- The paper introduces a training-free, per-instance optimization framework that leverages frozen 3D diffusion models as shape priors.
- It jointly optimizes geometry, texture, and joint parameters from sparse-view images to achieve high-fidelity, kinematically accurate 3D models.
- Experimental results on PartNet-Mobility demonstrate substantial improvements over state-of-the-art baselines with competitive optimization times on a single GPU.
FreeArt3D: Training-Free Articulated Object Generation using 3D Diffusion
Introduction
FreeArt3D presents a training-free framework for articulated 3D object generation, leveraging pre-trained static 3D diffusion models (notably Trellis) as shape priors. The method circumvents the need for large-scale articulated datasets and task-specific training by extending Score Distillation Sampling (SDS) into the 3D-to-4D domain, treating articulation as an additional generative dimension. Given sparse-view images of an object in different joint states, FreeArt3D jointly optimizes geometry, texture, and articulation parameters, producing high-fidelity, textured, and kinematically accurate 3D models.
Methodology
Per-Shape Optimization Paradigm
FreeArt3D operates on a per-instance optimization paradigm. For each object, the input consists of K RGB images {Ik}k=1K captured at different articulation states {θk}k=1K. The object is decomposed into a static body and a movable part, each represented by separate hash grids modeling occupancy fields. Joint parameters J (e.g., axis, pivot for revolute joints; axis for prismatic joints) and joint states θk are optimized alongside geometry.
Figure 1: FreeArt3D employs a per-shape optimization strategy, jointly optimizing body and part geometries, joint parameters, and optionally joint states from sparse-view images.
3D Diffusion Model Guidance
The optimization is guided by a frozen pre-trained 3D diffusion model (Trellis), which provides gradient signals for both geometry and joint parameters. At each iteration, the movable part is transformed according to the current joint state, merged with the static body, and the resulting occupancy grid is encoded and passed to the diffusion model. The SDS loss, computed in the latent space, distills denoising gradients from the diffusion model, while a voxel-space reconstruction loss stabilizes optimization.
Scale Normalization and Initialization
A critical challenge is scale inconsistency across joint states due to normalization in Trellis. FreeArt3D introduces a fixed reference disk beneath the object in all views, serving as a spatial anchor to ensure consistent scale and alignment.

Figure 2: Disk normalization ensures consistent component scales across joint states, stabilizing optimization.
Joint parameters are initialized via cross-state correspondences: Trellis is run independently on each input image, meshes are rendered, and 2D correspondences are detected and lifted to 3D. These are used to estimate initial joint parameters, which are then refined during optimization.
Fine-Grained Geometry and Texture Generation
After coarse optimization, occupancy grids are denoised and cleaned. The cleaned grid is used to construct a sparse latent feature volume, which is denoised and decoded by the second-stage Trellis model to produce FlexiCubes coefficients (for mesh extraction) and Gaussian Splatting parameters (for texture synthesis). Meshes for the static and movable parts are extracted and textured, then combined with optimized joint parameters to yield the final articulated object.
Experimental Results
Quantitative and Qualitative Evaluation
FreeArt3D is evaluated on the PartNet-Mobility dataset across 12 categories, using metrics including Chamfer Distance (CD), F-Score, CLIP similarity, joint axis direction error, and joint pivot error. The method significantly outperforms state-of-the-art baselines (Articulate-Anything, Singapo, URDFormer, PARIS) in all metrics, demonstrating superior geometric fidelity, texture realism, and kinematic accuracy.

Figure 3: Comparison between Singapo, Articulate-Anything, and FreeArt3D. FreeArt3D reconstructs detailed geometry and textures, closely matching input images and ground truth.
Runtime analysis shows FreeArt3D completes per-shape optimization in approximately 10 minutes on a single NVIDIA H100 GPU, which is competitive given the quality and generalizability achieved.
Real-World Applicability
FreeArt3D generalizes to real-world images captured with consumer devices, requiring only sparse views and no camera pose information. The disk normalization can be implemented physically or virtually.

Figure 4: FreeArt3D reconstructs high-quality articulated objects from casually captured, unposed real-world images.
Multi-Joint Extension
The framework is readily extensible to objects with multiple joints and mixed joint types by representing each part with a separate hash grid and jointly optimizing all geometries and joint parameters.
