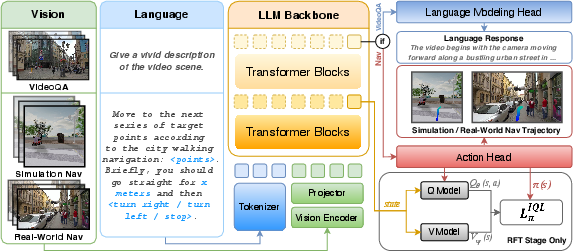
UrbanVLA: A Vision-Language-Action Model for Urban Micromobility
Abstract: Urban micromobility applications, such as delivery robots, demand reliable navigation across large-scale urban environments while following long-horizon route instructions. This task is particularly challenging due to the dynamic and unstructured nature of real-world city areas, yet most existing navigation methods remain tailored to short-scale and controllable scenarios. Effective urban micromobility requires two complementary levels of navigation skills: low-level capabilities such as point-goal reaching and obstacle avoidance, and high-level capabilities, such as route-visual alignment. To this end, we propose UrbanVLA, a route-conditioned Vision-Language-Action (VLA) framework designed for scalable urban navigation. Our method explicitly aligns noisy route waypoints with visual observations during execution, and subsequently plans trajectories to drive the robot. To enable UrbanVLA to master both levels of navigation, we employ a two-stage training pipeline. The process begins with Supervised Fine-Tuning (SFT) using simulated environments and trajectories parsed from web videos. This is followed by Reinforcement Fine-Tuning (RFT) on a mixture of simulation and real-world data, which enhances the model's safety and adaptability in real-world settings. Experiments demonstrate that UrbanVLA surpasses strong baselines by more than 55% in the SocialNav task on MetaUrban. Furthermore, UrbanVLA achieves reliable real-world navigation, showcasing both scalability to large-scale urban environments and robustness against real-world uncertainties.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces UrbanVLA, an AI “driver” for small urban robots (like delivery bots, assistive wheelchairs, or guide robots). UrbanVLA looks through the robot’s cameras, reads turn‑by‑turn directions from a map app, and then decides a safe, smooth path to follow for long distances in busy city sidewalks—without needing expensive, super-detailed maps.
What questions are the researchers trying to answer?
They focus on two big challenges:
- How can a robot follow long routes in messy, changing city spaces (crowds, bikes, dogs, street vendors) when map directions are often rough or a little wrong?
- How can a robot combine high-level instructions (“turn right in 30 meters”) with low-level skills (don’t hit people, don’t bump into poles, stay on the sidewalk) in one reliable system?
How does UrbanVLA work?
Think of UrbanVLA as a careful driver with three abilities: it reads directions, watches the road, and plans steering.
Turning map directions into “roadbooks”
Map apps (like Google Maps or Amap) give a route, but it’s often coarse and slightly misaligned with the real sidewalk. UrbanVLA turns that route into a “roadbook”—a short, structured description that includes:
- Nearby route waypoints (sampled points along the path ahead)
- A simple hint for the next change (“turn right in 30 meters”)
This makes directions easier for the AI to understand and match to what the cameras see.
Two-stage training: learn basics, then learn safety
The researchers trained UrbanVLA in two steps:
- Supervised Fine-Tuning (SFT): This is like showing the AI lots of “good driving” examples.
- Simulation: They used a city simulator (MetaUrban) with expert policies to teach goal-reaching and route-following.
- Web videos: They learned real-world scene understanding from travel videos (VideoQA), so the model recognizes urban features and situations.
- Heuristic Trajectory Lifting (HTL): Because perfect routes don’t exist in the real world, they deliberately make training routes a bit “noisy” (slightly off) so the AI doesn’t overfit and learns to handle imperfect directions.
- Reinforcement Fine-Tuning (RFT): This is like telling the AI what gets points or loses points and letting it adjust.
- They used Implicit Q‑Learning (IQL), an offline RL method, to learn from recorded driving data (both simulation and real robot teleoperation), not risky trial‑and‑error on the street.
- Rewards are simple and practical:
- Gain points for making progress along the route,
- Lose points for collisions,
- Lose points for drifting too far from the route corridor.
- This improves safety behaviors (avoiding people and obstacles, following sidewalk etiquette).
