- The paper demonstrates a novel LLM-embedded architecture that enhances autonomous orchestration of data pipelines by improving semantic understanding and planning.
- It integrates components such as perception, reasoning, tool invocation, and continuous learning to manage heterogeneous data sources effectively.
- The framework's validation via iDataScience and DBA Agent benchmarks highlights its ability to optimize latency, cost, and operational efficiency.
Data Agent: A Holistic Architecture for Orchestrating Data+AI Ecosystems
The paper discusses a novel approach to integrating LLMs into Data+AI systems through a concept called "Data Agent." This architecture is designed to enhance the autonomous orchestration of data pipelines by improving the systems’ semantic understanding, reasoning, and planning abilities. The advent of LLMs offers a promising solution to address these challenges, allowing for more efficient data processing and management strategies.
Introduction
The primary challenge in traditional Data+AI systems is their heavy reliance on human expertise for orchestrating system pipelines and adapting to dynamic environments and requirements. While various data science tools exist, the orchestration of these tools within an optimized and efficient pipeline remains a significant hurdle due to the system's limited semantic reasoning capabilities. The proposed Data Agent framework addresses these challenges by embedding LLM capabilities within the architecture, enhancing semantic understanding, reasoning, and planning.
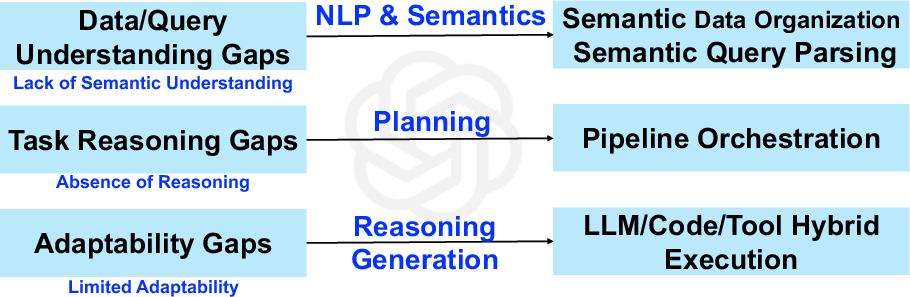
Figure 1: Challenges of Data+AI Systems.
Data Agent Architecture
The proposed architecture of the Data Agent integrates several components, including perception, reasoning and planning, tool invocation, memory, continuous learning, and multiple agent collaboration. This composite structure is designed to manage data-related tasks autonomously, with a focus on knowledge comprehension, automatic planning, and adaptive improvement.
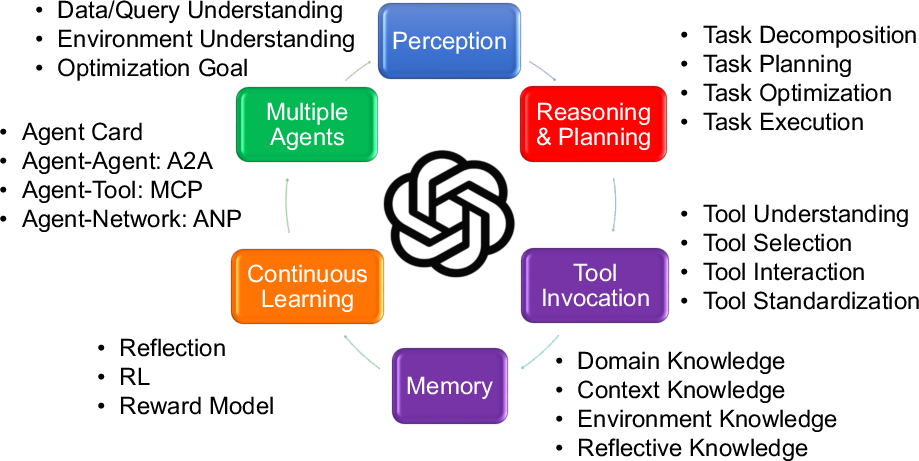
Figure 2: Key Factors of Data Agents.
Data Understanding and Exploration
The Data Agent architecture necessitates efficient data understanding and exploration to facilitate seamless discovery and accessibility. Using a structured semantic catalog and data fabric, heterogeneous data is unified to support advanced querying capabilities. Additionally, the architecture supports various tools for data preparation and integration, essential for efficient pipeline execution.