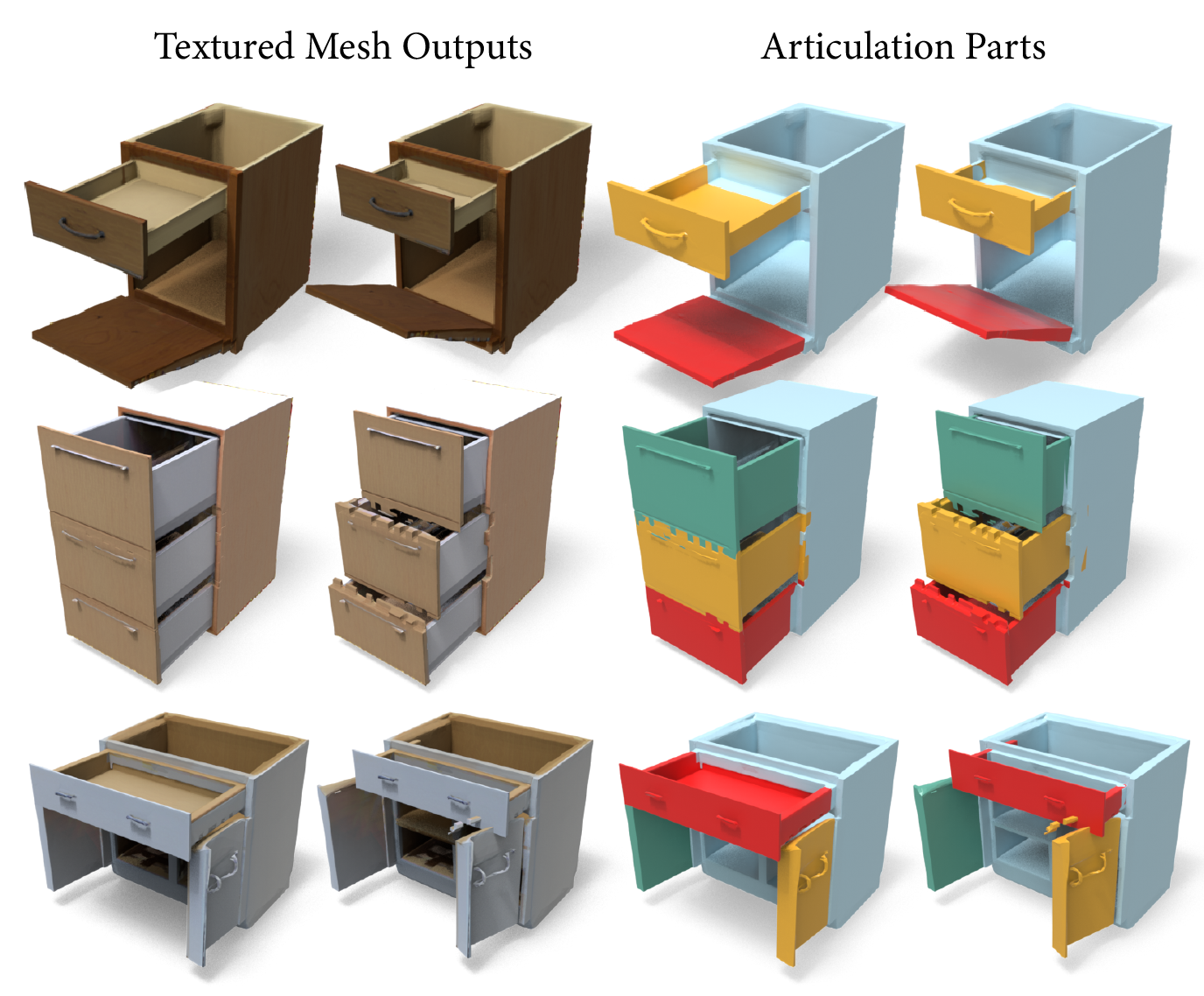
Figure 5: FreeArt3D supports generation of objects with multiple articulated parts and joints, enabling flexible configuration.
Ablation Studies
Ablation studies confirm the necessity of SDS loss, voxel loss, disk normalization, joint initialization, hash grid representation, and voxel refinement. Increasing the number of input views improves performance, while the method remains robust with minimal input.
