DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas
Abstract: Simulating human profiles by instilling personas into LLMs is rapidly transforming research in agentic behavioral simulation, LLM personalization, and human-AI alignment. However, most existing synthetic personas remain shallow and simplistic, capturing minimal attributes and failing to reflect the rich complexity and diversity of real human identities. We introduce DEEPPERSONA, a scalable generative engine for synthesizing narrative-complete synthetic personas through a two-stage, taxonomy-guided method. First, we algorithmically construct the largest-ever human-attribute taxonomy, comprising over hundreds of hierarchically organized attributes, by mining thousands of real user-ChatGPT conversations. Second, we progressively sample attributes from this taxonomy, conditionally generating coherent and realistic personas that average hundreds of structured attributes and roughly 1 MB of narrative text, two orders of magnitude deeper than prior works. Intrinsic evaluations confirm significant improvements in attribute diversity (32 percent higher coverage) and profile uniqueness (44 percent greater) compared to state-of-the-art baselines. Extrinsically, our personas enhance GPT-4.1-mini's personalized question answering accuracy by 11.6 percent on average across ten metrics and substantially narrow (by 31.7 percent) the gap between simulated LLM citizens and authentic human responses in social surveys. Our generated national citizens reduced the performance gap on the Big Five personality test by 17 percent relative to LLM-simulated citizens. DEEPPERSONA thus provides a rigorous, scalable, and privacy-free platform for high-fidelity human simulation and personalized AI research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepPersona, a tool that creates very detailed, realistic “personas” (imaginative profiles of people) using AI. These personas aren’t short blurbs—they’re deep, story-rich profiles with hundreds of facts and traits, like a full character sheet for a movie or game. The goal is to help researchers and developers test and improve AI systems in a safe, privacy-friendly way, without using real people’s data.
What did the researchers want to find out?
The team had three simple goals:
- Make personas that cover many parts of a person’s life (not just a few traits like age and job).
- Make personas that are diverse and different from each other, not just copies with stereotypes.
- Keep each persona internally consistent, with a coherent backstory that feels realistic.
How did they do it?
They built DeepPersona in two stages. Think of it like building a detailed character in a role-playing game:
Stage 1: Build a giant map of human traits (a “taxonomy”)
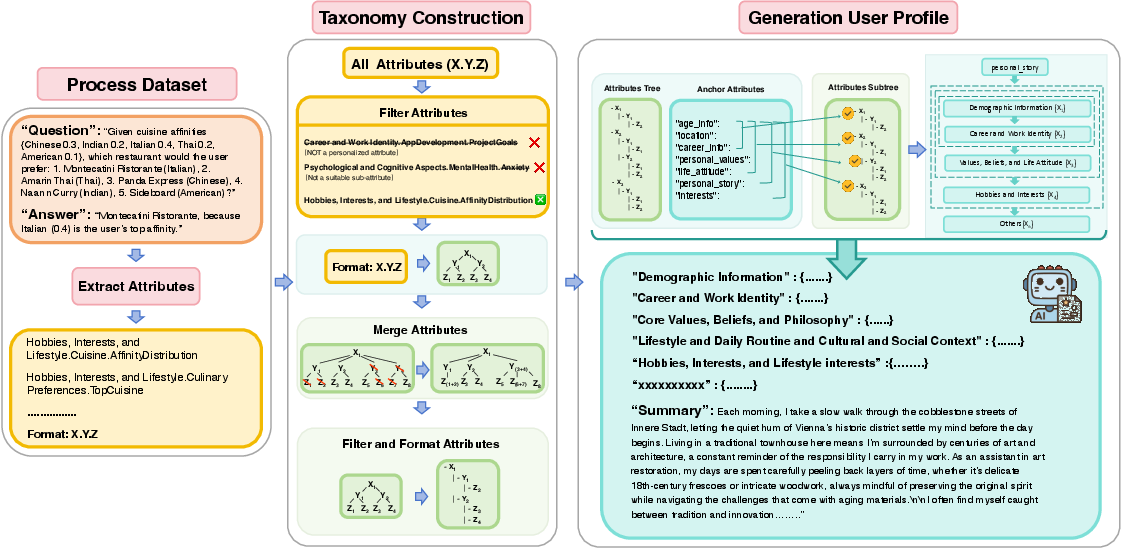
- Imagine a tree or map that organizes human attributes (like “Demographics → Education → College Major” or “Lifestyle → Food Preferences → Vegan”).
