially consistent geometry from an arbitrary number of visual inputs, with or without known camera poses. In pursuit of minimal modeling, DA3 yields two key insights: a single plain transformer (e.g., vanilla DINO encoder) is sufficient as a backbone without architectural specialization, and a singular depth-ray prediction target obviates the need for complex multi-task learning. Through our teacher-student training paradigm, the model achieves a level of detail and generalization on par with Depth Anything 2 (DA2). We establish a new visual geometry benchmark covering camera pose estimation, any-view geometry and visual rendering. On this benchmark, DA3 sets a new state-of-the-art across all tasks, surpassing prior SOTA VGGT by an average of 44.3% in camera pose accuracy and 25.1% in geometric accuracy. Moreover, it outperforms DA2 in monocular depth estimation. All models are trained exclusively on public academic datasets.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Depth Anything 3 — Simple Explanation
What is this paper about?
This paper introduces Depth Anything 3 (DA3), a computer vision model that can understand 3D scenes from any number of pictures—one photo, a few photos, or a whole video. It can work even if it doesn’t know the camera positions up front. The big idea is to keep the model simple: use one standard transformer (a type of neural network) and predict just two things for every pixel—how far it is (depth) and which direction the camera “looks through” that pixel (a ray). With only these, DA3 can rebuild the 3D space, estimate camera poses, and even render new views of the scene.
What questions were the researchers trying to answer?
- Can a single, simple model recover accurate 3D structure from any number of images?
- Do we really need many different tasks and complex architectures, or can we predict just a minimal set of things (depth and rays) and still get great results?
- Can this approach work with or without known camera poses?
- Will a simple transformer backbone (no special layers) be enough?
- Can this model beat strong existing methods on pose accuracy, 3D geometry, and single-image depth?
How did they do it?
To keep things straightforward, the team used a “minimal modeling” strategy:
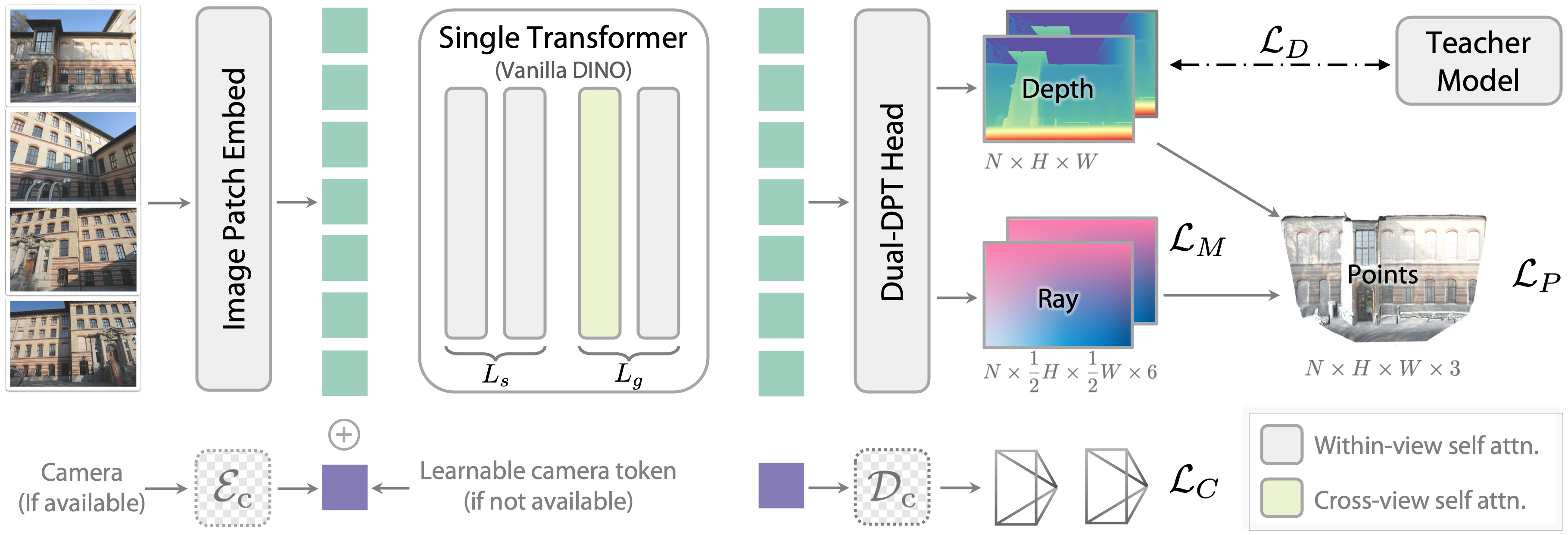
- One plain transformer backbone:
- Think of a transformer as a smart reader that looks at all pixels and learns which parts of the images should “pay attention” to each other.
