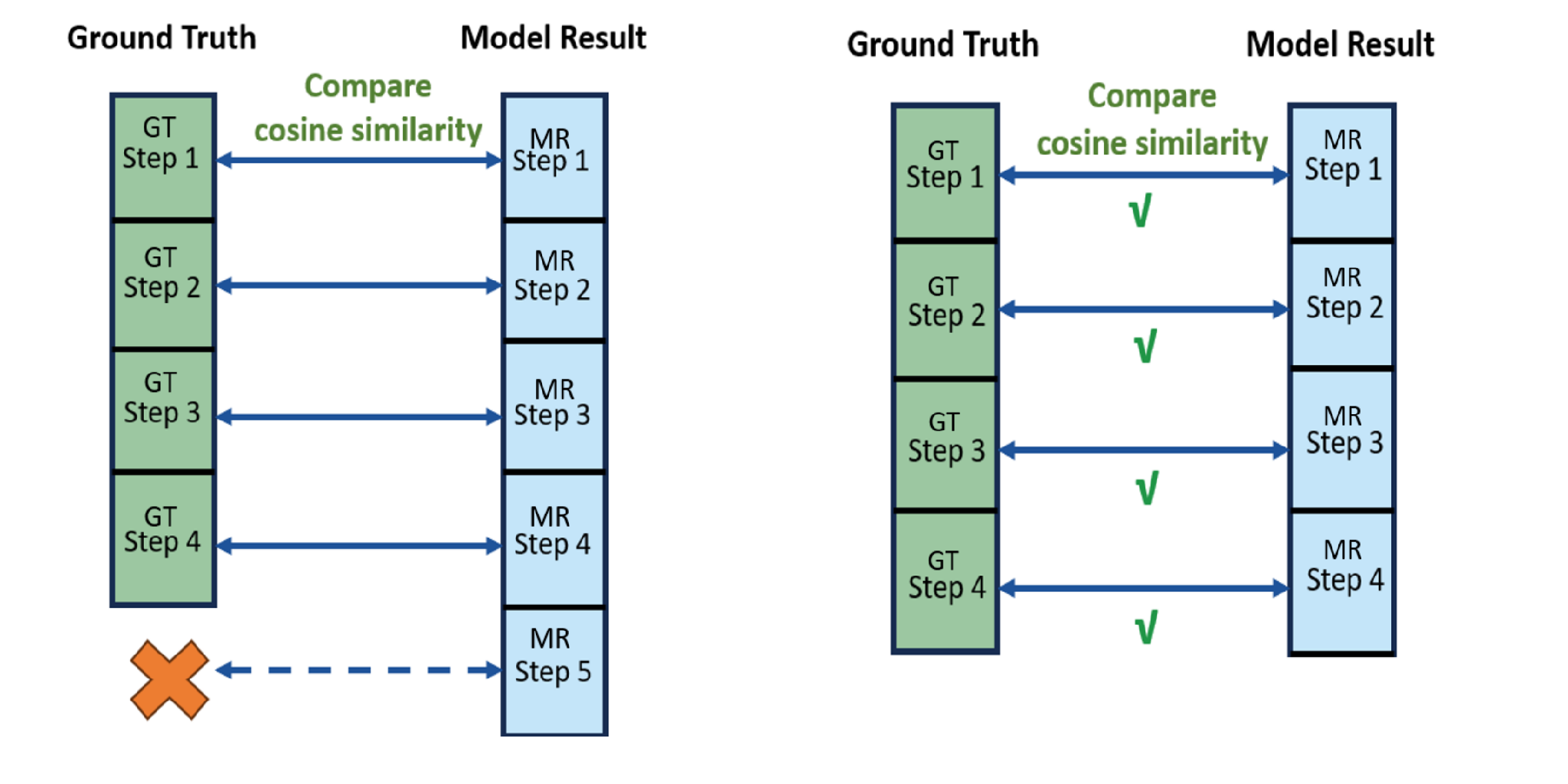
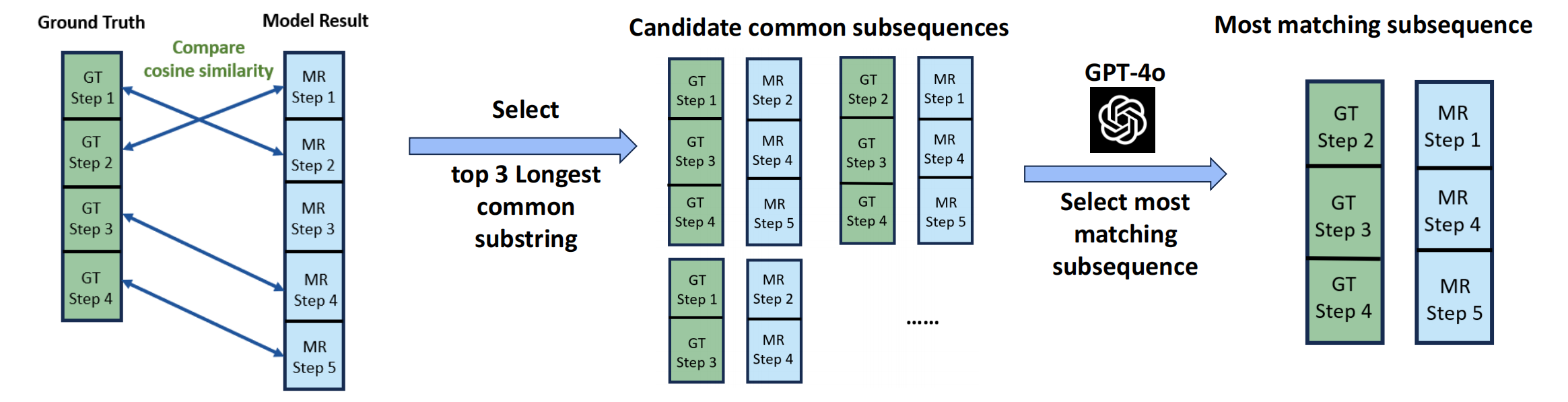
- The paper introduces a novel benchmark to evaluate LLMs' capability in turning abstract goals into exact VR controller and HMD operations.
- The evaluation employs rigorous metrics (SSM, NSAS, SOP, SSC) to reveal strengths in task decomposition and shortcomings in embodied, procedural reasoning.
- Results show that while LLMs perform well in structured tasks, they struggle with motor action mapping and spatial judgments compared to human players.
ComboBench: Evaluating LLMs on VR Device Manipulation
Introduction and Motivation
ComboBench introduces a rigorous benchmark for assessing the ability of LLMs to translate high-level semantic actions into precise physical device manipulations within Virtual Reality (VR) games. The benchmark comprises 262 scenarios from four diverse VR titles—Half-Life: Alyx, Into the Radius, Moss: Book II, and Vivecraft—each requiring the decomposition of abstract goals into fine-grained controller and HMD operations. The central research question is whether LLMs, trained primarily on textual data, can emulate the embodied reasoning and procedural skills that human players intuitively apply in VR environments.
The evaluation framework is grounded in a cognitive capability taxonomy, developed through expert interviews, encompassing six dimensions: task decomposition, procedural reasoning, spatial reasoning, object interaction/tool use, motor action mapping, and termination judgment. This multidimensional approach enables fine-grained analysis of LLM outputs, mapping specific errors to underlying cognitive deficits.