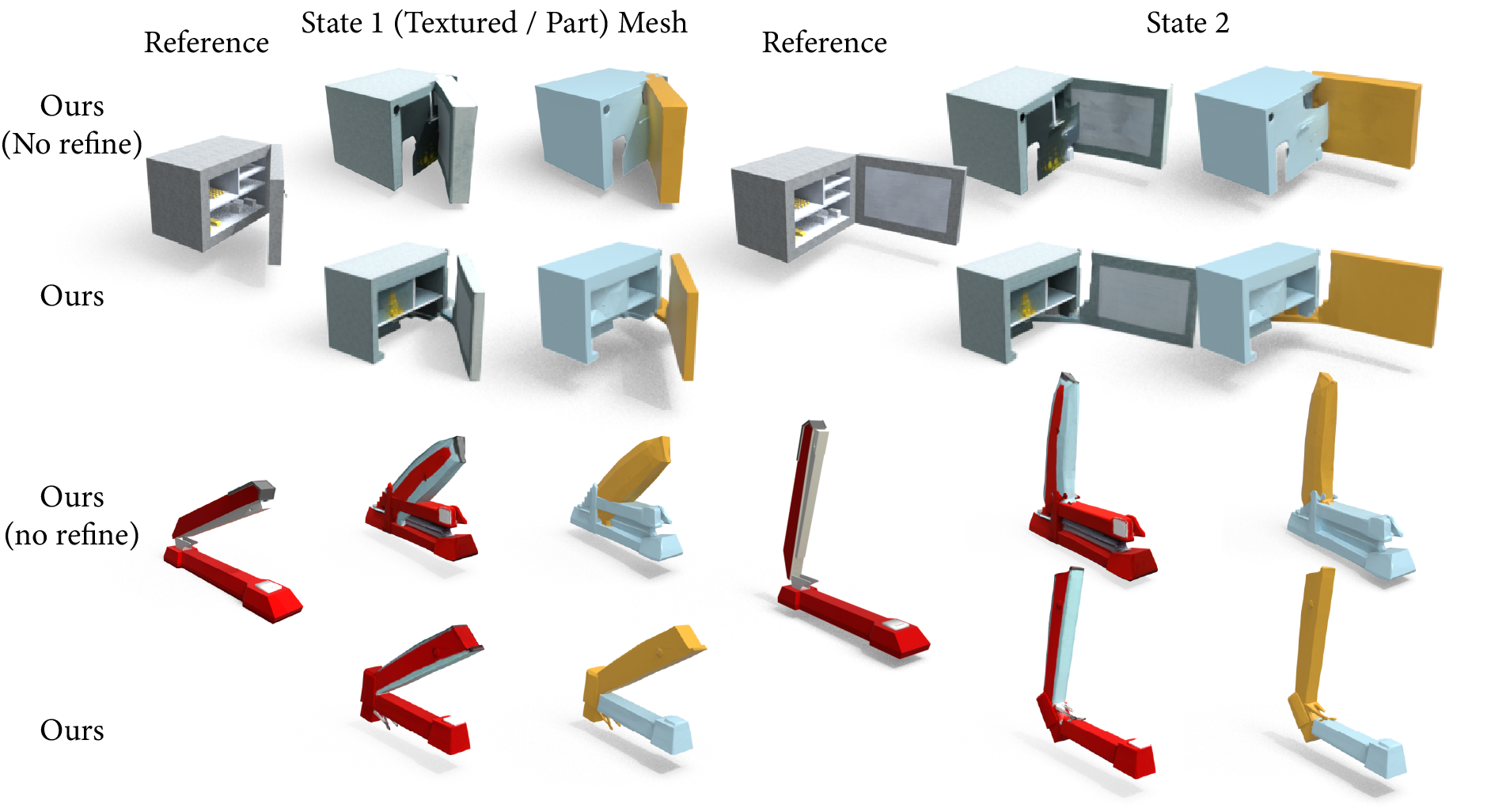
Figure 6: Ablation study demonstrates the impact of occupancy refinement after coarse geometry optimization.
Failure case analysis indicates robustness, with error rates below 10% for incorrect axis, pivot, or segmentation when using six input images and disk normalization.
Implementation Considerations
- Computational Requirements: The method is GPU-intensive, with per-shape optimization requiring several thousand iterations. Hash grid representation (TinyCudaNN) is recommended for efficiency and stability.
- Input Requirements: Sparse-view images in different joint states; disk normalization is essential for scale consistency.
- Generalizability: The approach is not limited by predefined categories or part templates, enabling open-world applicability.
- Limitations: Optimization speed and robustness could be further improved; normalization strategies may be refined for more complex scenes.
Implications and Future Directions
FreeArt3D demonstrates that training-free, per-instance optimization guided by static 3D diffusion models is a viable paradigm for articulated object generation, overcoming dataset scarcity and generalization limitations of retrieval-based and template-based methods. The approach is directly applicable to robotics, AR/VR, and digital twin pipelines, where accurate geometry, texture, and kinematic structure are critical.
Future work may focus on accelerating optimization, improving robustness to challenging input conditions, and exploring more sophisticated normalization and initialization strategies. Integration with large-scale 3D generative models and further automation of joint parameter estimation are promising directions.
Conclusion
FreeArt3D establishes a new standard for articulated 3D object generation, achieving high-fidelity geometry, realistic textures, and accurate kinematic modeling from sparse input views without task-specific training. The method's extensibility, generalizability, and real-world applicability position it as a practical solution for diverse applications in computer vision, graphics, and robotics.