- The paper demonstrates that continuous masked autoregression combined with a diffusion transformer significantly improves multimodal motion generation accuracy.
- It integrates causal and gated linear attention, RMSNorm, and cross-attention to effectively fuse signals from text, speech, and music modalities.
- Experimental results show notable gains in R-Precision and FID scores, indicating marked improvements in motion quality and diversity.
OmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Introduction and Motivation
OmniMotion addresses the challenge of generating whole-body human motion conditioned on diverse modalities—text, speech, and music—within a unified framework. Prior approaches typically focus on single modalities and rely on either discrete tokenization (e.g., VQ-VAE-based) or direct continuous regression (e.g., GANs, VAEs, diffusion models). Discrete tokenization introduces quantization errors, while continuous regression often lacks the benefits of autoregressive or masked modeling, which are known to improve generative quality. OmniMotion proposes a continuous masked autoregressive (MAR) transformer architecture, integrating causal attention, gated linear attention, and RMSNorm, and leverages a Diffusion Transformer (DiT) for high-fidelity motion synthesis. The framework is designed to generalize across modalities, enabling cross-modal knowledge transfer and improved data efficiency.
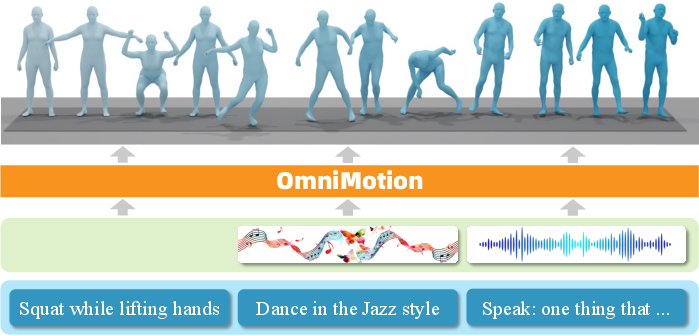
Figure 1: The OmniMotion framework supports multimodal whole-body motion modeling, including text-based, music-based, and speech-based motion generation.
Framework Architecture
The OmniMotion framework consists of three primary components: a continuous autoencoder, a masked autoregressive transformer, and a diffusion transformer. The architecture is designed to encode, model, and generate motion sequences in a modality-agnostic manner.
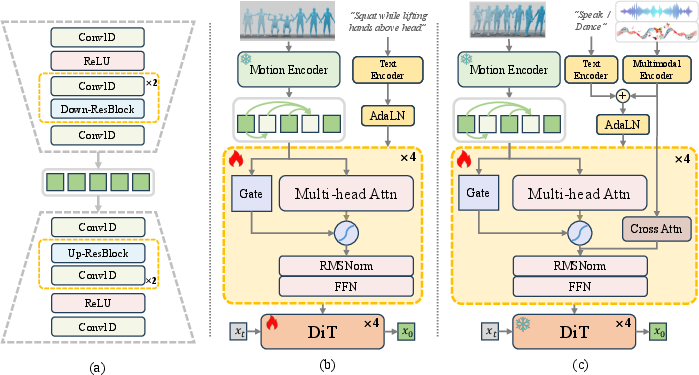
Figure 2: Framework overview: (a) Motion encoding via autoencoder; (b) Masked autoregressive transformer with causal attention; (c) Multimodal signal injection via AdaLN and cross-attention.
Continuous Autoencoder
- Input: Motion sequences in SMPL-X format (body, hands, face, global translation, and shape).
- Encoder: Stacked 1D convolutions with ReLU, followed by downsampling residual blocks, reducing sequence length by a factor of four.
- Latent Code: Continuous motion tokens, avoiding quantization artifacts.
- Decoder: Mirrors the encoder, reconstructing the original motion.
- Loss: L1 reconstruction loss between input and output motion.
- Masking: Random masking of motion tokens, following a cosine schedule.
- Causal Attention: Sequential, autoregressive prediction of masked tokens, preserving temporal dependencies.
- Gated Linear Attention: Adaptive gating of attention outputs, focusing on salient actions and suppressing redundant or stationary frames.
- RMSNorm: Stabilizes training across heterogeneous modalities and mitigates gradient instability from large motion variations.
- Text/Multimodal Conditioning: Text features extracted via a pretrained transformer (LaMP), injected via AdaLN; speech/music features encoded and injected via cross-attention.
- Role: Refines the output of the masked transformer, diffusing towards target motion tokens.