- To fill this map, they looked at thousands of real conversations where people talked about themselves to chatbots (from public datasets and model interactions). They extracted personalizable details and organized them into an 8,000+ node tree of human attributes.
- They cleaned and checked the tree to remove duplicates, fix mistakes, and keep only useful attributes.
Stage 2: Grow a persona step by step
- Start with anchors: a few core facts such as age, location, job, values, interests, and a short life story. This keeps the profile steady and plausible.
- For traits like age or gender, they sometimes use predefined lists (not the AI) to avoid bias and to ensure diverse coverage.
- Balance familiar with surprising: they pick new attributes based on how closely they relate to the core facts—some very related, some moderately related, and some intentionally different—so the persona stays coherent but not boring.
- Fill in the details progressively: the AI adds values (like specific hobbies or beliefs) one by one, always checking back to keep the whole profile consistent. Over time, this creates a narrative-complete persona—hundreds of structured attributes plus a long, readable story.
As a result, each persona feels like a unique, believable person with a rich backstory—and can be customized for different groups (like “college students in India” or “retirees in Australia”).
What did they find?
Here are the main results, presented simply:
- Deeper and more diverse personas:
- Coverage: DeepPersona includes 32% more kinds of attributes than strong baselines.
- Uniqueness: Personas are 44% more distinctive (less generic, less stereotyped).
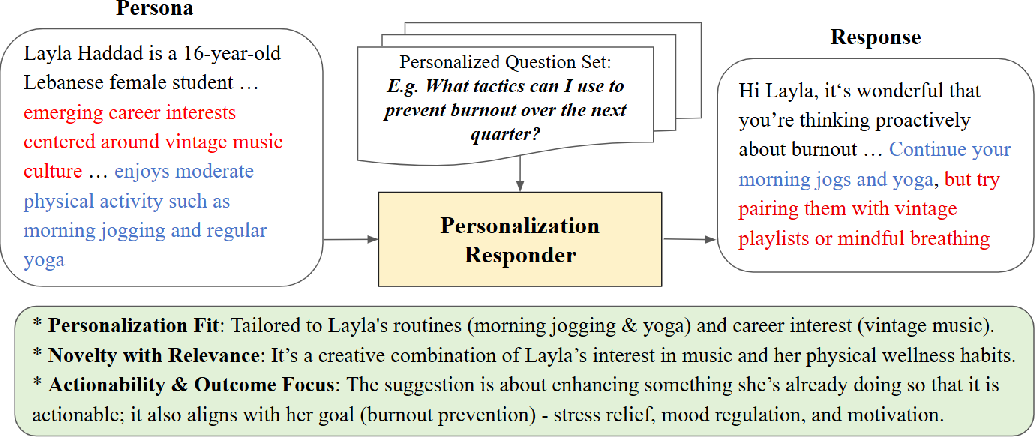
- Actionability: They are more useful for making personalized suggestions.
- Better personalization for AI:
- When AI models (like GPT-4.1-mini) are given DeepPersona profiles, their personalized answers improved by an average of 11.6% across ten quality metrics (like using the right details, giving better justifications, and offering relevant suggestions).
- Closer to real human survey responses:
- In social surveys (like the World Values Survey), synthetic populations created with DeepPersona reduced the gap from actual human responses by 31.7% compared to baseline methods.
- In the Big Five personality test, DeepPersona’s “national citizens” were 17% closer to real population results than personas made by standard LLM simulations.
- Right amount of detail matters:
- They tested how many attributes work best. About 200–250 attributes gave the strongest performance. Too few lacks richness; too many can add noise.
Why does this matter?
- Safer research: DeepPersona helps study human-like behavior without using real personal data, reducing privacy risks.
