- The paper introduces Depth Anything V2, which enhances monocular depth estimation by integrating synthetic data with pseudo-labeled real images.
- It implements a teacher-student architecture using advanced vision encoders like DINOv2-G to bridge the synthetic-to-real domain gap.
- The new DA-2K benchmark validates the model's superior accuracy and robustness across varied and challenging real-world settings.
Depth Anything V2: Advancements in Monocular Depth Estimation
Introduction
The paper "Depth Anything V2" (arXiv ID: (2406.09414)) introduces a new method for monocular depth estimation, namely Depth Anything V2, which aims to enhance the precision and robustness of depth predictions compared to its predecessor, Depth Anything V1. This improvement is achieved by leveraging synthetic images, scaling up model capacity, and utilizing pseudo-labeled real images to train student models. The proposed approach promises faster inference, fewer parameters, and higher accuracy compared to existing models based on Stable Diffusion.
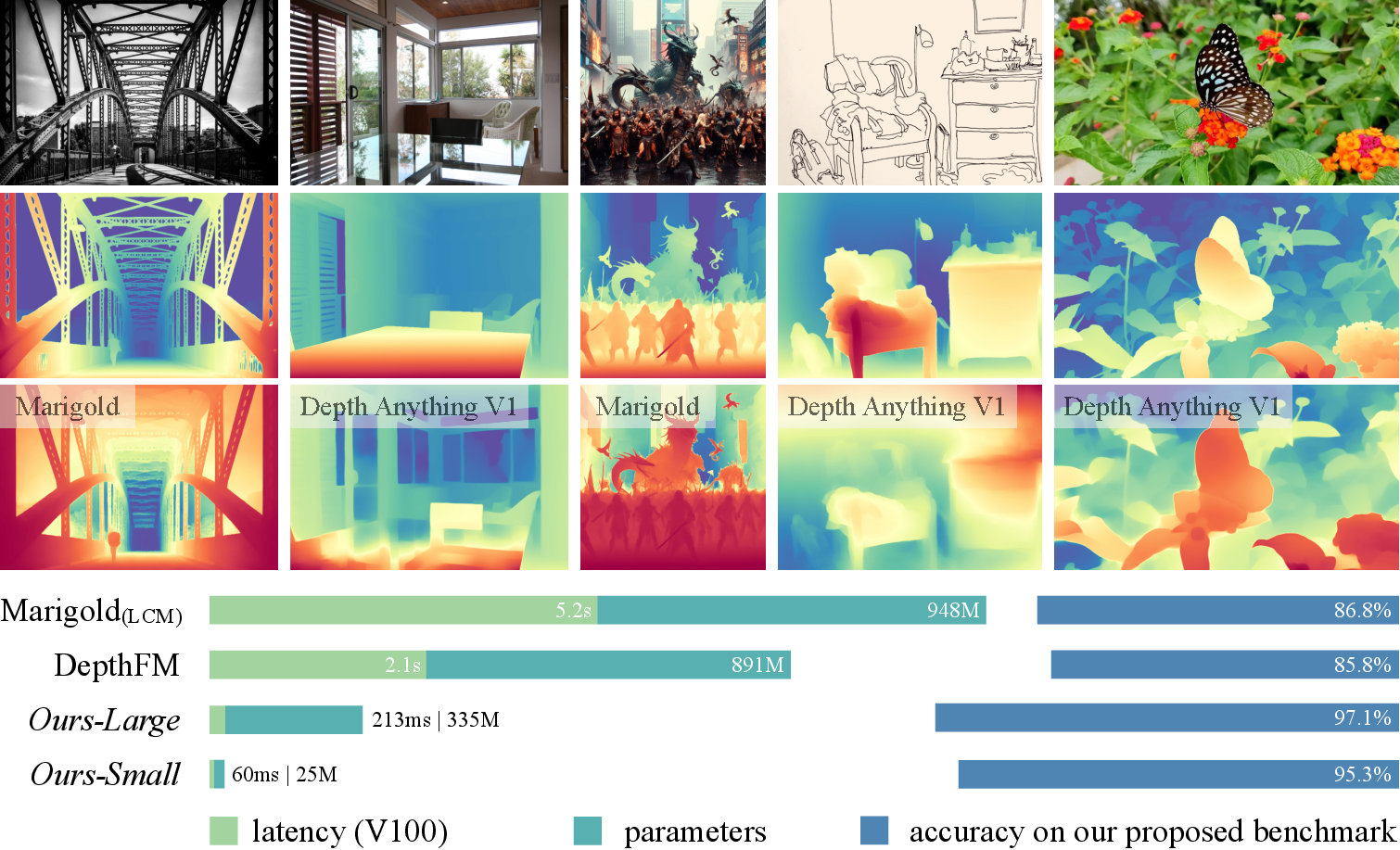
Figure 1: Depth Anything V2 significantly outperforms V1~\cite{depth_anything}.
Revisiting Real and Synthetic Data
The research details the drawbacks of real labeled images, particularly the presence of label noise and the inability to capture fine details in depth maps. Figures emphasize these shortcomings, such as missing details in tree and chair structures (Figure 2). In contrast, synthetic images provide highly precise depth annotations, capable of capturing intricate details and challenging scenarios like transparent and reflective surfaces.



