The Road Less Traveled: Enhancing Exploration in LLMs via Sequential Sampling
Abstract: Reinforcement learning (RL) has been pivotal in enhancing the reasoning capabilities of LLMs, but it often suffers from limited exploration and entropy collapse, where models exploit a narrow set of solutions, leading to a loss of sampling diversity and subsequently preventing RL from further improving performance. This issue is exacerbated in parallel sampling methods, where multiple outputs are drawn from the same distribution, potentially causing the model to converge to similar solutions. We propose SESA, a novel SEquential SAmpling framework that mitigates this challenge by generating diverse solution sketches sequentially before expanding them into full reasoning paths. This approach ensures broader exploration by conditioning each new output on previous ones, promoting diversity throughout the process and preventing policy collapse. Our experiments on a synthetic task show that sequential sampling consistently outperforms traditional RL methods in terms of path diversity and recovery from collapse. Further evaluations on real-world tasks demonstrate that SESA improves both the exploration of valid strategies and the overall performance of LLMs. On three agent benchmarks, SESA lifts success rates by $+0.25$, $+0.42$, and $+0.07$ absolute over the base model (up to an additional $211\%$ relative improvement over baseline RL), underscoring its exploration advantage. This work introduces a structured approach to exploration, paving the way for more effective and diverse reasoning in RL-trained LLMs. Our code is released at https://github.com/MuLabPKU/sesa.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
The Road Less Traveled: Enhancing Exploration in LLMs via Sequential Sampling — Explained Simply
Overview: What is this paper about?
This paper is about helping LLMs think more creatively and explore more ideas when solving problems. The authors noticed that current training methods often push models to repeat the same kind of solution over and over, which stops them from discovering new, better ways to solve tasks. They introduce a new method called SESA (Sequential Sampling) to keep the model’s ideas diverse and prevent it from getting stuck on a single path.
Key Questions: What are the researchers trying to figure out?
The paper focuses on simple, practical questions:
- How can we get LLMs to explore a wider variety of solutions instead of repeating the same one?
- Can a different way of generating answers lead to more creative and effective problem solving?
- Will this improve performance on tasks like puzzles, math problems, and decision-making games?
Methods: How does SESA work (in everyday terms)?
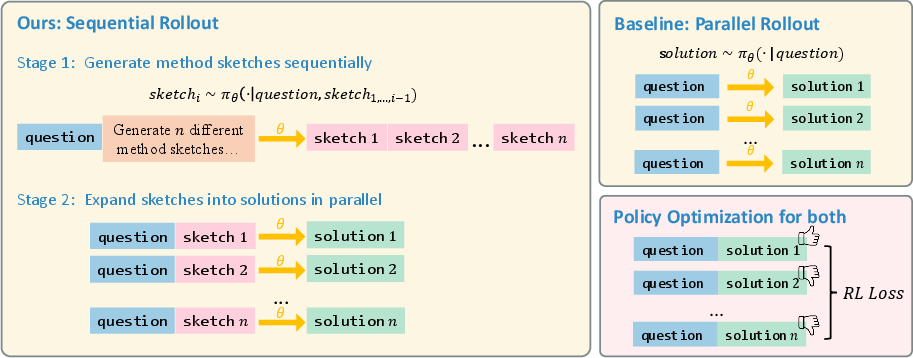
Think of problem solving like exploring a forest with many paths. Traditional methods ask the model to pick several paths, but all those choices are made independently, as if none of the paths “know” about the others. This is called parallel sampling. It often leads to picking very similar routes again and again.
SESA changes this by using sequential sampling:
- The model generates one idea at a time, and each new idea “sees” what was already tried.
- This nudges the model to avoid repeating itself and explore different directions.
Because real tasks can have long, detailed answers, SESA uses a simple two-stage approach:
- Stage I: Method sketches — The model first writes short, different plans (like bullet-point outlines). These are quick and diverse by design.
- Stage II: Full solutions — The model then turns each sketch into a complete answer. This part can run in parallel for speed.
In short: first, make a variety of mini-plans; then, expand each plan into a full solution. This keeps ideas diverse without slowing everything down too much.
Main Findings: What did they discover, and why is it important?