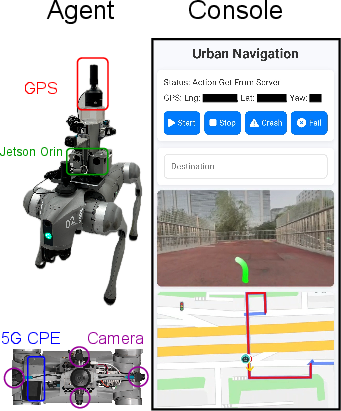
How it runs on a robot
- Cameras: The robot has multiple cameras (front, left, right, rear) to see its surroundings.
- Vision-LLM: An LLM (similar to advanced chatbots) and strong vision encoders process both the “roadbook” and the recent camera frames.
- Actions: Instead of tiny steering commands, UrbanVLA outputs a short local trajectory—waypoints that tell the robot exactly where to go next (like drawing a smooth path a few meters ahead).
What did they find?
In both simulation and real-world tests, UrbanVLA performs strongly:
- In the MetaUrban simulator:
- Point Navigation (getting to the goal): Very high success rates (about 94–97% SR) and efficient paths (high SPL), beating strong baselines by large margins.
- Social Navigation (being polite and safe around pedestrians): UrbanVLA achieved much higher social navigation scores, even though it used only cameras (RGB) while many baselines used LiDAR sensors.
- Overall improvement: The paper reports more than 55% better performance than baselines on the SocialNav task.
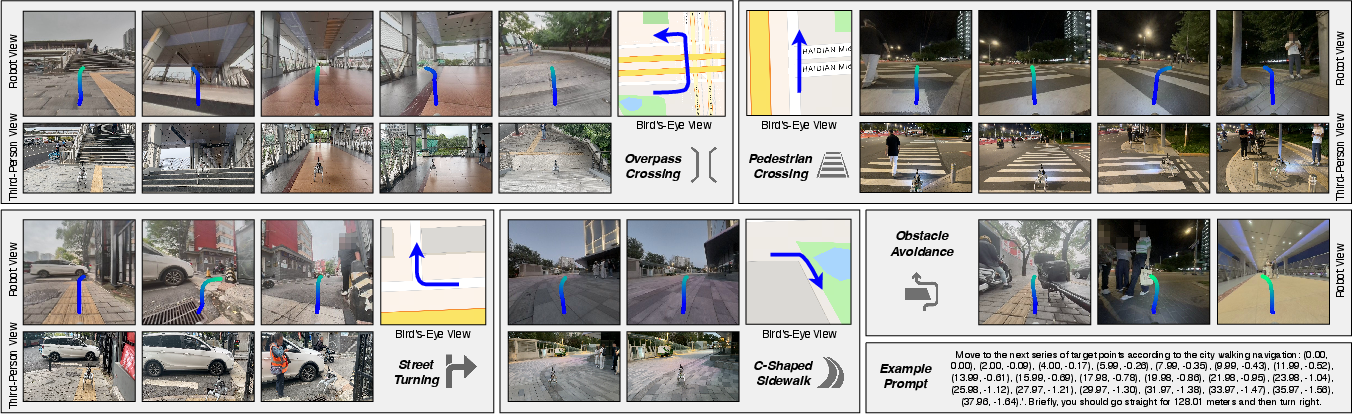
- In real city blocks:
- It generalizes to new places (zero-shot), handles different lighting (including night), and completes long route segments (over 500 meters).
- It aligns map directions with actual sidewalks, makes correct turns at intersections, crosses overpasses, and avoids dynamic obstacles like pedestrians and bikes.
They also ran ablations (tests turning features on/off):
- Without the HTL “noisy route” training, the model did a bit better in the simulator but failed much more in the real world—because it over-relied on perfect directions that don’t exist outside simulation.
- Adding the RL safety fine-tuning (IQL) improved success rates and reduced collisions, especially in unseen environments.
Why is this important?
If small urban robots are going to help in everyday life—bringing packages, guiding people, assisting mobility—they must be:
- Safe around pedestrians,
- Able to follow long, complicated routes,
- Robust to imperfect map data and changing surroundings,
- Scalable without building costly, ultra-detailed maps for every block.