- They used a standard, pretrained vision transformer (like DINOv2) without custom changes.
- Predicting just depth and rays:
- Depth map: for each pixel, how far away the scene point is.
- Ray map: for each pixel, the origin and direction of the camera’s “line of sight” through that pixel (like millions of tiny flashlight beams coming from the camera).
- With depth + ray, you can compute the exact 3D point for each pixel and reconstruct the whole scene.
- Cross-view attention that adapts to any number of images:
- If you input multiple images, the transformer learns to pass information across views (so it understands how the same object looks from different angles).
- If there’s only one image, it naturally behaves like a regular monocular depth model.
- Optional camera tokens:
- If camera parameters (pose) are known, they are encoded as tiny tokens and fed into the model.
- If poses are unknown, a shared learnable token is used instead. The model then predicts poses from the images themselves.
- Dual decoder (Dual-DPT head):
- A shared decoder processes features, then two small branches output the depth map and the ray map.
- Using the same features keeps depth and rays consistent.
- Teacher–student training:
- Real-world depth data can be noisy or incomplete. So they trained a “teacher” model on clean synthetic data to produce high-quality depth labels.
- The student (DA3) learns from these teacher-made labels and aligns them to the messy real measurements so the geometry stays accurate.
- This improves detail, sharp edges, and overall 3D consistency.
- Unified evaluation benchmark:
- They built a new benchmark that measures camera pose accuracy, 3D reconstruction quality (by fusing predicted depth into a point cloud), and how well the model can render new views.
What did they find, and why does it matter?
- Strong accuracy across tasks:
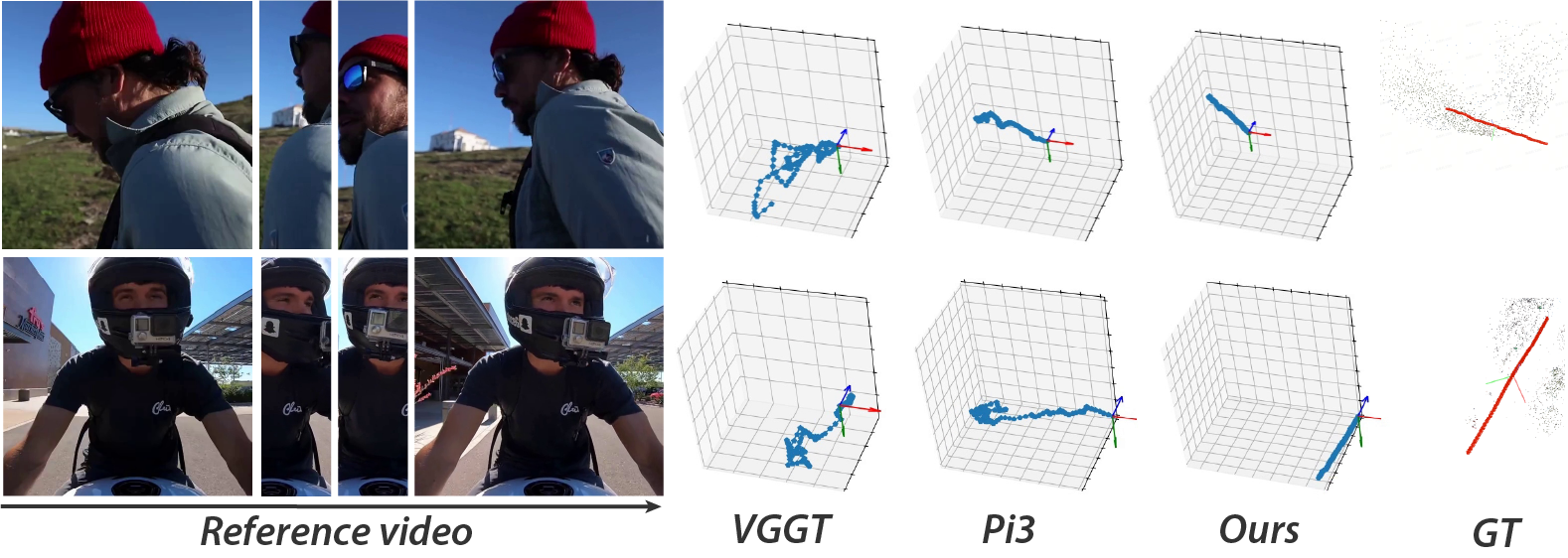
- DA3 sets a new state of the art on pose accuracy and 3D geometry across many datasets.