The researchers tested SESA on a synthetic “treasure hunt” and on real tasks (games, Sudoku, and math). Here’s what they found:
- Synthetic treasure hunt:
- The model had to guess from a hidden list of correct locations (like 20 treasure spots).
- With parallel sampling, the model kept finding the same few spots and got stuck.
- With sequential sampling, it kept discovering new spots and found many more overall.
- In numbers: parallel sampling plateaued at 11 distinct spots, while sequential sampling found 22 and even 80 in different setups.
- During training, the parallel method collapsed to one “favorite” spot (only 1 out of 20), but SESA increased coverage of correct spots up to about 77%. That means much broader exploration.
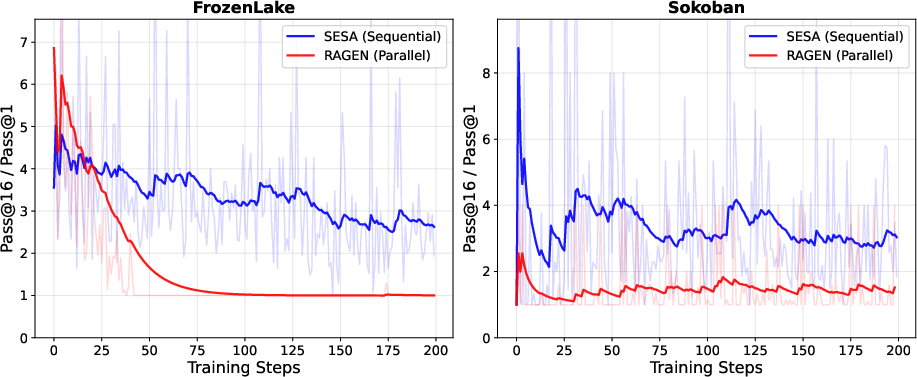
- Agent games (Sokoban, Countdown, FrozenLake):
- These are decision-making tasks where trying different strategies matters a lot.
- SESA improved success rates notably:
- Sokoban: +0.25 (much higher than other methods)
- Countdown: +0.42
- FrozenLake: +0.07
- These gains show SESA helps agents explore and avoid getting stuck.
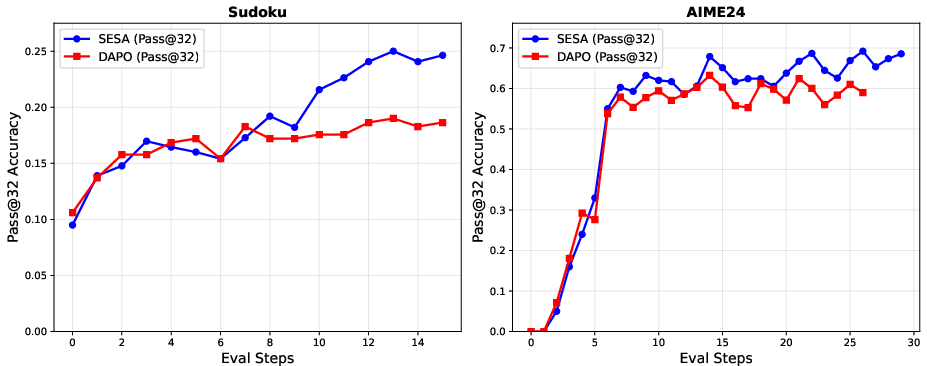
- Sudoku and Math (AIME24):
- Sudoku: SESA improved the success rate by 6% over a strong baseline.
- Math: SESA matched the baseline on “first try” accuracy (Pass@1), but did better when allowed multiple attempts (Pass@k), with a 9% improvement. This means the model kept more different solution paths available, which is useful for tough problems.
- Recovering from “dead policy”:
- Sometimes models collapse and produce nearly the same answer every time (the authors call this a “dead policy”).
- Switching to sequential sampling can revive diversity and help the model start improving again.
Why It Matters: What’s the impact of this research?
- It keeps models exploring instead of getting stuck. This leads to discovering new strategies and better answers over time.
- It boosts performance in areas where trying many different approaches is essential, like planning in games, solving puzzles, and tackling complex math.
- It offers a simple, practical change (generate sketches first, then expand) that can be added to existing training methods.
- It helps avoid “policy collapse,” where a model stops learning because it keeps repeating the same solution.