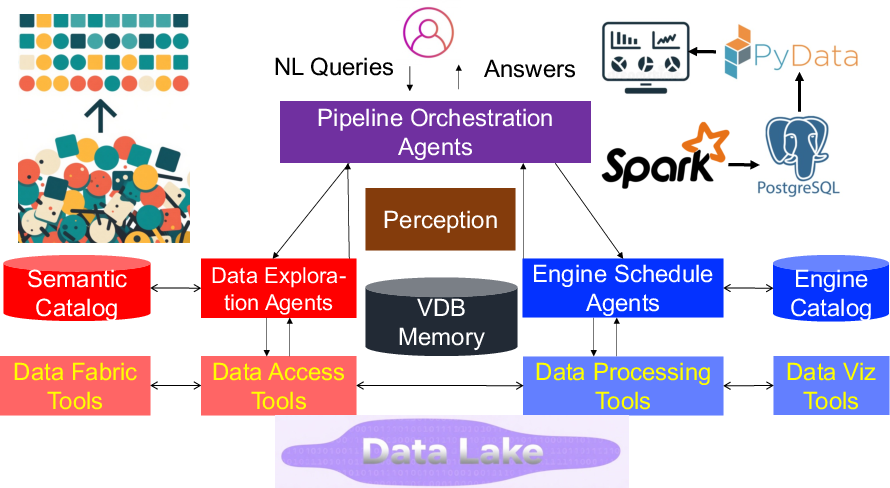
Figure 3: Data Agents Framework.
Data Engine Understanding and Scheduling
Different data processing engines, such as Spark and DBMSs, are understood and coordinated by the Data Agent to execute complex tasks effectively. Profiling specific engine capabilities and coordinating them for task execution is crucial to maximize system efficiency.
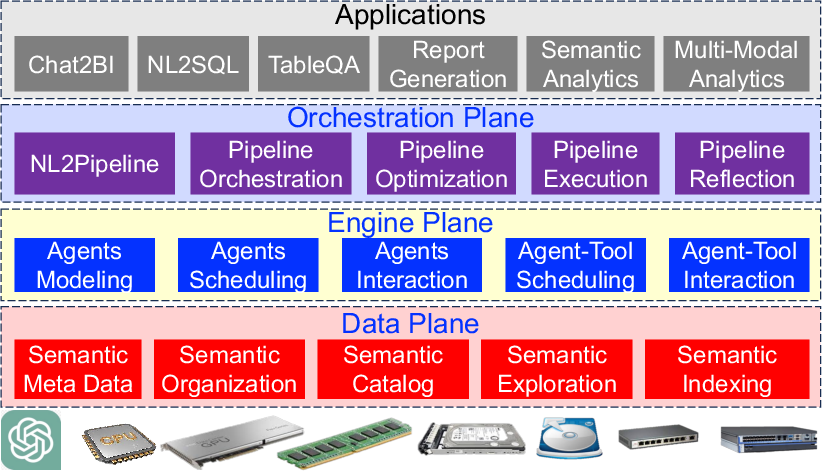
Figure 4: Data Agents Architecture.
Pipeline Orchestration
The pipeline orchestration agent component plays a pivotal role in generating, optimizing, and executing pipelines based on user-input natural language queries. By leveraging LLMs’ understanding and reasoning capabilities, the Data Agent refines these pipelines to improve latency, cost, and accuracy, invoking engine agents for efficient execution.
iDataScience: Multi-Agent System for Data Science
iDataScience serves as a practical manifestation of the Data Agent framework, focusing on adaptively handling data science tasks by harmonizing diverse data agent capabilities.