UrbanVLA shows a practical path forward: combine the “eyes” (cameras), the “instructions” (map routes), and an “AI driver” (vision‑language‑action model) trained first on large examples and then tuned for safety with offline RL. This could make real-world deployments more reliable, reduce the need for expensive mapping, and speed up the rollout of helpful micromobility robots in cities.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Real-world quantitative evaluation is limited: provide standardized, large-scale metrics (e.g., SR, SPL, collision rate, SNS) across diverse conditions (day/night, rain/snow, glare, occlusions, varying crowd densities) rather than primarily qualitative demos and a single 60 m scenario.
- Dependence on consumer navigation APIs (e.g., Amap) is under-characterized: systematically measure and model the typical error and topology mismatch between car-road route outputs and pedestrian/micromobility corridors (sidewalks, overpasses), and evaluate alignment algorithms under these mismatches.
- Heuristic Trajectory Lifting (HTL) lacks validation against real misalignment statistics: empirically estimate the distribution of waypoint errors from navigation apps and calibrate HTL noise models to match real-world misalignments; compare HTL to learned route-abstraction methods.
- Safety and legal compliance are not rigorously assessed: incorporate detection and policy adherence for traffic signals, crosswalk rules, signage, and regional regulations; create and evaluate benchmark tasks with explicit legal compliance metrics beyond SNS.
- Baseline comparability is potentially confounded: re-run baselines with matched observation modalities (RGB vs LiDAR) and matched action spaces (trajectory vs low-level controls), and include VLA-based baselines to ensure apples-to-apples comparisons.
- Limited real-world dataset (∼8 hours) constrains generalization claims: collect and release larger, multi-city, multi-season, multi-embodiment datasets with annotated corner cases (e.g., construction zones, GNSS-denied areas, crowded events).
- Planning at 2 Hz with remote-server inference introduces latency risks: quantify end-to-end latency, jitter, packet loss effects, and network failures; evaluate on-board deployment, model compression, and real-time performance guarantees.
- Robustness to adverse environmental conditions is not systematically studied: conduct controlled experiments for nighttime, glare, heavy rain/snow, fog, lens contamination, and extreme illumination changes; explore domain adaptation and augmentation strategies tailored to these conditions.
- Sensor fusion is underutilized: investigate integrating GNSS, IMU, wheel odometry, and visual odometry into the policy (not only for logging) and quantify their impact on robustness, especially in urban canyons or GNSS-degraded settings.
- Trajectory feasibility and control integration are not formally addressed: ensure generated trajectories respect kinematic/dynamic constraints, actuator limits, and stability margins; include a verification layer or safety filter and report its impact.
- Multi-agent interaction modeling is shallow: evaluate in high-density pedestrian flows with varied behaviors (overtaking, merging, stopping), and integrate predictive crowd models or social force models to improve anticipatory navigation.
- LLM hidden-state selection for value estimation is heuristic: perform a systematic study of which transformer layers/states best capture task-relevant state representations and analyze how this choice affects Q/V stability and policy performance.
- Reward design is simplistic and under-analyzed: ablate the weights and components (completion, collision, deviation), test continuous proximity-based penalties and comfort costs, and evaluate reward shaping effects on safety vs efficiency trade-offs.
- No online adaptation or continual learning: explore safe online RL, human-in-the-loop interventions, and meta-learning to adapt to evolving environments, policies, and infrastructure changes without catastrophic forgetting.
- Robustness to route errors/unavailability is not covered: design fallback strategies for missing, stale, or contradictory route instructions (e.g., local exploration, on-device replanning, map-light priors) and evaluate their effectiveness.
- Corner detection for route segmentation is heuristic and may fail on complex layouts: compare with learned segmentation, graph-based topology inference, or map-assisted corner/turn detection; quantify segmentation errors’ effect on navigation.
- Cross-embodiment generalization is not systematically evaluated: measure performance across varied platforms (wheelchairs, delivery bots, strollers), sizes, and dynamics, and study embodiment-conditioned policies or adapters.
- Long-horizon scalability beyond ∼500 m is unquantified: test kilometer-scale routes, quantify drift and compounding errors, and evaluate memory/context strategies beyond sliding windows (e.g., hierarchical memory or episodic memory modules).