Benchmark Design and Annotation Pipeline
ComboBench scenarios are curated from detailed game walkthroughs, focusing on semantic actions that require multi-step device manipulation. Annotation is performed by experienced VR users, who record the exact sequence of controller and HMD operations necessary for each scenario. Each manipulation step is labeled with the engaged cognitive capabilities, leveraging a hybrid human-LLM annotation pipeline. Human annotators label a subset of data, which is then used as few-shot demonstrations for GPT-4o to scale the process. The pipeline achieves high agreement (89.7%) between LLM and human labels, with most steps engaging multiple capabilities—particularly motor action mapping and object interaction.
Gameplay videos are sourced or recorded to provide visual context and verification for each annotated sequence, ensuring the fidelity of the ground truth.
Evaluation Metrics
ComboBench employs four complementary metrics to assess LLM performance:
These metrics collectively capture precision, partial correctness, procedural fidelity, and semantic coverage, enabling nuanced diagnosis of model strengths and weaknesses.
Experimental Results
Seven LLMs are evaluated: GPT-3.5, GPT-4, GPT-4o, Gemini-1.5-Pro, LLaMA-3-8B, Mixtral-8x7B, and GLM-4-Flash. Human performance is included as a baseline. All models demonstrate strong task decomposition (NSAS > 0.75), but SSM scores remain low (<10%), reflecting the difficulty of exact sequence reproduction.