- Better AI personalization: Richer context helps AI give smarter, more tailored answers—like planning trips, making study plans, or offering health/lifestyle suggestions suited to the persona.
- More realistic simulations: For social science or policy testing, DeepPersona creates diverse, believable agent populations that behave more like real people, improving the quality of virtual experiments.
- Fairness and alignment: Because personas are diverse and structured, they can be used to test how AI performs across different groups, helping reduce stereotypes and bias.
In short, DeepPersona is like a “persona engine” that builds deep, coherent, and diverse character profiles at scale. This can improve how we personalize AI, simulate societies, and test systems—all while protecting privacy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for future research.
- Data source bias in taxonomy construction: The 8k-node Human-Attribute Tree is mined from ChatGPT-style user interactions (Puffin, prefeval_implicit_persona, HiCUPID), which likely over-represents English-speaking, tech-savvy users and specific genres of “ask-the-bot” self-disclosure. How does this skew attribute prevalence, salience, and cultural coverage?
- Limited multilingual/cross-cultural coverage: The pipeline appears English-centric; there is no evaluation of taxonomy breadth, attribute value realism, or generation quality for non-English languages or culturally specific attributes and norms.
- LLM-only labeling for “personalizable” QA pairs: The 62,224 pairs are triaged by GPT-4.1-mini without reported human inter-annotator agreement, calibration, or error analysis. What is the precision/recall of “personalizable” detection and its downstream impact on taxonomy quality?
- Semantic merge thresholds are under-specified: The tree-building relies on “semantic similarity thresholds” to merge hierarchies, but the metrics, thresholds, and error profiles (over-merging distinct attributes vs under-merging duplicates) are not quantified.
- Attribute abstraction granularity is subjective: The filtering that excludes “overly specific” leaves (e.g., brand variants) lacks formal criteria and audits. How do different abstraction policies change coverage, diversity, and downstream utility?
- No explicit measurement of logical consistency: Despite claiming “consistency,” there is no reported metric for contradiction rate across 200+ attributes (e.g., age vs career timeline, location vs nationality, health vs lifestyle). A scalable verifier/repair loop is missing.
- Joint-distribution realism is untested: Core demographics are sampled from tables, but the joint plausibility of multi-attribute combinations (e.g., age×education×career×location) is not validated against census-like distributions.
- Heuristic sampling ratio (5:3:2) lacks justification: The near/mid/far attribute selection ratio is introduced without hyperparameter sweeps, sensitivity analyses, or task-conditional tuning.
- Embedding choice and bias in “distance-to-core” sampling: The attribute-embedding space used to stratify attributes is unspecified (model, domain, multilinguality), and its bias effects on diversity/novelty are not studied.
- Breadth-first traversal with “sparsity prior” is opaque: The sparsity prior is not formalized or ablated. How does traversal policy affect attribute coverage, redundancy, and persona realism?
- Depth–quality tipping point is task-specific: The 200–250 attribute “sweet spot” is shown for one personalization setup; it’s unclear if this holds for other tasks (e.g., multi-agent interactions, recommendation, tutoring).
- LLM-as-judge evaluation risks circularity: Intrinsic metrics (attribute counts, uniqueness, actionability) and personalization metrics rely heavily on frontier LLM evaluators, which can prefer their own style. Cross-annotator human studies and open-source evaluators are limited.
- Limited details of human evaluation: The paper cites high win rates, but lacks sample sizes, annotator demographics, inter-rater agreement, and task prompts—hindering reproducibility.
- Under-specified “Actionability” metric: The 1–5 actionability score may conflate verbosity with utility. There is no task-grounded measurement of outcome improvements for real users or proxy tasks (e.g., success on goal completion).
- Sparse evaluation of stereotype/positivity bias: While bias-aware sampling is claimed, there is no measurement of stereotype prevalence, positivity bias, or minority misrepresentation within generated personas.
- Safety and sensitive attributes: The paper does not detail how protected or sensitive attributes (e.g., religion, health status, sexual orientation) are handled, guarded, or controlled ethically during generation.