- Failure mode analysis is missing: provide a taxonomy of failure cases (e.g., misaligned turns, late obstacle avoidance, GNSS dropouts), root-cause analyses, and targeted fixes; report near-miss statistics and safety margins.
- Privacy, ethics, and regulatory considerations are not discussed: assess compliance for pedestrian video capture, data retention, and deployment in public spaces; outline consent, safety auditing, and transparency mechanisms.
- Hybrid map integration is unexplored: study lightweight map priors (e.g., sidewalk graphs, curb ramps, crossings) to augment route-conditioned policies without full HD maps, and quantify the benefit-cost trade-off.
- Reproducibility details are sparse: publish code, models, training configs (e.g., sliding window length k, waypoint count N, loss weights), and detailed dataset splits to support replication and fair benchmarking.
- Compute and energy footprint are unreported: measure inference latency, throughput, and power usage on embedded hardware; propose and evaluate model compression/distillation strategies for real deployment.
- Missing comparisons to contemporary VLA navigation models: include direct benchmarks versus recent route-conditioned or instruction-following VLAs (e.g., NavID, NaViLA, StreamVLN) on the same tasks to contextualize gains.
- Localization reliability is under-tested: evaluate performance under GNSS-denied or multipath-heavy conditions; integrate and benchmark visual-inertial odometry and loop-closure for pose stabilization.
- Safety guarantees are absent: investigate formal verification, risk-aware planning, or control barrier functions layered onto VLA outputs; report provable bounds or empirical safety rates under standardized stress tests.
- Language robustness is untested: since “roadbooks” are linguistic, evaluate multilingual, paraphrased, and noisy instruction variants; study alignment robustness and instruction grounding errors.
- Infrastructure change handling is unaddressed: design mechanisms for fast adaptation to construction, temporary blockages, and pop-up obstacles, including detection, route re-interpretation, and safe detours.
- Metric suitability for urban micromobility is uncertain: validate that SNS and cumulative cost capture social comfort and legal compliance for sidewalks; propose micromobility-specific metrics (e.g., pedestrian comfort indices, rule adherence scores).
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with current capabilities demonstrated by UrbanVLA’s route-conditioned VLA, two-stage SFT+RFT training pipeline, and sim-to-real generalization.
- Logistics and Delivery — Sidewalk delivery robots
- Description: Replace HD-map-dependent navigation with route-conditioned trajectory generation using consumer navigation APIs (e.g., Google Maps/Amap), enabling long-horizon pedestrian-area delivery with obstacle avoidance and social compliance.
- Tools/workflows: “UrbanVLA Navigator” ROS module; roadbook ingestion from map APIs; multi-camera RGB perception; HTL-based route abstraction; offline IQL fine-tuning with teleoperation data; monitoring/annotation console.
- Assumptions/dependencies: Reliable map API access and GNSS; multi-camera hardware and adequate compute (edge GPU or remote GPU with low-latency link); local sidewalk-robot regulation and privacy compliance; 2 Hz control sufficient for robot speed.
- Healthcare — Assistive powered wheelchairs for outdoor/campus navigation
- Description: Voice- or app-driven route following on sidewalks and campus paths with turn-by-turn “roadbooks,” maintaining social distance and avoiding obstacles.
- Tools/workflows: Roadbook voice interface; safety-aware reward design (completion/collision/deviation); supervised video-based SFT paired with real-world teleoperation data; configurable “route corridor” constraints.
- Assumptions/dependencies: Medical device compliance and risk controls; accessible outdoor GNSS; policies allowing semi-autonomous mobility aids; caregiver supervision for edge cases.
- Education/Campus Operations — Mail and goods delivery robots
- Description: Campus-wide robot couriers follow consumer-navigation routes and adapt to changing layouts without HD maps; robust to illumination and dynamic pedestrian flows.
- Tools/workflows: Amap/Google route-to-roadbook converter; fleet dashboards; teleop-assisted data collection for RFT; MetaUrban-based simulation training for campus replicas.
- Assumptions/dependencies: Campus permissions; on-campus connectivity; periodic teleop support for corner cases; safety logs auditable with SNS metrics.
- Facilities and Security — Patrol and inspection robots
- Description: Long-route perimeter patrols and sidewalk inspections with mapless navigation and incident-aware rerouting using visual cues.