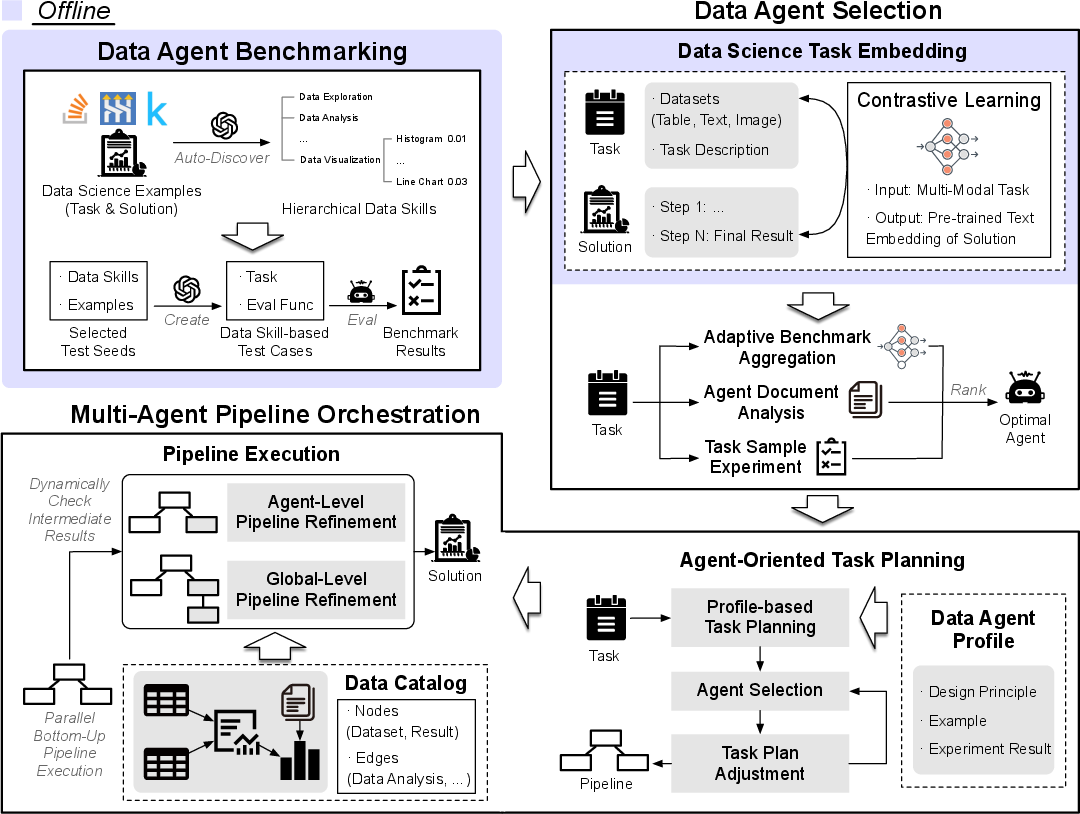
Figure 5: Overview of iDataScience.
Offline Data Agent Benchmarking
This stage constructs a data agent benchmark that represents various data science scenarios. Essential data skills are extracted from data science examples, forming a hierarchical structure, which, coupled with probabilistic sampling and LLM-generated test cases, underpins comprehensive data agent evaluation.
Online Multi-Agent Pipeline Orchestration
Upon receiving a data science task, this stage exploits benchmark results and task embeddings to select optimal agents for various sub-tasks. Using LLMs, tasks are decomposed, refined, and executed in parallel, with dynamic adjustments based on intermediate results to achieve optimal outcomes.
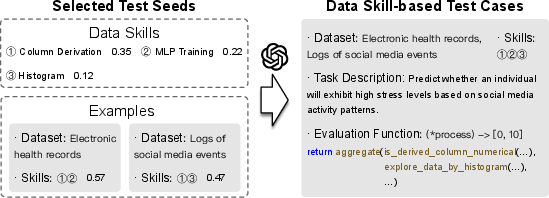
Figure 6: Example of Data Skill-based Benchmark Construction.
Data Analytics Agents
The paper postulates the development of specialized data analytics agents for different data types, including structured, unstructured, and multi-modal data. Each agent type leverages the semantic understanding and reasoning capabilities of LLMs to enhance data processing, optimally orchestrating and executing complex analytics tasks.
DBA Agent
The DBA Agent focuses on automating database diagnosis via LLMs to manage multiple databases effectively. It autonomously acquires knowledge and generates diagnostic reports to accurately determine the root causes of database anomalies, thereby significantly enhancing operational efficiency.
Conclusion
In conclusion, the Data Agent provides a holistic framework to advance the orchestration of Data+AI systems by embedding LLM capabilities. By introducing modular components and specialized agents, it addresses core challenges, paving the way for more adaptable and efficient data processing ecosystems. The proposed architecture offers numerous opportunities for further research and application across diverse domains in AI and data management.