- Privacy claims require substantiation: Although “privacy-free” is claimed, some datasets are derived from human–LLM interactions. Provenance, consent, anonymization rigor, and reidentification risks are not discussed.
- Reproducibility with closed models: Core steps rely on GPT-4.x family and Gemini evaluators. There is no evidence that open models reproduce taxonomy quality or generation fidelity, limiting replicability.
- Incomplete reporting of prompts and hyperparameters: Key prompts (labeling, extraction, filtering, generation), thresholds, and seeds are delegated to the appendix and not systematically audited or released with exact versions for reproducibility.
- Social simulation evaluation is narrow: WVS evaluation uses only six Likert questions per country with n=100 personas each; it’s unclear whether results generalize to more questions, more countries, longitudinal dynamics, or emergent multi-agent behaviors.
- Big Five evaluation inconsistencies: The Big Five results table appears partial/redundant and lacks coverage across nations and facets; methodology (scoring, reverse coding, sampling) and sample sizes are under-detailed.
- No longitudinal persona dynamics: The framework generates static personas. How to model life events, time-varying preferences, and gradual attitude changes coherently?
- Lack of behavior-grounded validation: Beyond surveys and prompting, there is no test of whether deeper personas yield more realistic agent behaviors in interactive simulations (e.g., markets, social networks, cooperative tasks).
- Cohort targeting and matching are unverified: While the toolkit claims controllable cohort synthesis, there is no quantitative test of distribution-matching to target demographics or constraints (and no measure of constraint satisfaction under conflicting anchors).
- Uncertainty quantification is absent: There is no notion of confidence or entropy over attribute values, nor tools to sample diverse consistent instantiations conditional on anchors.
- Scalability and resource cost: Generating ~1 MB narratives per persona raises cost/storage concerns. The paper does not report compute time, cost per persona, or throughput for scaling to millions of deep profiles.
- Failure analysis is missing: The paper does not catalog typical generation errors (contradictions, implausible combos, cultural faux pas), nor provide automated detection/repair modules.
- Domain-specific personas untested: Realism and utility in specialized domains (clinical, legal, financial, education) are not evaluated; domain constraints and compliance are unexplored.
- Fairness across intersectional identities: There is no audit of representation or quality for intersectional groups (e.g., age×disability×ethnicity), nor tools to guarantee equitable coverage or realism.
- Cross-model robustness is shallow: Model-agnostic claims are supported by a single-country ablation; broader cross-task, cross-language, and cross-backbone robustness remains unverified.
- Taxonomy maintenance and versioning: There is no process for updating, deprecating, or extending attributes, nor for community governance to correct errors and prevent drift.
- Schema standardization and interoperability: The attribute-value schema (types, constraints, units) is not aligned to existing ontologies, impeding integration with user modeling systems and knowledge graphs.
- Safety guardrails during generation: The pipeline does not specify content filters or refusal policies to prevent harmful, illegal, or exploitative outputs (e.g., personas of minors in adult contexts).
- Impact on downstream fairness and alignment: Deeper personas could amplify or mask biases in personalization or RLHF pipelines; there is no systematic study of fairness impacts or mitigation strategies.
- Potential overfitting to evaluation distributions: Improvements on WVS and Big Five may reflect alignment to those specific instruments; generalization to other psychometric or cultural benchmarks is untested.
- Release plan clarity: The paper promises code, taxonomy, and data, but does not specify licensing, redaction of sensitive nodes, or evaluation harnesses necessary for reproducible comparisons.
Glossary
- Admissible value space: The set of allowed values for a given attribute in the persona schema. "Each attribute possesses an admissible value space (e.g., categorical label, free-text, list, etc)."
- Agent-based social simulations: Simulations that use computational agents to model and study complex social behaviors. "Agent-based social simulations employ computational agents to emulate complex societal behaviors, such as opinion diffusion, cultural dynamics, and policy impacts~\cite{bonabeau2002agent}."
- Agentic behavioral simulation: Simulation of behavior by autonomous, agent-like systems to study or reproduce human-like actions. "Simulating human profiles by instilling personas into LLMs is rapidly transforming research in agentic behavioral simulation, LLM personalization, human-AI alignment, etc."