- Tools/workflows: Patrol “roadbook scheduler”; anomaly tagging via VideoQA head; offline RL with safety-focused rewards; UI for route completion tracking.
- Assumptions/dependencies: Stable GPS coverage outdoors; night-time RGB robustness or auxiliary lighting; clear policy for recording in public spaces.
- Municipal/Smart City — Sidewalk maintenance and accessibility surveys
- Description: Robots traverse city blocks to document obstructions (e.g., scooters, trash bins), curb cuts, and crosswalk conditions, while complying with social navigation standards.
- Tools/workflows: City “survey roadbook” generator; cloud console for annotation; SNS-based compliance reporting; HTL for noisy route alignment.
- Assumptions/dependencies: City permits; data privacy and incident response policies; consistent access to navigation APIs across districts.
- Retail/Hospitality — Hotel/resort service robots
- Description: Outdoor resort paths and mixed indoor–outdoor promenades navigated using route-conditioned trajectories for delivery or guest assistance.
- Tools/workflows: Roadbook templating for recurring routes; on-premise GPU or cloud robotics; operator-in-the-loop console for rapid RFT updates.
- Assumptions/dependencies: GNSS availability outdoors; geofencing for non-walkable areas; wayfinding consistency across property maps.
- Robotics Software — Simulation-to-Real training service
- Description: Offer HTL-based route-lifting, MetaUrban simulation, and offline IQL fine-tuning services to robotics teams to bootstrap mapless urban navigation.
- Tools/workflows: HTL library; curated sim-real aggregated datasets; reward templates (completion/collision/deviation); deployment SDK.
- Assumptions/dependencies: Simulator licensing and domain match; availability of web video datasets (Sekai/LongVU) or in-house footage; data governance agreements.
- Robotics Hardware Integration — RGB-only navigation stack
- Description: Provide a drop-in RGB-only navigation module for quadrupeds/wheelchairs and small UGVs to reduce LiDAR cost while maintaining social compliance.
- Tools/workflows: Dual-encoder vision stack (DINOv2+SigLIP); Qwen2 LLM backbone; action head decoding trajectories; ROS control bridge.
- Assumptions/dependencies: Adequate camera coverage and calibration; reliable frame synchronization; environmental conditions suitable for RGB (rain/night mitigations).
- Academia — Benchmarking social navigation and route alignment
- Description: Use UrbanVLA’s pipeline to study social compliance (SNS), long-horizon success (SR/SPL), and noisy route alignment in novel urban layouts.
- Tools/workflows: MetaUrban tasks (PointNav/SocialNav); ablation of HTL; mid-layer LLM state features for Q/V learning; reproducible reward functions.
- Assumptions/dependencies: Access to datasets and compute; ethical review for human subjects/teleoperation data; simulator–real comparability.
- Policy/Pilots — Regulatory trials with auditable safety metrics
- Description: Launch municipal pilots for sidewalk robots using standardized metrics (SNS, CC, RC) and logged “roadbooks” for post-hoc compliance audits.
- Tools/workflows: Compliance dashboards; incident replay via VideoQA logs; periodic offline RL safety updates; operator escalation protocols.
- Assumptions/dependencies: Regulator collaboration; acceptance criteria for collisions/near-misses; transparency requirements; data retention rules.
- Daily Life — Personal micro-robots for errands
- Description: Consumer-grade small robots conduct short errands (e.g., package drop-off) along known neighborhood routes using route-conditioned navigation.
- Tools/workflows: Mobile app to select targets and generate roadbooks; cloud inference at 2 Hz; teleop “nudge” interface; OTA updates with new routes.
- Assumptions/dependencies: Neighborhood regulations; connectivity; consumer safety expectations; warranty and liability frameworks.
Long-Term Applications
These applications require further research, scaling, regulatory approvals, or technical development beyond current demonstrations.
- City-Scale Fleet Autonomy — HD-map-free urban micromobility platform
- Description: Orchestrate thousands of sidewalk robots across cities using route-conditioned VLA, dynamic rerouting, and social norm compliance without HD maps.
- Tools/products: “Mapless Urban Autonomy Platform”; fleet brain for dispatch and coordination; citywide roadbook APIs; compliance analytics.