In short: SESA gives LLMs a smarter way to try “the road less traveled,” which leads to more diverse thinking and better results.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains uncertain, missing, or unexplored in the paper. Each point is intended to be specific and actionable for future research.
- Lack of formal theory: No principled analysis of why or when sequential conditioning on prior candidates improves exploration compared to i.i.d. sampling; absence of convergence, bias, or variance guarantees for the off-policy rollout and on-policy objective mismatch.
- Objective mismatch unexamined: Candidates are generated conditioned on prior sketches but trained with likelihoods that ignore that history. The impact of this off-policy discrepancy on gradient bias, stability, and final performance is not studied.
- Stage I not optimized: Method sketches are generated but not trained with any reward, loss, or diversity constraint. It is unclear whether sketch quality/diversity improves over training or how to optimize Stage I (e.g., with duplicate penalties, diversity rewards, or auxiliary objectives).
- Prompt dependence not quantified: The diversity and usefulness of “PromptSketch” and “PromptSolve” are central, but there is no systematic study of prompt design, sensitivity, robustness to wording, or cross-task transferability.
- Diversity measurement inconsistent: Beyond Coverage@k (synthetic) and Pass@16/Pass@1 ratios, there is no unified, task-agnostic diversity metric (e.g., semantic entropy, edit distance, strategy clustering) nor calibration of diversity-quality trade-offs.
- Compute/latency overhead not reported: Stage I adds sequence generation and longer contexts; overall training/inference throughput, token counts, memory footprint, and cost vs parallel baselines are not measured or controlled.
- Context-length limits and drift unquantified: Although the two-stage design aims to mitigate instruction drift and context overflow, there is no empirical quantification of drift, duplication rates, or degradation as the number/length of sketches grows.
- Duplicate handling unspecified: The method relies on conditioning to discourage duplicates but lacks explicit mechanisms to detect, penalize, or prevent near-duplicates; deduplication criteria and their effect on training are not described.
- Ablation studies missing: No controlled ablations for number of sketches G, sketch length, sequential vs fully-parallel expansion, Stage I vs Stage II contributions, entropy regularization synergy, or effect of different advantage normalizations.
- Baseline coverage limited: Comparisons exclude strong exploration baselines such as diverse beam search, self-consistency with structured deduplication, MCTS/AlphaZero-like RL training, ToT/RAP with learned value functions, and GRPO/DAPO variants with diversity-aware rewards.
- Generality across models underexplored: Results are mainly on Qwen2.5-7B and DeepSeek-V3.1 (API use in synthetic). Transfer to other architectures/sizes (Llama, GPT, Mixtral), and scaling trends are not examined.
- Task scope narrow: Evaluations focus on small agent environments, Sudoku, and AIME24; no tests on large-scale program synthesis, multi-hop QA with verifiers, long-horizon planning, or multimodal tasks where exploration is critical.
- Reward design details sparse: Verifiable reward implementations for Sudoku/AIME24/agents are not fully specified (e.g., tolerance, partial credit, step-level rewards), making reproducibility and fairness of comparisons unclear.
- Statistical rigor lacking: No confidence intervals, standard deviations, or multiple-seed runs; significance of improvements, variance under different random seeds, and robustness across datasets are not reported.
- Training regime clarity: Key hyperparameters, rollout budgets, temperature settings, advantage baselines, clipping ε, and normalization details per task are not comprehensively documented.
- Selection/pruning when over budget: In agent mode, when candidate trajectories exceed the cap U, the strategy for selecting which to expand or prune (e.g., diversity-aware selection, value-based pruning) is not defined or evaluated.
- Quality–diversity trade-off: The effect of increased diversity on correctness (Pass@1, calibration, error rates) is only partially reported; potential degradation in single-sample accuracy in other tasks or later training phases is unquantified.
- Failure modes not analyzed: Risks of negative priming (conditioning on poor early sketches), drift toward superficially diverse but low-quality outputs, and mode collapse under sequential conditioning are not characterized.
- Interaction with preference-based RL: The method is demonstrated under verifiable rewards (RLVR); efficacy under RLHF/preference modeling where rewards are noisy or non-verifiable remains open.