- Anchor set: A predefined set of attribute–value pairs or a short bio that constrains and guides persona generation. "Formally, let be an anchor set supplied by the user"
- Attribute-selector: The component that chooses the next attribute to fill during persona synthesis. "The instantiated taxonomy supplies the attribute-selector with coverage priors and hierarchical constraints, while the LLM generates each value conditioned on the evolving context to ensure global coherence."
- Big Five personality test: A psychometric assessment measuring five core personality traits (OCEAN). "Our generated ânational citizensâ reduced the performance gap on the Big Five personality test by 17\% relative to LLM-simulated citizens."
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them. "we embed all candidate attributes into a vector space and compute their cosine similarity with the pre-defined core attributes."
- Coverage priors: Prior probabilities encouraging balanced attribute selection across taxonomy regions. "The instantiated taxonomy supplies the attribute-selector with coverage priors and hierarchical constraints, while the LLM generates each value conditioned on the evolving context to ensure global coherence."
- Cultural Prompting: A prompting baseline that injects cultural context to guide model outputs. "the \"Cultural Prompting\" baseline from \citep{tao2024cultural}."
- ELO ratings: A comparative rating system (originating from chess) used to quantify performance differences. "evidenced by high win rates (81.2-87.0\%) and superior ELO ratings across all four key dimensions."
- Hierarchical constraints: Structural rules that enforce valid parent–child relations in the attribute taxonomy during selection. "The instantiated taxonomy supplies the attribute-selector with coverage priors and hierarchical constraints, while the LLM generates each value conditioned on the evolving context to ensure global coherence."
- Human-attribute taxonomy: A hierarchical catalog of human-descriptive attributes that guides persona construction. "we algorithmically construct the largest-ever human-attribute taxonomy, comprising over hundreds of hierarchically-organized attributes, by mining thousands of real user-ChatGPT conversations."
- IPIP inventory: A public-domain item pool commonly used to measure Big Five personality traits. "The questionnaire items were taken from the IPIP inventory\footnote{\url{https://ipip.ori.org/new_ipip-50-item-scale.htm}, and the corresponding ground-truth response data were obtained from OpenPsychometrics\footnote{\url{https://openpsychometrics.org/tests/IPIP-BFFM/}."
- Jensen-Shannon divergence: A symmetric information-theoretic measure of distance between probability distributions. "measured using four statistical metrics: Kolmogorov-Smirnov (KS) statistic, Wasserstein distance, Jensen-Shannon (JS) divergence, and Mean Absolute Difference (Mean Diff.)~\cite{mansour-etal-2025-paars}."
- Kolmogorov-Smirnov statistic: A nonparametric statistic that quantifies the maximum difference between empirical distribution functions. "measured using four statistical metrics: Kolmogorov-Smirnov (KS) statistic, Wasserstein distance, Jensen-Shannon (JS) divergence, and Mean Absolute Difference (Mean Diff.)~\cite{mansour-etal-2025-paars}."
- Likert-scale responses: Survey responses on an ordered categorical scale (e.g., 1–5) suitable for quantitative analysis. "Finally, the compact and quantitative nature of its Likert-scale responses yields comparable histograms, which facilitates rigorous analysis using statistical distance metrics."
- Long-tail (of human attributes): The many rare, low-frequency attributes beyond commonly observed traits. "an explicit taxonomy (i) exposes the long-tail of human attributes, (ii) constrains the selector to balanced coverage, and (iii) enables controllable anchoring."
- Model-agnostic: Independent of any specific model architecture or vendor. "To empirically validate the model-agnostic nature of DeepPersona and its effectiveness across diverse foundation models, we conducted a cross-model evaluation"
- Narrative-complete: Describing a persona with sufficient depth, diversity, and consistency to form a coherent life story. "We say a persona is narrative-complete when"
- Parameter-efficient user embedding fine-tuning: Personalization by training small, user-specific parameters instead of full model weights. "Prominent approaches include retrieval-augmented prompting~\cite{jiang2025know}, parameter-efficient user embedding fine-tuning~\cite{wang2024ai,braga2024personalized}, and hybrid architectures integrating external user memory stores."