Figure 2: Coarse depth of real data (HRWSI~\cite{hrwsi).
The adoption of synthetic data addresses the limitations of real datasets, but poses its own challenges, such as distribution shifts between synthetic and real images and limited scene diversity. The paper discusses how these challenges can be mitigated by scaling up the teacher model and leveraging large-scale pseudo-labeled real images to bridge the domain gap and enhance scene coverage.
Model Architecture and Training
Depth Anything V2 emphasizes training a capable teacher model using synthetic images, followed by generating pseudo-depth labels for a vast collection of unlabeled real images. Student models are trained using these pseudo-labeled images, facilitating robust generalization to real-world scenarios.
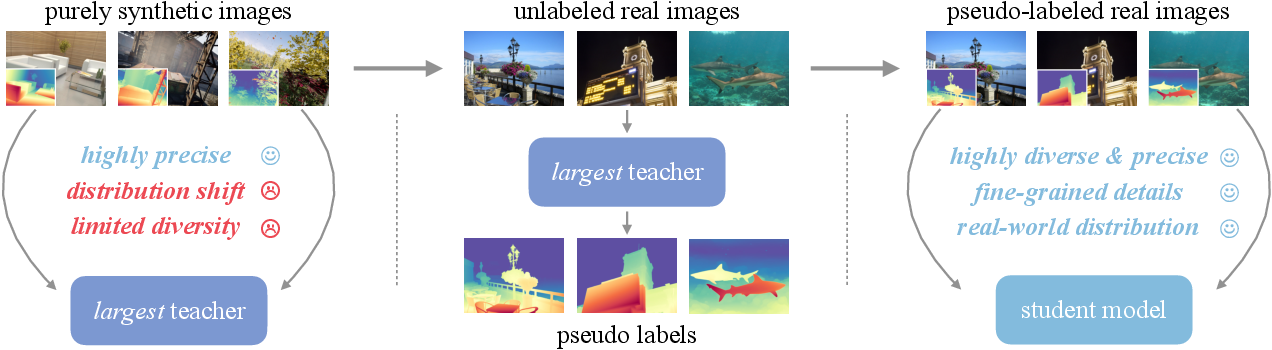
Figure 3: Depth Anything V2 pipeline.
The strategy of combining synthetic and pseudo-labeled real data enhances robustness and maintains fine-grained predictions even in complex scenes. Evaluation of various vision encoders highlights DINOv2-G as the most effective in the synthetic-to-real transfer, achieving superior predictions compared to other encoder models (Figure 4).

Figure 4: Qualitative comparison of different vision encoders on synthetic-to-real transfer.
Evaluation and Benchmarking
To address the noise and lack of diversity in existing test benchmarks, the authors propose DA-2K, a new evaluation benchmark featuring high-resolution images with precise sparse annotations. This benchmark offers a diversified set of scenarios, including indoor, outdoor, and adverse conditions.

Figure 5: Visualization of images and precise sparse annotations on our benchmark DA-2K.
Zero-shot depth estimation metrics across conventional benchmarks show Depth Anything V2 holds up well against MiDaS and Depth Anything V1. However, DA-2K results reveal superior accuracy of V2 models in diverse test scenarios, underscoring the benefits of using pseudo-labeled data.

Figure 6: Visualization of widely adopted but indeed noisy test benchmark~\cite{nyud).
Conclusion
Depth Anything V2 provides a compelling solution for monocular depth estimation, leveraging synthetic images for training robust models and bridging the domain gap with pseudo-labeled real images. This approach not only enhances depth accuracy and efficiency but also broadens the applicability of MDE models across varied scenarios. Future work should focus on further expanding the diversity of synthetic data and refining pseudo-labeling techniques to push the boundaries of depth estimation technology.