- Dependencies: Robust performance across weather/lighting; on-device inference to reduce latency; resilience to GNSS outages; standardized municipal APIs.
- Healthcare — Certified autonomous wheelchairs and assistive navigation
- Description: Clinically validated autonomous mobility aids with route guidance, obstacle avoidance, and social compliance in complex urban environments.
- Tools/products: Medical-grade UrbanVLA stack; caregiver teleop assist; safety monitors; explainable navigation logs for clinicians.
- Dependencies: Regulatory certification (FDA/CE); extensive longitudinal safety trials; redundancy in sensing (e.g., LiDAR backup); fail-safe behaviors.
- Public Safety and Emergency Response — Infrastructure-free routing
- Description: Rapid deployment of robots for evacuation guidance, supply delivery, or reconnaissance in partially mapped or degraded urban environments.
- Tools/products: Temporary roadbooks generated from aerial imagery; multimodal cues (audio, signage); dynamic obstacle-aware RFT.
- Dependencies: Robustness to occlusions/ debris; intermittent connectivity; integration with incident command systems; liability and ethics protocols.
- Smart City Standards — Social navigation certification and policy tooling
- Description: Establish standards for sidewalk robot behavior (e.g., SNS thresholds), auditing processes, and certification regimes based on logged roadbooks and outcomes.
- Tools/products: Compliance scorecards; third-party auditing tools; transparent RL reward policy disclosures; incident analytics.
- Dependencies: Consensus among municipalities and industry; public acceptability; privacy-by-design; data-sharing frameworks.
- Consumer Navigation — Turn-by-turn “roadbooks” for pedestrians and mobility-impaired users
- Description: Enhanced navigation apps output structured roadbooks with distance/direction cues that can be consumed by assistive devices or smartphones, potentially with visual scene alignment.
- Tools/products: Roadbook SDK for mobile; on-device visual alignment; optional wearable cameras; haptic/voice prompts.
- Dependencies: User privacy and consent; accessibility requirements; robust on-device perception under diverse conditions.
- Multimodal Navigation — Integration with V2X and traffic signal semantics
- Description: Incorporate crosswalk signals, beacons, and V2X broadcasts to strengthen turn decisions and social compliance in dense pedestrian environments.
- Tools/products: Multimodal fusion modules; infrastructure APIs; standardized semantic protocols; safety-aware RL reward expansions.
- Dependencies: Availability of V2X infrastructure; reliable signal interpretation; city cooperation; security hardening.
- Fleet Risk and Insurance — Safety scoring and premium optimization
- Description: Use compliance metrics (SNS/CC/RC) and roadbook logs to price risk, manage claims, and incentivize safer navigation policies.
- Tools/products: Insurtech analytics platform; incident attribution with replay; model versioning and risk tracking.
- Dependencies: Regulatory acceptance of telemetry; standardized incident taxonomy; secure data pipelines; fairness considerations.
- Energy/Utilities — Autonomous meter reading and light-asset inspections
- Description: Robots conduct sidewalk-accessible inspections (e.g., streetlights, kiosks) and follow long urban routes without HD maps.
- Tools/products: Routebook planner for utility circuits; anomaly detection via VideoQA; periodic RFT with operator annotations.
- Dependencies: Access permissions; nighttime robustness; integration with CMMS systems; safety near traffic interfaces.
- Robotics R&D — General-purpose VLA navigation across embodiments
- Description: Extend route-conditioned VLA to diverse platforms (humanoids, micro-UGVs) and terrains with unified training pipelines.
- Tools/products: Cross-embodiment NavFoM-derived models; mid-layer LLM state features for value learning; broader multimodal cues (as proposed by authors).
- Dependencies: Embodiment-specific control layers; sample-efficient sim-to-real; standardized datasets; additional sensing (force/tactile for humanoids).
- Software Ecosystem — UrbanVLA SDK and “roadbook generator” services
- Description: Commercial SDKs that convert map routes to robust roadbooks (via HTL-like algorithms) and expose perception-action APIs to OEMs.
- Tools/products: HTL route-lifting library; reward template catalog; deployment and monitoring console; OTA learning updates.
- Dependencies: Vendor alignment on APIs; support for varying map providers; strong MLOps; security and compliance.