- Compared to a leading model (VGGT), DA3 improves camera pose accuracy by about 35.7% and geometry accuracy by about 23.6% on their benchmark.
- Works from any number of views, with or without poses:
- From a single image, it outperforms “Depth Anything 2” (DA2) in monocular depth.
- From multiple images, it produces consistent depth and accurate camera poses, leading to clean 3D reconstructions.
- Simple but effective:
- No complicated multi-task setup, no special architecture—just a standard transformer plus a dual head for depth and rays.
- This makes the model easier to train, easier to scale, and easier to adapt.
- Better novel view synthesis (making new images from unseen viewpoints):
- By fine-tuning DA3 with a small extra head, the model can predict “3D Gaussians” (think soft, colored 3D blobs that represent the scene) for fast rendering.
- This feed-forward approach (no slow per-scene optimization) outperforms specialized methods and shows that better geometry directly leads to better rendering quality.
Simple analogies for the technical terms
- Depth map: A distance picture—each pixel tells how far the scene is at that spot.
- Ray map: For each pixel, imagine a tiny laser beam from the camera pointing into the world; the model learns the origin and direction of that beam.
- Point cloud: A 3D scatter of points that, together, form the surfaces of the scene—like a very detailed 3D constellation.
- Transformer: A neural network that uses “attention” to understand how parts of an image relate to each other and across multiple images.
- 3D Gaussians: Soft 3D blobs with position, size, shape, and color that can be quickly splatted to render images from new viewpoints.
What could this change or enable?
- More robust robotics and AR/VR:
- Robots and headsets can map and understand the 3D world more reliably from cameras alone, even without knowing the exact camera poses.
- Faster 3D content creation:
- Filmmakers, game developers, and 3D artists can turn a few photos into usable 3D scenes quickly and consistently.
- Simpler, unified 3D tools:
- One model that handles single images, multiple views, and videos reduces complexity in pipelines.
- Better research foundations:
- A clean, minimal approach (depth + rays) shows that we can avoid overly complicated multi-task setups and still achieve top performance.
- Broad real-world impact:
- Improved accuracy and generalization using only public datasets suggests this approach is accessible and scalable for many applications.
In short, Depth Anything 3 demonstrates that with smart training and minimal design—predicting just depth and rays using a standard transformer—you can recover detailed, consistent 3D geometry from any set of images, estimate camera poses, and render convincing new views. This makes 3D understanding more reliable, faster, and easier to use in the real world.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and questions that remain unresolved and could guide future research:
- Validity of the per-pixel ray-origin design: The ray map predicts per-pixel origins
teven though a physical pinhole camera has a single center. There is no constraint enforcing constant origin across pixels; the paper averages origins to estimate the camera center. Investigate adding consistency regularization (e.g., low-variance penalty ont) or an explicit camera-center parameter to reduce degeneracy and improve pose recovery. - Assumptions on camera model and lens distortion: Pose recovery from the ray map assumes a pinhole camera and distortion-free intrinsics. Evaluate DA3 on fisheye, wide-FOV, smartphone lenses with strong distortion, and rolling-shutter cameras; assess whether extending the
H = K Rdecomposition to include skew and distortion parameters is necessary. - Scale ambiguity and coupling between depth and ray direction magnitude: The method does not normalize ray directions
dto preserve projection scale, but this couples depth scale to||d||. Quantify failure modes when||d||and depthDare jointly mis-scaled, and explore strategies for disentangling scale (e.g., unit-normdwith an explicit per-view scale). - Computational trade-offs in ray-to-pose recovery: The DLT/RQ decomposition over all pixels is claimed to be costly and replaced by a camera head, but the paper does not quantify runtime or accuracy trade-offs. Provide benchmarks comparing DLT/RQ vs. the camera head across scene types, resolutions, and view counts.
- Degenerate cases in
H = K Restimation: Analyze and detect degeneracies (e.g., near-planar scenes, narrow FOVs, limited parallax) where homography estimation from ray directions is ill-conditioned. Introduce conditioning diagnostics or robust optimization strategies. - Training of the camera head under limited pose supervision: The camera head predicts
f, q, t, but many datasets are unposed; pose conditioning is used only with 0.2 probability. Clarify how the camera head learns reliably under sparse pose supervision and measure its sensitivity to pose label quality. - Cross-view self-attention scalability: Token reordering enables cross-view attention, but complexity scales quadratically with total tokens. Quantify memory/runtime as view count and resolution grow (e.g., 50–200 views, 1–4K resolution) and explore scalable variants (sparse attention, windowed cross-view, epipolar-aware attention).