Gemini-1.5-Pro achieves the highest NSAS in three of four games and maintains the most balanced cross-game performance (Game Gap: 0.095). GPT-4o excels in procedural reasoning for Into the Radius (SOP: 0.291), but struggles in Half-Life: Alyx (SOP: 0.022). Performance is highest in Vivecraft (NSAS: 0.909–0.938), likely due to its discrete, block-based interactions, and lowest in Into the Radius, which demands nuanced spatial and inventory management.
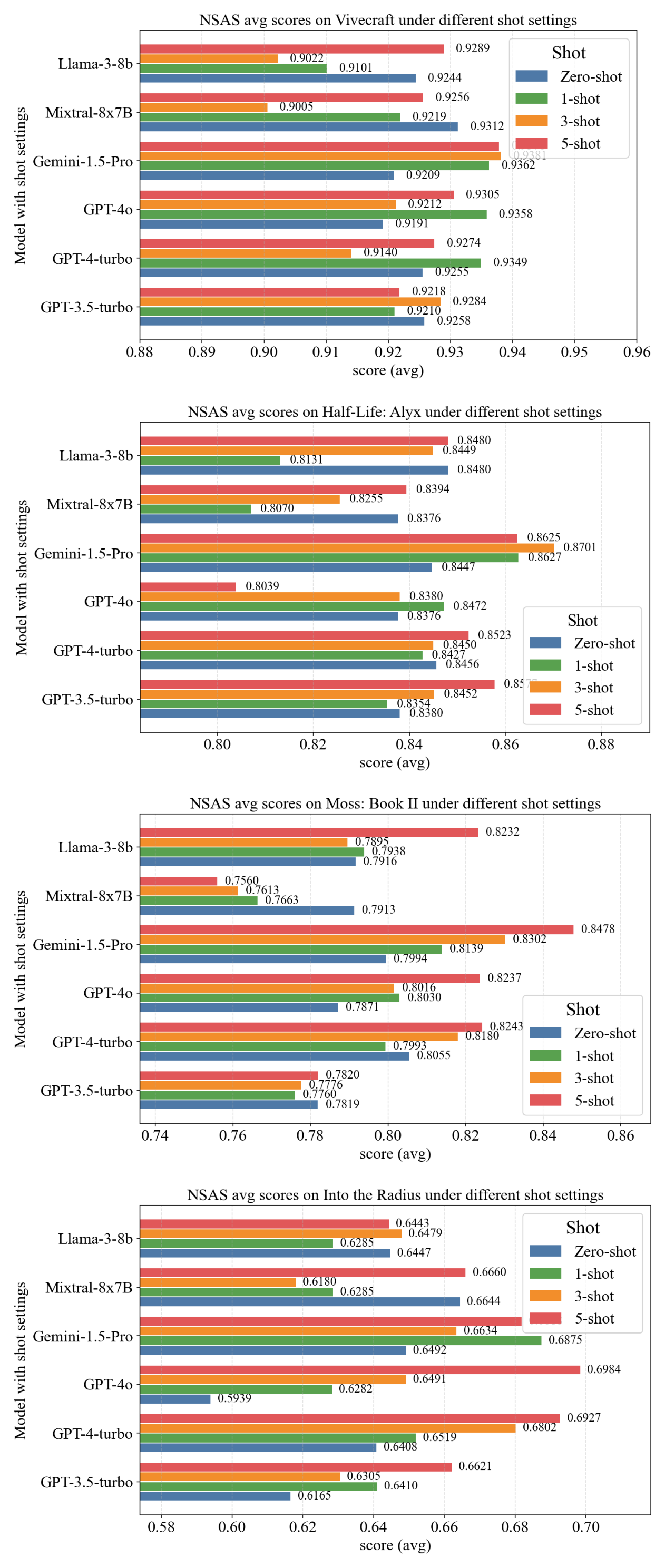
Figure 3: LLMs NSAS (avg) by Different Shot Setting Across Four VR Games.