- On-Device Autonomy — Low-power, high-rate inference
- Description: Edge-friendly variants achieving >10 Hz control for faster platforms without cloud reliance, through model compression and hardware co-design.
- Tools/products: Quantized VLA models; efficient vision encoders; embedded action decoders; power-aware scheduling.
- Dependencies: Hardware accelerators; sustained accuracy under compression; thermal and battery management; field validation.
Notes on Cross-Cutting Assumptions and Dependencies
- Map and GNSS reliance: Most applications assume access to consumer navigation APIs and reasonable GNSS signals; fallback localization may be needed in GNSS-denied areas.
- Sensing and compute: Multi-camera RGB and either edge or cloud GPU compute are required; severe weather/night conditions may necessitate lighting or additional sensors.
- Safety and regulation: Operating on public sidewalks requires permits and compliance; auditable logs and SNS/CC metrics help meet regulatory expectations.
- Data governance: Teleoperation and video collection for RFT raise privacy and security considerations; policies for retention, access, and anonymization are essential.
- Reliability and scalability: City-scale deployment demands robust failure handling, fleet orchestration, and standardized interfaces across municipalities and map providers.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- Advantage-Weighted Regression (AWR): An offline RL objective that weights imitation by estimated advantage to improve policy learning. "an advantage-weighted regression (AWR) objective"
- Amap: A commercial city navigation tool/API providing high-level route instructions. "Amap\cite{amap2023} via its Web API"
- Behavior Cloning (BC): Imitation learning method that directly regresses actions from expert demonstrations. "IL based method BC\cite{Bain1995AFF}, GAIL\cite{ho2016generativeadversarialimitationlearning}"
- Birdâs-Eye-View (BEV): A top-down scene representation used for mapping and planning. "Birdâs-Eye-View (BEV) maps"
- Cross-embodiment: Training or evaluation across different robot bodies/platforms to improve generality. "leveraging cross-embodiment data across diverse tasks"
- Cross-modal projector: A module projecting visual features into the LLM’s embedding space. "use a cross-modal projector (double layer MLP)\cite{liu2023llava} to project the visual features"
- Cumulative Cost (CC): A metric penalizing collisions and unsafe behaviors over a trajectory. "The Cumulative Cost (CC)\cite{li2022metadrive} evaluates the agentâs ability to avoid collisions"
- DINOv2: A self-supervised vision backbone used to encode images. "using two pre-trained vision encoders (DINOv2\cite{oquab2023dinov2} and SigLIP\cite{zhai2023siglip})"
- GAIL: Adversarial imitation learning method matching expert behavior distributions. "IL based method BC\cite{Bain1995AFF}, GAIL\cite{ho2016generativeadversarialimitationlearning}"
- GNSS: Satellite-based positioning system for real-time robot localization. "a GNSS module provides the position and orientation of the quadruped in real time."
- Grid pooling: Downsampling approach aggregating features over spatial grids. "subsequently, we down-sample the features with grid pooling strategy"
- HD maps: High-definition maps with rich semantic and geometric details. "occupancy grids or HD maps"
- Heuristic Trajectory Lifting (HTL): A heuristic algorithm to extract abstracted routes from raw trajectories. "we introduce Heuristic Trajectory Lifting (HTL), a heuristic algorithm that lifts high-level route information from the raw trajectory"
- Implicit Q-Learning (IQL): Offline RL algorithm that learns value functions and updates policies via advantage-weighted regression. "We adopt Implicit Q-Learning (IQL) \cite{kostrikovoffline}"
- LLM: A transformer-based LLM backbone used for multimodal reasoning and action token generation. "LLM backbone"
- LiDAR: Laser-based sensor providing precise depth and geometry measurements. "seven strong baselines with LiDAR observation"
- MetaUrban: A simulation benchmark/environment for urban navigation tasks. "MetaUrban simulator\cite{wu2025metaurban}"
- Navigation Foundation Model (NavFoM): A large-scale pre-trained model for navigation across embodiments and tasks. "NavFoM\cite{zhang2025embodiednavigationfoundationmodel} introduces the first large-scale navigation foundation model"