- Progressive Attribute Sampling: An iterative procedure that selects and fills attributes to build deep, coherent personas. "Stage 2, Progressive Attribute Sampling (~\ref{sec:progressive_sampling}) for human profiles generation."
- Retrieval-augmented prompting: Enhancing prompts with retrieved external information to improve model outputs. "Prominent approaches include retrieval-augmented prompting~\cite{jiang2025know}, parameter-efficient user embedding fine-tuning~\cite{wang2024ai,braga2024personalized}, and hybrid architectures integrating external user memory stores."
- Self-disclosure QA: Question–answer pairs that elicit personal information from users. "Stage 1 builds a comprehensive Human-Attribute Tree by mining self-disclosure QA (left) and merging semantically validated paths (middle)."
- Sparsity prior: A bias that favors exploring less-populated or infrequent branches/features. "subject to a sparsity prior that favors long-tail branches, until the depth budget is met."
- Stochastic breadth-first traversal: A randomized BFS process used to traverse the taxonomy during attribute selection. "the selector performs stochastic breadth-first traversal: at each step, it randomly picks an unexplored child in , subject to a sparsity prior that favors long-tail branches, until the depth budget is met."
- Taxonomy-guided sampling strategy: Sampling attributes under the guidance of a hierarchical taxonomy to ensure balanced coverage and coherence. "DeepPersona systematically addresses these limitations through a taxonomy-guided sampling strategy, enhancing persona depth."
- Wasserstein distance: An optimal-transport metric measuring the cost to transform one probability distribution into another. "measured using four statistical metrics: Kolmogorov-Smirnov (KS) statistic, Wasserstein distance, Jensen-Shannon (JS) divergence, and Mean Absolute Difference (Mean Diff.)~\cite{mansour-etal-2025-paars}."
- World Values Survey (WVS): A large-scale international survey measuring people’s values and beliefs across countries. "To evaluate social simulation, we adopt the World Values Survey (WVS) as our framework, following \cite{tao2024cultural}."
Practical Applications
Practical Applications Derived from DeepPersona
DeepPersona introduces a taxonomy-guided, two-stage engine that generates narrative-complete, privacy-preserving synthetic personas with hundreds of structured attributes. Its demonstrated gains in attribute coverage, uniqueness, personalization impact, and social-survey fidelity enable a wide range of practical applications across sectors.
Immediate Applications
The following applications can be deployed now using the methods, assets, and evaluation findings in the paper.
Industry
- Product personalization and recommendations (Software, E-commerce, Media/Streaming)
- Use deep personas to benchmark recommender systems and personalization pipelines offline before user rollout; simulate diverse cohorts to detect overfitting to majority preferences.
- Tools/workflows: “PersonaOps” pipeline integrating DeepPersona → synthetic cohort generation → offline A/B tests → metric deltas (PF/AC/DS/JU/ACT) before production.
- Assumptions/dependencies: Access to the taxonomy and LLM; careful calibration to target markets; guardrails to avoid reinforcing stereotypes.
- Customer support and conversational assistants (Software, Contact Centers)
- Fine-tune or prompt-tune chatbots with deep personas to evaluate robustness across demographics and intent styles; reduce hallucinated “generic” advice by grounding in persona attributes.
- Tools/products: Persona-conditioned test harness; response-quality evaluator (10-metric rubric) integrated in CI.
- Assumptions/dependencies: LLM model choice affects outcomes; continuous auditing for bias and safety.
- Marketing segmentation and UX research (Advertising/MarTech, Product Design)
- Replace static buyer personas with deep synthetic cohorts for message testing, journey mapping, and UX task completion studies without PII.
- Tools/workflows: Synthetic panel generator + scenario scripts; coverage controls via taxonomy strata (near/middle/far).
- Assumptions/dependencies: External validation against small human samples to avoid segment drift; domain-specific attributes may need extension.