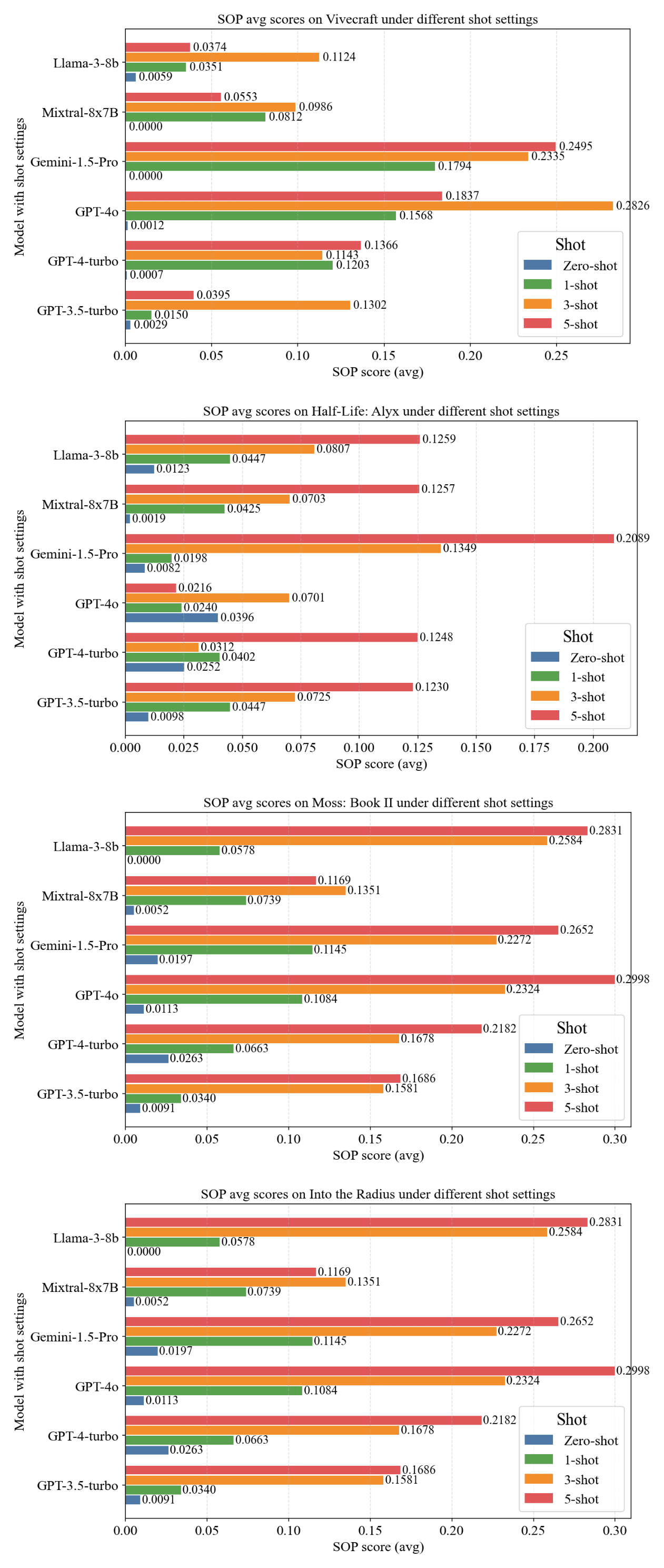
Figure 4: LLMs SOP (avg) by Different Shot Setting Across Four VR Games.
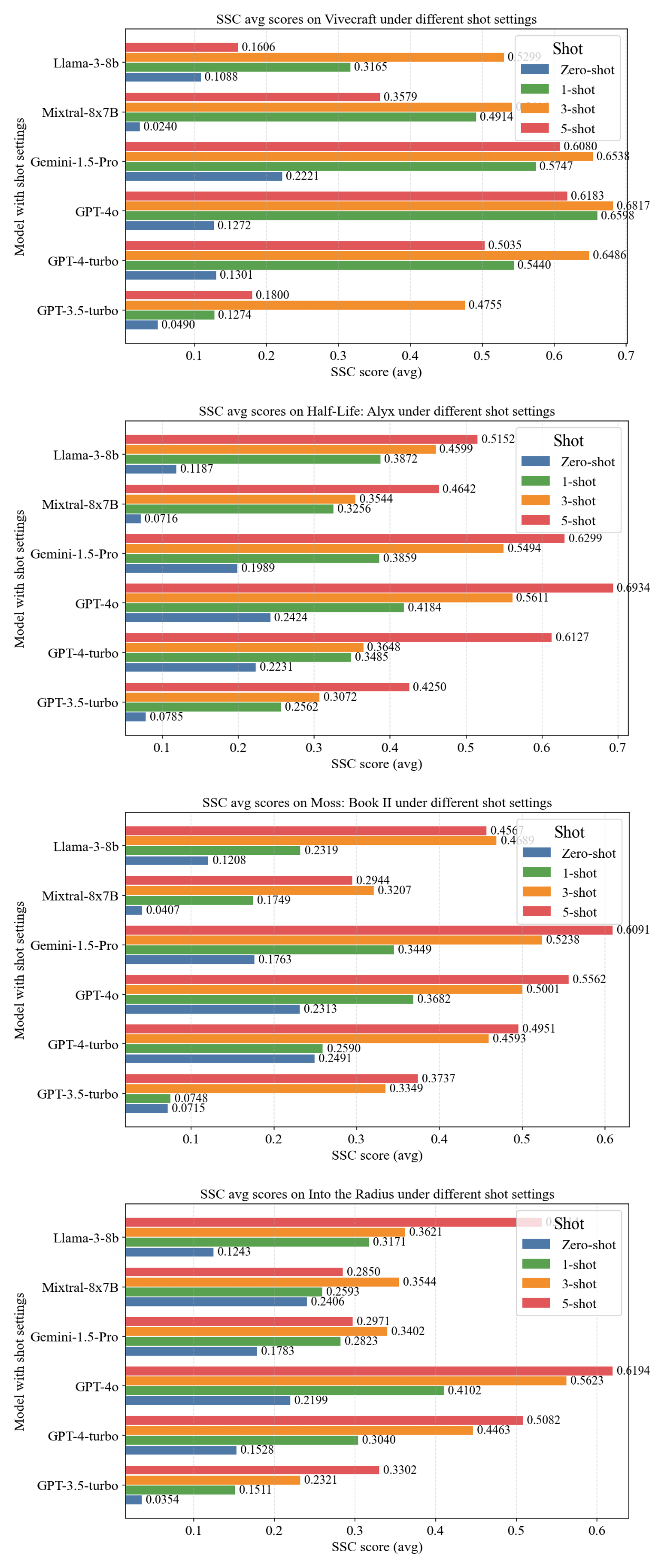
Figure 5: LLMs SSC (avg) by Different Shot Setting Across Four VR Games.
Impact of Few-Shot Examples
Few-shot prompting yields substantial improvements, especially in SOP (10–20x increase from zero-shot to 5-shot). The effect plateaus after three examples, indicating diminishing returns. NSAS and SSC see modest gains, while SSM remains challenging. Gemini-1.5-Pro demonstrates the strongest adaptability, achieving top scores with fewer examples.
Cognitive Capability Analysis
All models excel at task decomposition (scores 7.8–8.5/10), but motor action mapping is a persistent weakness (0.5–4.5/10). Procedural reasoning and termination judgment also lag behind human performance. Gemini-1.5-Pro is the most balanced, leading in procedural and spatial reasoning, but still falls short of human-level embodied intuition.
LLMs approach or exceed human NSAS in structured games (Vivecraft), but humans retain a decisive advantage in SOP and spatial reasoning, especially in complex environments. The performance gap is statistically significant (p<0.05), underscoring the limitations of text-trained models in embodied tasks.
Detailed Error and Variance Analysis
Models exhibit high variance across games and tasks, with robustness remaining a challenge. SOP scores degrade for later steps in sequences, reflecting poor temporal dependency modeling. Common errors include parallelization of sequential actions and omission of loop/termination conditions. Few-shot examples mitigate some procedural errors but do not fully resolve embodied reasoning deficits.
Implications and Future Directions
ComboBench reveals that current LLMs, despite strong semantic and decomposition skills, lack the embodied reasoning required for reliable VR device manipulation. The pronounced sensitivity to game mechanics and interaction complexity suggests that scaling text-only models is insufficient. Multimodal training incorporating spatial, visual, and haptic data, as well as architectural innovations for temporal and causal reasoning, are necessary to bridge the gap.
The benchmark provides a diagnostic tool for targeted model improvement and highlights the need for evaluation frameworks that capture multidimensional capabilities. Applications in accessibility, natural language VR interfaces, and intelligent tutoring are promising, but safety, privacy, and equity concerns must be addressed as LLMs gain greater agency in virtual and physical domains.
Conclusion
ComboBench establishes a comprehensive standard for evaluating LLMs on VR device manipulation, revealing both progress and persistent limitations. While models like Gemini-1.5-Pro demonstrate strong task decomposition and semantic alignment, procedural and embodied reasoning remain open challenges. Few-shot learning activates latent capabilities but does not overcome fundamental architectural constraints. Achieving human-level VR interaction will require multimodal, experiential training and new model designs, with broad implications for embodied AI in virtual and augmented reality.