- Conditioning: Receives contextual features from the transformer, combined with time embeddings.
- Training: DiT is pretrained on text-to-motion, then frozen during multimodal fine-tuning; only the masked transformer and cross-attention layers are updated for new modalities.
Multimodal Integration
OmniMotion supports conditioning on text, speech, and music:
- Text: Used as a shared conditional signal for pretraining and cross-modal alignment.
- Speech/Music: Encoded via dedicated 1D convolutional networks, projected into the latent space, and injected via cross-attention.
- AdaLN: Facilitates dynamic normalization and control signal injection for all modalities.
Training and Inference
- Pretraining: Conducted on text-to-motion pairs (HumanML3D), learning robust sequence-level alignment.
- Multimodal Adaptation: Model is initialized from text-to-motion weights; DiT is frozen, and only the masked transformer and cross-attention are fine-tuned on speech-to-gesture (BEAT2) and music-to-dance (FineDance).
- Inference: Begins with all-masked tokens; autoregressive transformer iteratively predicts latents, which are then refined by DiT. Classifier-free guidance is applied at the final projection layer.
Experimental Results
- Text-to-Motion: On HumanML3D (SMPL-X), OmniMotion achieves R-Precision Top-1/2/3 of 0.704/0.843/0.898 and FID of 4.84, outperforming prior methods by significant margins (e.g., 19.3% improvement in Top-1 R-Precision, 75.2% reduction in FID).
- Speech-to-Gesture: On BEAT2, achieves FIDH of 17.65, FIDB of 25.92, and Diversity of 14.70, surpassing previous state-of-the-art in both quality and diversity.
- Music-to-Dance: On FineDance, achieves FIDH of 3.63, FIDB of 71.93, and Diversity of 15.87, with improvements in hand and body motion fidelity.
Qualitative Results
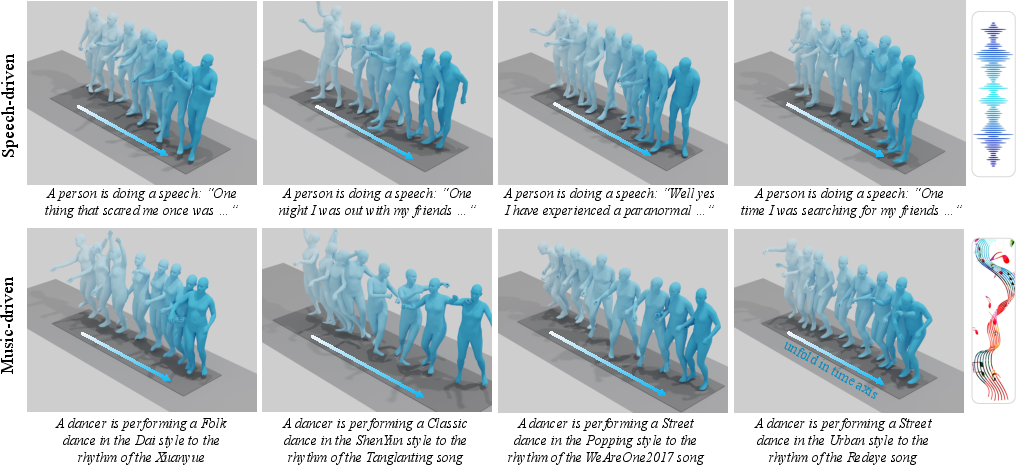
Figure 3: Qualitative results of motions generated from speech and music conditions.
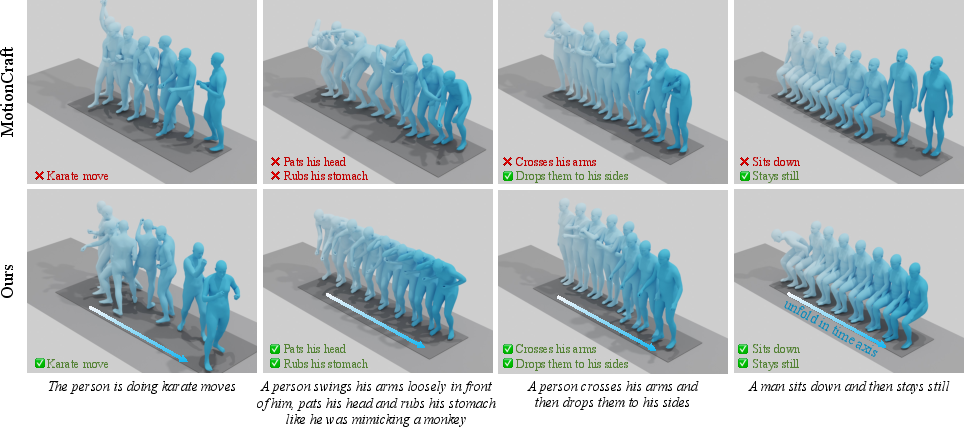
Figure 4: Qualitative results of text-driven motion generation.