- Retail agents for pre-market A/B testing (Retail, E-commerce)
- Simulate agent shoppers with diverse goals/constraints to evaluate pricing, ranking, and promotion strategies.
- Tools/products: Agent Population SDK; alignment suite measuring distributional differences to human logs (e.g., KS, Wasserstein, JS).
- Assumptions/dependencies: Mapping persona attributes to shopping intents/tools; retailer-specific data schemas.
- Safety, fairness, and alignment stress testing (AI Safety, Compliance)
- Use diverse personas to red-team assistants for disparate treatment, exclusionary outputs, and value conflicts; quantify group-level alignment gaps.
- Tools/products: “Alignment Red Team Farm” that injects adversarial/value-diverse personas; distributional gap dashboards.
- Assumptions/dependencies: Governance to define protected groups and harm taxonomies; escalation workflows for found issues.
- Game development and interactive media (Gaming, Entertainment)
- Generate coherent NPC backstories, goals, and dialogue styles that remain consistent over long play sessions.
- Tools/workflows: Progressive sampling to balance novelty and coherence; BFS traversal with long-tail bias for variety.
- Assumptions/dependencies: Cost control for large persona corpora; runtime memory constraints for consoles/mobile.
- HR training and interview practice (Enterprise L&D)
- Create diverse candidate/customer personas for interviewer training, inclusion workshops, and conflict role-play.
- Tools/products: Scenario pack builder; evaluator prompts to score behavioral responses.
- Assumptions/dependencies: Clear disclaimers that personas are synthetic; avoid reinforcing harmful stereotypes; legal review.
- Finance chat and advisory testing (Finance)
- Evaluate robo-advisors across risk profiles, financial literacy levels, and cultural attitudes to advice-taking.
- Tools/workflows: Persona-to-risk mapping; outcome-focused evaluation (goal progress, effort reduction).
- Assumptions/dependencies: Compliance constraints; synthetic advice must be gated and not mistaken for licensed guidance.
Academia
- High-fidelity agent initialization for social/behavioral simulations
- Seed agent-based models with deep, coherent personas to reduce homogenization and capture minority views; improves survey replication (WVS) and psychometric fidelity (Big Five).
- Tools/workflows: Synthetic survey studio; distributional-gap metrics; country/region-conditioned cohorts.
- Assumptions/dependencies: Human validation samples; ethics review for synthetic population usage in publications.
- Benchmarks for LLM personalization and memory
- Build standardized personalization benchmarks leveraging 200–250-attribute personas; evaluate models on the paper’s 10-metric rubric.
- Tools/products: Open benchmark suite; persona-to-narrative generator and evaluator harness.
- Assumptions/dependencies: Transparent reporting to avoid evaluator overfitting; multi-model cross-checks.
- Taxonomy construction methods research
- Reuse/extend the 8k-node taxonomy for domain-specific studies (e.g., health, education); compare hierarchical merging strategies and semantic filtering quality.
- Assumptions/dependencies: Domain expert curation for specialized branches; provenance tracking.
Policy and Public Sector
- Survey instrument pretesting and bias detection
- Use deep synthetic cohorts to stress-test questionnaires for ambiguous wording, cultural bias, or high cognitive load before fielding.
- Tools/workflows: Likert distribution prediction and distance metrics; qualitative rationale extraction by evaluator LLMs.
- Assumptions/dependencies: Must not substitute for real sampling; use as pretest/triage only.
- Public communication rehearsal and crisis prototyping
- Simulate reactions from varied demographics to policy messaging; iteratively refine clarity and inclusivity.
- Assumptions/dependencies: Governance for persona coverage; documentation of synthetic nature to stakeholders.
Daily Life
- Personalized planning and coaching with explicit context
- Individuals can instantiate assistants with detailed, controllable profiles (values, constraints, routines) for travel, study plans, job search, or wellness routines.
- Tools/products: “Persona pack” templates; life-story-driven attribute filling; embedded justification for recommendations.
- Assumptions/dependencies: Users should review and edit generated attributes; prevent ossifying inaccurate self-views.
- Learning companions and role-play practice
- Generate culturally diverse debate partners or tutors tuned to one’s goals and motivation style.