- Offline Reinforcement Learning (Offline RL): RL using fixed datasets without online environment interaction. "a widely used offline RL algorithm"
- ORCA: A reciprocal collision avoidance planner used for generating expert trajectories. "global planners such as ORCA\cite{van2011reciprocal}"
- Partially Observable Markov Decision Process (POMDP): Formalism for decision-making under partial observability. "We formulate the route-guided navigation task as a Partially Observable Markov Decision Process (POMDP)"
- PPO: On-policy RL algorithm (Proximal Policy Optimization) for training expert policies. "generated by a PPO expert in simulation"
- PPO-ET: A safe RL variant of PPO incorporating early termination mechanisms. "PPO-ET\cite{sun2021safeexplorationsolvingearly}"
- PPO-Lag: A constrained/safe RL variant of PPO using Lagrangian methods. "PPO-Lag\cite{fujimoto2019benchmarkingbatchdeepreinforcement}"
- Q-function: The action-value function estimating expected return for state–action pairs. "IQL learns a value function and a Q-function "
- Qwen2: The specific LLM backbone used for multimodal token processing and generation. "an LLM backbone (Qwen2\cite{qwen2})"
- Reinforcement Fine-Tuning (RFT): Post-training stage using RL to refine safety and robustness. "Reinforcement Fine-Tuning (RFT) on a mixture of simulation and real-world data"
- Route Completion (RC): Real-world metric measuring proportion of route successfully traversed. "We use Route Completion (RC)\cite{zhou2024mattersenhancetrafficrule} to evaluate real-world performance"
- Route-conditioned: Model or policy conditioned on high-level route inputs to guide local planning. "We propose the first route-conditioned VLA for urban micromobility"
- SavitzkyâGolay filter: A smoothing filter for denoising trajectory signals. "a SavitzkyâGolay filter\cite{savitzky1964smoothing} is applied to denoise web trajectories"
- SigLIP: A vision-language pretraining model used as an image encoder. "using two pre-trained vision encoders (DINOv2\cite{oquab2023dinov2} and SigLIP\cite{zhai2023siglip})"
- Sim-real aggregated dataset: A combined dataset of simulation and real-world episodes for training. "a sim-real aggregated dataset comprising 2,400 episodes (approximately 40 hours) in the MetaUrban simulator ... along with roughly 8 hours of real-world demonstrations"
- Simultaneous Localization and Mapping (SLAM): Methods that build a map while localizing the agent to enable navigation. "Simultaneous Localization and Mapping (SLAM) systems"
- Social Navigation Score (SNS): Metric quantifying compliance with social norms during navigation. "the Social Navigation Score (SNS)\cite{deitke2022retrospectives} quantifies the modelâs compliance with social navigation standards."
- Success weighted by Path Length (SPL): Efficiency-aware success metric balancing path optimality. "Success weighted by Path Length (SPL)\cite{anderson2018evaluation}"
- Supervised Fine-Tuning (SFT): Supervised post-training stage to align model outputs with demonstrations. "Supervised Fine-Tuning (SFT) using simulated environments and trajectories parsed from web videos"
- Teleoperation: Human remote control of a robot to collect demonstrations. "human teleoperation data ensure that the model learns to adapt to complex real-world scenarios"
- Unitree Go2: A quadruped robot platform used for real-world deployment. "Web-ADK with a Unitree Go2 robot"
- Video Question Answering (VideoQA): Task where models answer questions about video content to improve scene understanding. "a real-world Video Question Answering (VideoQA) task\cite{shen2024longvu,li2025sekai}"
- Vision-Language-Action (VLA): Models that integrate perception, language, and action generation for embodied tasks. "a route-conditioned Vision-Language-Action (VLA) framework"
- Vision-LLMs (VLMs): Multimodal models aligning visual inputs with language representations. "pre-trained Vision-LLMs (VLMs)"
- Waypoint: A location marker used to guide trajectory planning along a route. "waypoints from consumer navigation tools (e.g., Google Maps) to provide high-level guidance"
- Web-ADK: Web-based application/development kit enabling robot communication and control. "communicates via Web-ADK with a Unitree Go2 robot"
- Zero-shot generalization: Model’s ability to perform in unseen environments without task-specific training. "Real-world deployments of UrbanVLA demonstrate zero-shot generalization across diverse environments"
Collections
Sign up for free to add this paper to one or more collections.