- Occlusion/disocclusion handling: The minimal transformer lacks explicit epipolar/cost-volume structures. Evaluate multi-view consistency under severe occlusion/disocclusion and compare against epipolar-constrained architectures; consider adding light-weight geometric priors.
- Dynamic scenes and temporal consistency: DA3 targets “any views” but the training and evaluation focus on static scenes. Test robustness with moving objects, motion blur, scene changes, and streaming video; assess temporal stability and drift across long sequences.
- Domain gap from synthetic teacher supervision: The teacher is trained exclusively on synthetic data and aligned to noisy/sparse real depth via RANSAC scale–shift. Quantify domain-shift artifacts (texture, noise, specular/transparent materials) and evaluate alternative teacher training mixes (e.g., semi-supervised real data, photometric self-supervision).
- Reliability of RANSAC scale–shift alignment: The alignment of pseudo-depth to metric measurements depends on sparse/noisy real depths, yet the paper does not report failure rates or outlier sensitivity. Add diagnostics for inlier ratios, residual distributions, and the impact on downstream geometry.
- Evaluation on non-indoor/outdoor extremes: The benchmark covers indoor, object-centric, and some outdoor scenes but lacks extreme settings (night, adverse weather, underwater, very high/low light). Systematically test cross-domain generalization and failure modes.
- Monocular absolute metric depth calibration: The teacher/student setups focus on relative depth and scale–shift alignment. Investigate explicit metric calibration (focal-length-aware normalization, per-scene scale estimation) and report absolute depth errors across diverse cameras.
- Uncertainty modeling and usage: A depth confidence
D_cis included in losses but not utilized in inference or fusion. Calibrate predictive uncertainties and propagate them into pose estimation, TSDF fusion, and NVS to improve robustness. - TSDF fusion and reconstruction hyperparameter sensitivity: Geometry metrics depend on TSDF voxel size and fusion settings per dataset. Quantify sensitivity of F1/Chamfer to fusion parameters and propose dataset-agnostic fusion configurations or learned fusion.
- Benchmark thresholds and comparability: F1 thresholds vary by dataset (e.g., 0.05 m vs. 0.25 m). Examine the impact on model ranking and propose standardized, cross-dataset thresholds or threshold-swept AUC-like metrics for reconstruction.
- Pose-free NVS evaluation missing: Rendering metrics (PSNR/SSIM/LPIPS) are reported with ground-truth poses; there is no evaluation of pose-adaptive FF-NVS using predicted poses. Add an unposed NVS track that uses DA3-predicted poses and quantify the degradation relative to posed inputs.
- Generalization of FF-NVS beyond DL3DV: The 3DGS model is trained primarily on DL3DV; robustness to outdoor scenes, reflective/transparent materials, and highly specular environments is untested. Expand training/evaluation to Tanks and Temples, MegaDepth-like outdoor, and synthetic challenging materials.
- Joint training vs. frozen backbone for NVS: The FF-NVS head is trained with a frozen DA3 backbone. Explore end-to-end fine-tuning and multi-task training (geometry + NVS) to measure trade-offs in geometry accuracy and rendering quality.
- Minimal targets vs. richer multi-task outputs: The paper argues depth–ray is a minimal sufficient target but provides limited ablations against alternatives (point maps, normals, cost volumes). Conduct broader comparisons, including normals and multi-scale point maps, to verify the sufficiency claim across tasks.
- Camera intrinsics variability and canonicalization: Canonical focal-length transforms are used in the metric model but not analyzed for DA3 training/inference. Study intrinsics variability across datasets and whether intrinsics-aware normalization benefits pose and depth predictions in DA3.
- Robustness to repeated patterns/symmetries/low texture: Classical MVG suffers here; DA3’s robustness is asserted but not stressed. Create stress tests (repetitive textures, reflective glass, textureless walls) to quantify failure modes and compare to SfM/MVS baselines.
- Resource efficiency and accessibility: Training uses 128 H100 GPUs for 200k steps. Report sample efficiency, scaling laws, and smaller/backbone variants (e.g., ViT-B/L) to make the approach accessible and assess performance–compute trade-offs.
- Per-pixel ray direction calibration across resolutions: Mixed-resolution training is used, but the effect on ray-direction accuracy is not reported. Evaluate calibration consistency of
dacross aspect ratios/resolutions and add resolution-aware positional encodings if needed. - Reproducibility details and data leakage checks: The paper claims scene-level separation (e.g., ScanNet++), but cross-dataset object/scene overlaps are possible (Objaverse/Co3D/Replica derivatives). Provide deduplication procedures and reproducibility checklists (seeds, splits, preprocessing).