- Assumptions/dependencies: Transparency that partners are synthetic; moderation for sensitive topics.
Long-Term Applications
These applications require further research, standardization, cross-domain scaling, or policy development.
Industry
- Synthetic population-driven product development and governance at scale
- Routine pre-rollout testing with large synthetic populations that approximate market heterogeneity; continuous calibration loops with small human samples.
- Potential products: SimulationOps platforms linking DeepPersona to analytics, causal inference, and risk dashboards.
- Dependencies: Regulatory acceptance of synthetic QA evidence; robust external validation frameworks.
- Persona-conditioned foundation model training and evaluation
- Train models to maintain long-horizon persona coherence; RLHF/RLAIF with persona diversity constraints to reduce stereotyping.
- Dependencies: Cost and data curation; safety guarantees; measurable generalization to real users.
- Sector-specific taxonomies and digital twins (Healthcare, Education, Finance)
- Build regulated, domain-safe personas (e.g., “synthetic patients,” “synthetic learners,” “synthetic savers”) for scenario planning and tool qualification.
- Dependencies: Strong domain ontologies; compliance (HIPAA/FERPA/FINRA); expert oversight.
- Marketplace of validated persona libraries
- Third-party curated personas with coverage guarantees and bias audits; contracts and SLAs for “persona quality.”
- Dependencies: Standards for persona schemas, audit methods, and reporting.
Academia
- Standardized, interoperable persona schema and metrics
- Community-led standards (e.g., via ACM/IEEE/W3C) for persona depth, diversity, and consistency; shared evaluators beyond LLM-as-judge.
- Dependencies: Inter-lab benchmarking initiatives; shared datasets with human baselines.
- Societal-scale simulations for longitudinal studies
- Multi-year synthetic cohorts with evolving life events to study policy shocks, technology adoption, and cultural drift.
- Dependencies: Methods for persona evolution (lifelong updates) without compounding bias; data synthesis ethics frameworks.
Policy and Public Sector
- Regulatory-grade stress testing of AI systems
- Use certified persona suites to demonstrate nondiscrimination, accessibility, and cultural responsiveness of public-facing AI.
- Dependencies: Policy guidance recognizing synthetic tests; certification bodies and audit trails.
- Policy impact forecasting with synthetic citizens
- Scenario analysis for proposed policies (tax changes, education reforms) via calibrated agent populations before costly pilots.
- Dependencies: Rigorous calibration to official statistics; transparency about uncertainty; human-in-the-loop review.
- Privacy-preserving data sharing and federated evaluation
- Agencies and NGOs share persona-derived evaluation artifacts instead of raw PII to enable collaborative oversight.
- Dependencies: Legal frameworks for synthetic data provenance and misuse prevention.
Daily Life
- On-device, privacy-preserving lifelong assistants
- Stable, evolving persona memories that remain on device but interoperate with cloud tools via controllable disclosures.
- Dependencies: Efficient models; memory management; user agency and safety-by-design.
- Health and counseling simulators for practitioners and trainees
- Rich, evolving synthetic patients/clients for supervised training; layered comorbidities and social contexts.
- Dependencies: Clinical validation; ethical guardrails; clear separation from real diagnostics.
Notes on Feasibility, Assumptions, and Dependencies
- Bias and representativeness: The taxonomy is mined from ChatGPT interactions and may reflect platform/user skew; ongoing calibration to real distributions is necessary.
- Model dependency: Quality varies by LLM; open-weight and API models should be cross-evaluated to avoid evaluator–generator coupling.
- Cost and scale: Generating ~200-attribute, ~1MB narratives is compute-intensive; batch generation, caching, and compression strategies are needed.
- Governance and ethics: Clear disclosure that personas are synthetic; prevent harmful stereotyping and misuse; align with sector regulations.
- Validation: Synthetic results should inform, not replace, human studies; maintain small, well-designed human validation loops to ground findings.
- Domain adaptation: Sector-specific attributes (health, finance, education) require expert-curated extensions and safety reviews.
Collections
Sign up for free to add this paper to one or more collections.