- Integration with value models/search: How sequential sampling interacts with learned value functions, MCTS, or policy-improvement operators (e.g., policy iteration) to balance breadth vs depth is unexplored.
- Dedup criteria for “distinct strategies”: The paper assumes sketch distinctness but does not specify operational criteria (semantic vs lexical difference, graph- or plan-based dissimilarity) or automated evaluation of strategy-level diversity.
- Inference-time utilization of sketches: Training uses sketches to diversify rollouts, but evaluation decodes a single response without sketches; whether using sketches at inference improves Pass@k or Pass@1 is untested.
- Safety and alignment impacts: Increased exploration may surface unsafe/toxic behaviors or exploit reward loopholes; there is no analysis of safety filters, robustness to adversarial prompts, or alignment side effects.
- Data curation and synthetic task realism: The Path Exploration task (20 treasures) is simplistic; conclusions about exploration may not generalize to high-dimensional, combinatorial spaces. Larger, more realistic synthetic tasks are needed.
- Code/prompt reproducibility scope: While code is released, precise prompts, seeds, dataset splits, and environment configurations for each experiment are not detailed in the paper for exact replication.
- Long-horizon agent evaluation: Agent tasks are relatively simple and short-horizon; the benefits and scaling of sequential action proposals in complex environments (e.g., navigation with partial observability) remain unknown.
- Adaptive budgeting/open-loop control: How to adapt G and U online based on observed diversity, rewards, or entropy (e.g., stopping when marginal diversity gains drop) is not addressed.
Practical Applications
Applications of SESA (Sequential Sampling) from “The Road Less Traveled: Enhancing Exploration in LLMs via Sequential Sampling”
Below are practical, real-world applications derived from the paper’s findings, methods, and innovations. Each use case is categorized as an immediate or long-term application, linked to relevant sectors, and notes assumptions or dependencies that may affect feasibility.
Immediate Applications
The following applications can be operationalized now, leveraging the released codebase and the paper’s two-stage (sketch → solution) sequential sampling, RLVR training setup, and diversity monitoring metrics.
- RL training upgrade for LLMs (industry, academia; software sector): Integrate SESA into existing GRPO/DAPO-style RLVR pipelines to prevent entropy collapse, improve exploration, and raise Pass@k. Tools/products: “SESA Trainer” as a drop-in policy rollout module; dashboards tracking Coverage@k and Pass@k ratios; dead-policy detectors that auto-switch sampling regimes. Assumptions/dependencies: availability of verifiable rewards; compatible RL infrastructure; sufficient compute; careful tuning of G (number of sketches) and context budget.
- Recovery of stalled (“dead”) RL policies (industry, academia; software/agent frameworks): Resume training from stagnated checkpoints with sequential sampling to revive exploration and improve success rates (as shown for Countdown and FrozenLake). Workflow: checkpoint reload → sequential Stage I (method sketches) → parallel Stage II expansion → standard GRPO/DAPO objective with advantages from original input. Assumptions/dependencies: task has multiple valid strategies; rewards remain informative; monitoring to detect collapse (e.g., Pass@16/Pass@1 drifting toward 1).
- Agent frameworks with diversity-aware action proposals (industry, academia; robotics, operations, RPA): Embed sequential action proposals into RAGEN-like agents for classical environments (Sokoban, FrozenLake) and enterprise automation tasks (multi-step workflows), enforcing distinct actions per decision step and capping expansion with a global U to control compute. Tools/products: “SESA-Agents” library components for action-level sequential sampling with trajectory caps. Assumptions/dependencies: simulator or environment provides verifiable rewards; branching factor manageable; latency budget acceptable.
- Program synthesis and automated bug fixing with RLVR (industry; software engineering): Use Stage I to propose diverse solution plans (e.g., alternative algorithms or patch strategies) and Stage II to generate code candidates in parallel; reward via unit tests and static checks. Tools/products: CI-integrated “SESA Code Repair” that maintains exploration and avoids overfitting to a single patch family. Assumptions/dependencies: high-quality test suites; reproducible build/runtime; guardrails for unsafe code paths.
- Data engineering and ETL strategy exploration (industry; data platforms): Sequentially draft distinct normalization/mapping strategies (Stage I), then generate executable pipelines (Stage II); reward via schema validators, constraint checks, and downstream data quality metrics. Tools/products: “SESA-ETL Planner” for diversity-preserving data transformation workflows. Assumptions/dependencies: reliable validators; ability to auto-run pipelines; compute budget for parallel expansion.