- Limitations of the dual-DPT head design: The dual head shares reassembly but uses separate fusion layers. Ablate alternative designs (shared vs. separate decoders, cross-task feature modulation) to understand interactions and potential negative transfer between depth and ray predictions.
- Theoretical guarantees for ray-based sufficiency: Beyond empirical results, there is no theoretical analysis of identifiability (conditions under which depth + rays uniquely determine
R, K, t). Provide formulations and proofs or counterexamples to guide model design. - Handling spherical harmonics vs. per-pixel color in 3DGS: The paper switches to SH for view-dependent rendering but does not quantify geometry–appearance trade-offs. Analyze how SH order, opacity regularization, and depth offsets affect fidelity and geometric accuracy.
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging DA3’s state-of-the-art any-view geometry, monocular depth, pose estimation, and feed-forward 3D Gaussian rendering.
- Robotics: Drop-in visual geometry module for navigation and manipulation
- Sector: Robotics
- What: Use DA3’s joint depth and pose from arbitrary images or video to improve visual SLAM, obstacle detection, and grasp planning—especially in low-texture or specular environments where classical pipelines are brittle.
- Tools/Workflows: DA3 inference → per-frame depth+ray → pose derivation (camera head or DLT-based) → TSDF fusion → map; plug into ROS/SLAM stacks for loop closure and path planning.
- Assumptions/Dependencies: Rigid scenes at inference; sufficient view overlap and coverage; camera intrinsics available or well-estimated; compute for transformer inference on device or edge.
- AR/MR occlusion and environment understanding on mobile
- Sector: Software, Consumer AR
- What: Improve occlusion, surface understanding, and scene anchors using DA3’s strong monocular depth (surpassing DA2) and multi-view consistency; works with or without known poses.
- Tools/Workflows: App SDK → DA3 monocular depth for single-frame occlusion; multi-frame “any-view” mode for persistent scene meshes; optional camera-token conditioning if device intrinsics are known.
- Assumptions/Dependencies: Static or slowly changing environments; camera calibration quality; latency targets acceptable for mobile inference.
- Pose-free photogrammetry for 3D capture
- Sector: Media/Entertainment, Cultural Heritage, Real Estate
- What: Convert casual photo sets into consistent point clouds and 3D Gaussians without precomputed poses; bootstrap or replace COLMAP in hard scenes.
- Tools/Workflows: Photo collection → DA3 depth+ray → pose from ray map → TSDF or 3DGS fusion → export mesh/point cloud; optional fine-tuning GS-DPT head for rendering quality.
- Assumptions/Dependencies: Adequate image coverage and baselines; rigid scenes; lighting changes manageable; compute for batch inference.
- E-commerce product digitization (scan-to-3D)
- Sector: Retail/E-commerce
- What: Rapidly generate 3D assets from a handful of product photos (posed or pose-free), supporting spin renders and AR try-ons.
- Tools/Workflows: Capture app → DA3 → 3DGS or mesh export → pipeline to PBR rendering; integrates with asset catalogs.
- Assumptions/Dependencies: Background segmentation (e.g., RMBG) for clean assets; consistent lighting preferred; product turntable improves coverage.
- Construction/BIM and facility documentation
- Sector: AEC (Architecture, Engineering, Construction)
- What: Site scanning from handheld or drone imagery to produce floor-level 3D reconstructions for progress tracking and as-built documentation.
- Tools/Workflows: Image/video ingestion → DA3 → TSDF fusion → alignment to site coordinates (Umeyama-based) → BIM integration.
- Assumptions/Dependencies: Static structures; pose conditioning preferred with known intrinsics; drones benefit from additional IMU/GNSS.
- Drone surveying and mapping when GPS/IMU is limited
- Sector: Energy & Infrastructure, Geospatial
- What: Robust visual pose estimation and dense geometry from aerial imagery in GPS-denied environments.
- Tools/Workflows: Mission imagery → DA3 → pose estimation from ray maps → dense depth fusion; integrates with GIS tools.
- Assumptions/Dependencies: Sufficient overlap; rolling shutter/blur mitigation (capture settings); altitude variation manageable.
- VFX pre-visualization and environment reconstruction
- Sector: Media/Entertainment
- What: Quickly reconstruct sets from multi-view footage for blocking, camera planning, and virtual production previews.