Figure 5: Qualitative results of speech-driven motion generation.
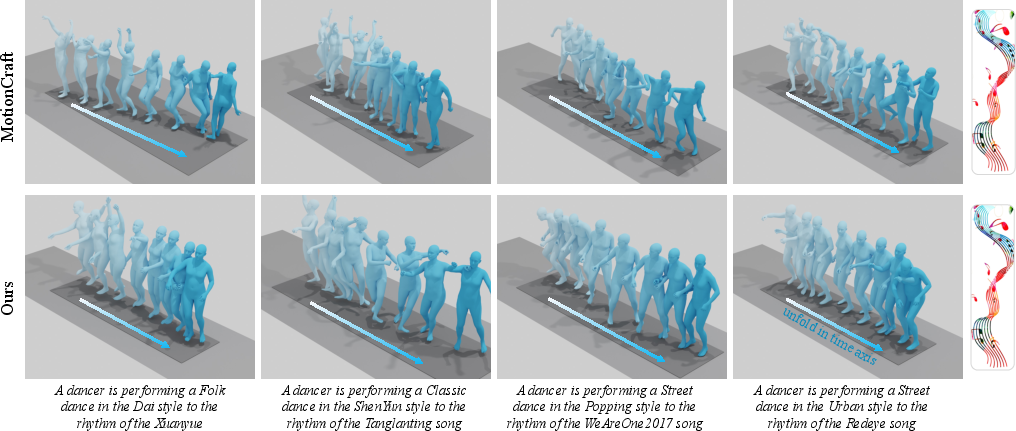
Figure 6: Qualitative results of music-driven motion generation.
Ablation Studies
- Causal Attention: Outperforms bidirectional/random attention, confirming the importance of temporal order in motion.
- DiT vs. MLP: DiT yields higher motion quality and better multimodal generalization.
- Gated Linear Mechanism: Enhances attention to key actions, improving motion detail.
- RMSNorm: Improves stability and output quality, especially under heterogeneous input distributions.
- Cross-Attention: Essential for effective multimodal fusion; AdaLN alone is insufficient.
Implementation Considerations
- Resource Requirements: Training is feasible on a single NVIDIA V100 GPU; autoencoder and transformer architectures are moderate in size (hidden dims: 512–1792).
- Data Representation: All datasets are converted to SMPL-X format for unified whole-body modeling.
- Fine-Tuning Strategy: Freezing DiT during multimodal adaptation prevents catastrophic forgetting and reduces computational cost.
- Inference Speed: DiT introduces minor overhead compared to MLPs, but the compactness of motion data keeps inference practical.
Implications and Future Directions
OmniMotion demonstrates that continuous masked autoregressive modeling, combined with diffusion-based refinement, can achieve state-of-the-art performance in multimodal whole-body motion generation. The unified architecture enables cross-modal transfer and data efficiency, which is particularly valuable given the limited scale of high-quality motion datasets. The approach is extensible to additional modalities (e.g., video, haptics) and could be adapted for real-time applications with further optimization.
Potential future directions include:
- Scaling to Larger, More Diverse Datasets: To improve generalizability, especially for speech and music-driven motion.
- Incorporating Physics or Environment Constraints: For more realistic and context-aware motion synthesis.
- Interactive and Real-Time Generation: Optimizing the architecture for low-latency applications in VR/AR and robotics.
- Personalization and Style Control: Extending the framework to support user-specific motion styles or emotional expressiveness.
Conclusion
OmniMotion introduces a unified, continuous masked autoregressive framework for multimodal whole-body motion generation, integrating causal attention, gated linear attention, RMSNorm, and a diffusion transformer. The architecture achieves superior quantitative and qualitative results across text, speech, and music modalities, and sets a new standard for flexible, high-fidelity human motion synthesis. The framework's modularity and extensibility position it as a strong foundation for future research in multimodal generative modeling and embodied AI.