- Tools/Workflows: Footage frames → DA3 → 3DGS rendering for real-time previews; export to DCC tools (Unreal, Blender).
- Assumptions/Dependencies: Static sets; acceptable render fidelity from 3DGS for pre-vis; temporal consistency handled via input selection.
- Education and research: Unified geometry foundation model
- Sector: Academia
- What: Use DA3 as a minimal-model baseline for courses and labs in 3D vision, SLAM, and neural rendering; adopt the new benchmark for pose, geometry, and rendering.
- Tools/Workflows: Curriculum modules → DA3 inference notebooks; benchmark datasets (HiRoom, ETH3D, DTU, 7Scenes, ScanNet++) → reproducible evaluation.
- Assumptions/Dependencies: Access to GPUs; familiarity with transformer-based vision; static-scene focus for introductory labs.
- 3DGS content generation pipelines
- Sector: Software/Graphics
- What: Feed-forward novel view synthesis with DA3 + GS-DPT head (pose-conditioned or pose-adaptive) to produce ready-to-render 3D Gaussian scenes.
- Tools/Workflows: Inference on selected views → 3DGS params + depth → rasterization; quality tuning via photometric and depth losses; export SH-based color for view-dependence.
- Assumptions/Dependencies: Fixed camera sets; scene rigidity; acceptance of 3DGS trade-offs (speed vs perfect surface fidelity).
- Photogrammetry acceleration and COLMAP bootstrapping
- Sector: Software
- What: Use DA3 poses and depth to initialize classical SfM/MVS pipelines, reducing failures in low-texture regions.
- Tools/Workflows: DA3 outputs → initial pose graph → COLMAP refinement → dense stereo; fallback to DA3 point clouds when SfM fails.
- Assumptions/Dependencies: Access to existing photogrammetry stacks; scene rigidity; benefits strongest in difficult texture cases.
- Public-sector digital archiving and inspection
- Sector: Government/Policy, Cultural Heritage
- What: Rapid documentation of assets (historical sites, infrastructure) from photo collections; supports audit trails and public records.
- Tools/Workflows: Capture guidelines → DA3 reconstruction → metadata tagging → repository integration.
- Assumptions/Dependencies: Privacy and data management policies; capture standardization; long-term storage formats for 3D assets.
- Smartphone “scan-to-share” for social content
- Sector: Consumer
- What: Create and share 3D snippets from short multi-view captures; improved depth for single-shot effects.
- Tools/Workflows: App UX → DA3 monocular or multi-view inference → lightweight 3DGS render → shareable clips.
- Assumptions/Dependencies: On-device or cloud inference; battery and latency constraints; user guidance for coverage.
Long-Term Applications
These applications are feasible with further research, scaling, or engineering—particularly for dynamic scenes, real-time edge deployment, and safety-critical use.
- Real-time, on-device any-view geometry for AR glasses and smartphones
- Sector: Consumer AR, Wearables
- What: Continuous scene modeling (pose+depth) at interactive frame rates for occlusion, spatial anchors, and world mapping.
- Tools/Workflows: Quantized DA3 variants → mobile transformer accelerators → memory-optimized fusion; incremental map updates.
- Assumptions/Dependencies: Efficient model compression; specialized hardware (NPUs); energy constraints; robust handling of motion blur and rolling shutter.
- Dynamic-scene reconstruction (people, vehicles, deformables)
- Sector: Robotics, Media/Entertainment
- What: Extend DA3 to handle non-rigid motion and scene dynamics, enabling motion-aware 3DGS or neural surface models.
- Tools/Workflows: Motion segmentation → per-object geometry/pose → temporal fusion; integration with optical flow or dynamic radiance fields.
- Assumptions/Dependencies: Additional training on dynamic datasets; new losses/objectives; careful temporal consistency modeling.
- City-scale mapping and digital twins with mixed sensors
- Sector: Smart Cities, Infrastructure
- What: Fuse DA3 vision with LiDAR, GNSS/IMU at scale for persistent geospatial models and asset inventories.
- Tools/Workflows: Multimodal fusion → DA3 as vision backbone → large-area TSDF/3DGS; change detection over time.
- Assumptions/Dependencies: Scalable storage/computation; standardized data pipelines; regulatory compliance for public capture.
- Safety-critical robotics perception
- Sector: Industrial Robotics, Automotive
- What: Use DA3 as a geometry foundation in autonomy stacks with formal reliability, uncertainty, and failover mechanisms.
- Tools/Workflows: Confidence-calibrated outputs → redundancy with classical sensors → certifiable runtime monitors.
- Assumptions/Dependencies: Extensive validation; certified development processes; multi-sensor redundancy for edge cases.
- Telepresence and interactive remote collaboration in 3D
- Sector: Enterprise Collaboration
- What: Real-time reconstruction of shared spaces for multi-user interaction, with pose-adaptive 3DGS for rendering.
- Tools/Workflows: Multi-camera ingestion → DA3 → low-latency streaming of 3DGS scenes → collaborative editing/annotations.
- Assumptions/Dependencies: Network QoS guarantees; hardware acceleration; dynamic-scene support desired.
- Unified world modeling for embodied AI agents
- Sector: AI/Autonomy
- What: Integrate DA3 geometry with language/action models for spatial reasoning, planning, and simulation-to-real transfer.
- Tools/Workflows: Geometry backbone → LLM policy → simulator alignment; curriculum across synthetic and real datasets.
- Assumptions/Dependencies: Cross-modal training; standardized interfaces; safety/interpretability constraints.
- Medical and scientific imaging extensions
- Sector: Healthcare, Scientific Research
- What: Adapt DA3 (with domain-specific training) for endoscopy, microscopy, or lab imaging scenarios requiring depth/pose consistency.
- Tools/Workflows: Domain adaptation → calibrated optics → 3D reconstructions for diagnostics or analysis.
- Assumptions/Dependencies: Specialized datasets, optics models; rigorous validation; regulatory approvals.
- Standards and procurement guidance for 3D capture in public projects
- Sector: Policy/Government
- What: Develop capture protocols, accuracy benchmarks, and archival formats based on DA3’s benchmark (pose, geometry, rendering).
- Tools/Workflows: Policy templates → conformity tests using DA3 benchmark → compliance reporting.
- Assumptions/Dependencies: Multi-stakeholder consensus; legal/privacy considerations; sustainable funding.
- End-to-end creator tools for 3D content at scale
- Sector: Media/Entertainment, Education
- What: SaaS platforms that ingest user photos and output ready-to-use 3DGS scenes, meshes, and renders.
- Tools/Workflows: Frontend capture → cloud DA3/3DGS pipeline → asset management → distribution to game engines and web viewers.
- Assumptions/Dependencies: Cost-effective cloud inference; robust content moderation; scalable storage/CDN.
- Environmental monitoring and inspection (longitudinal)
- Sector: Energy, Environmental Science
- What: Periodic multi-view captures to detect structural changes, erosion, vegetation growth, etc., via pose-aligned reconstructions.
- Tools/Workflows: Scheduled capture → DA3 reconstruction → change metrics (Chamfer/F1, precision/recall) → alerts.
- Assumptions/Dependencies: Stable capture protocols; weather/lighting variability mitigation; long-term data governance.
Notes on feasibility and dependencies that broadly affect applications:
- Scene rigidity is assumed in the current formulation; dynamic scenes require additional modeling.
- Camera intrinsics and image quality matter; pose conditioning improves results but is optional via ray-map inference.
- Best performance needs adequate view coverage and baselines; monocular depth is strong but multi-view improves fidelity.
- Compute: DA3 uses a transformer backbone; mobile or real-time use will benefit from quantization, distillation, and hardware accelerators.
- Data governance: images used for reconstruction may contain sensitive information; privacy, consent, and storage policies are necessary for public or consumer deployments.
Glossary
- 3D Gaussian Splattings (3DGS): A neural 3D representation that renders scenes using collections of Gaussian primitives for real-time novel view synthesis. "Application: Feed-Forward 3D Gaussian Splattings"
- Affine-invariant depth normalization: A normalization technique that makes depth predictions robust to affine transformations in scale and shift. "incorporate techniques such as affine-invariant depth normalization."
- Area Under the Curve (AUC): A summary metric computed from accuracy-threshold curves, used here to evaluate pose estimation performance. "report results using the AUC."
- Bundle adjustment: A global optimization in SfM that refines camera poses and 3D structure by minimizing reprojection error across images. "incremental or global SfM with bundle adjustment"
- Camera token: A learned or encoded token representing camera parameters that is concatenated with visual tokens for attention-based processing. "we prepend each view with a camera token ."
- Chamfer Distance (CD): A symmetric metric for measuring reconstruction accuracy by averaging distances from predicted to ground-truth points and vice versa. "The Chamfer Distance (CD) is then defined as the average of these two terms."
- COLMAP: A widely used SfM/MVS pipeline that estimates camera poses and reconstructs 3D geometry from images. "We use COLMAP camera poses provided by each dataset"
- Cost-volume networks: Deep architectures that build 3D cost volumes across views to infer dense depth in MVS. "cost-volume networks~\citep{yao2018mvsnet,xu2023iterative} for MVS replaced hand-crafted regularization with 3D CNNs,"
- Cross-view self-attention: An attention mechanism that exchanges information among tokens from different views to enable multi-view reasoning. "an input-adaptive cross-view self-attention mechanism"
- Depth-ray representation: A per-pixel formulation storing depth and a ray (origin and direction), enabling consistent 3D reconstruction without explicit pose prediction. "a depth-ray representation forms a minimal yet sufficient target set"
- Direct Linear Transform (DLT): A least-squares method to estimate projective transforms (e.g., homographies) from correspondences. "can be efficiently solved using the Direct Linear Transform (DLT) algorithm"
- DINOv2: A large-scale self-supervised vision transformer backbone used for feature extraction without architectural modifications. "vanilla DINOv2 model"
- Dual-DPT head: A decoder with shared reassembly and separate fusion branches that jointly predict depth and ray maps. "A dual-DPT head is used to predict depth and ray maps from visual tokens."
- Epipolar attention: An attention mechanism that leverages epipolar geometry constraints to improve multi-view aggregation for rendering or reconstruction. "geometry priors, e.g., epipolar attention"
- F1-score: The harmonic mean of precision and recall, used to summarize reconstruction quality at a given distance threshold. "we report the F1-score"
- Farthest point sampling: A selection strategy that chooses views maximizing mutual distance (in translation/rotation) to improve coverage. "apply farthest point sampling, considering both camera translation and rotation distances"
- Feed-forward novel view synthesis (FF-NVS): Rendering novel views in a single network pass without per-scene optimization. "we introduce a challenging benchmark for feed-forward novel view synthesis (FF-NVS), comprising over 160 scenes."
- Field of view (FOV): Camera parameters controlling angular extent of the image, typically represented by focal components. "FOV parameters ."
- Homography: A planar projective transform relating rays or points between camera frames via intrinsic and rotation matrices. "This establishes a direct homography relationship, "
- Iverson bracket: Notation that evaluates to 1 if a condition holds and 0 otherwise, used in defining precision/recall. "where denotes the Iverson bracket"
- LiDAR: Active laser sensing used to acquire dense depth for benchmarking and training datasets. "depth maps from iPhone LiDAR"
- Multi-View Stereo (MVS): Dense 3D reconstruction from multiple calibrated images by aggregating view-consistent depth. "Multi-View Stereo~\citep{seitz2006comparison}"
- NeRF: Neural radiance fields representing scenes as volumetric functions optimized for photorealistic rendering from novel viewpoints. "Early methods adopted NeRF as the underlying 3D representation"
- PatchMatch: A fast randomized correspondence algorithm commonly used in classical MVS pipelines. "compared with classical PatchMatch."
- Quaternion: A 4D rotation representation used to predict camera orientation stably. "rotation quaternion "
- RANSAC: A robust estimation method that fits models while rejecting outliers via random sampling consensus. "via RANSAC least squares"
- Relative Rotation Accuracy (RRA): A pose metric measuring angular error in relative rotation between image pairs. "Relative Rotation Accuracy (RRA)"
- Relative Translation Accuracy (RTA): A pose metric measuring angular error in relative translation between image pairs. "Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA)"
- RQ decomposition: A matrix factorization that recovers upper-triangular intrinsics and orthonormal rotation from a homography. "we can uniquely decompose using RQ decomposition to obtain , ."
- Simultaneous Localization and Mapping (SLAM): Techniques that jointly estimate camera trajectory and map geometry from sensor data. "Simultaneous Localization and Mapping~\citep{mur2015orb}"
- Structure from Motion (SfM): Recovering camera motion and sparse 3D structure from overlapping images. "Structure from Motion~\citep{snavely2006photo}"
- Spherical harmonic coefficients: Basis function parameters modeling view-dependent color for 3D Gaussians to improve rendering realism. "we replace per 3D Gaussian color with spherical harmonic coefficients"
- Teacher-student paradigm: A training setup where a teacher model provides pseudo-labels to supervise a student on diverse or noisy data. "We train Depth Anything 3 via a teacher-student paradigm"
- Truncated Signed Distance Function (TSDF) fusion: A volumetric method that integrates depth maps into a 3D grid for robust surface reconstruction. "by TSDF fusion."
- Vision Transformer (ViT): A transformer-based image encoder processing patch tokens through self-attention layers. "We use a Vision Transformer with blocks"
Collections
Sign up for free to add this paper to one or more collections.