- Math and puzzle tutoring with diverse solution paths (industry, academia; education): Train or fine-tune math solvers/sudoku solvers with SESA to retain multiple valid solution methods, enhancing Pass@k and exploration. Inference-time workflow for tutoring: propose several short “method sketches” to students, select/expand one for detailed explanation. Tools/products: “SESA Tutoring” modules for educational platforms. Assumptions/dependencies: tasks have objective verifiers (answers/proofs); content moderation for wrong or confusing sketches.
- Diversity-aware model evaluation and governance (industry; ML governance/policy): Adopt Coverage@k and Pass@16/Pass@1 as health metrics to detect entropy collapse during training and pre-deployment evaluation. Tools/products: “Exploration Health” dashboards, alerts for collapse onset, automated retraining with sequential sampling. Assumptions/dependencies: organizational buy-in for new KPIs; logging infrastructure; standardization of evaluation protocols.
- Game and planning research (academia; software/AI research): Use SESA to study exploration dynamics in symbolic tasks (sudoku), math reasoning (AIME24), and classic environments, comparing parallel vs sequential sampling under controlled conditions. Tools/products: reproducible research workflows with the provided codebase and synthetic path exploration metric (Coverage@k). Assumptions/dependencies: reproducible seeds; consistent reward shaping; clear exploration targets.
- Creative ideation assistants (industry; creative tools): Even without RL, adopt the two-stage prompting pattern at inference to produce diverse outlines/methods (Stage I), then expand selected ones (Stage II) for writing, design, or brainstorming. Tools/products: “SESA Brainstorm” modes in content tools that encourage method-level diversity before drafting full outputs. Assumptions/dependencies: tolerance for higher latency and token usage; user interface for comparing sketches; curation to avoid incoherent or redundant ideas.
Long-Term Applications
These applications require further research, scaling, domain integration, or regulatory developments before widespread deployment.
- Safety-critical clinical decision support with exploration safeguards (industry, academia; healthcare): Train reasoning agents that explore diverse diagnostic/therapeutic plans via method sketches, with verifiable constraints (guidelines, contraindications) and external tool checks; reduce risk of premature convergence on suboptimal plans. Tools/products: “SESA-Clinical Planner” integrated with EHRs and medical guideline verifiers. Assumptions/dependencies: high-fidelity verifiers; audit trails; clinical validation and regulatory approval; bias and safety controls for exploration.
- Financial strategy exploration (industry; finance): Portfolio construction and risk management agents that propose diverse strategy sketches (e.g., factor mixes, hedging plans) and expand candidates validated through backtesting and risk metrics; retain diversity to avoid regime overfitting. Tools/products: “SESA-Quant” modules for research desks. Assumptions/dependencies: robust backtesting environments; transaction cost modeling; compliance and risk gating; guardrails against spurious exploration.
- Long-horizon robotics planning with world models (industry, academia; robotics): Combine sequential action proposals with learned value models/world models (e.g., MCTS variants) to sustain exploration across deep planning horizons and avoid collapse. Tools/products: “SESA-Robotics Planner” that hybridizes sequential sampling with planning/search. Assumptions/dependencies: accurate simulators; sim-to-real transfer; sample efficiency; safety constraints for physical execution.
- Enterprise coding copilots trained with exploration-preserving RL (industry; software): Scale SESA to large code models, maintaining method diversity during RLVR training across massive codebases, reducing mode collapse and brittle solutions. Tools/products: “SESA Copilot Pro” with exploration-aware training and on-the-fly diversity monitoring. Assumptions/dependencies: extensive compute; comprehensive test coverage; privacy-preserving training; organizational processes for integrating multiple candidate patches.
- Tool-use planners with diversity guarantees (industry; software/automation): Sequentially plan multi-tool workflows (search, code execution, database queries) to avoid converging on a narrow tool sequence; expand selected plans with parallel execution and feedback. Tools/products: “Diversity-Aware Task Planner” that maintains multiple viable tool-call routes. Assumptions/dependencies: robust tool interfaces; task verifiers; resource managers to bound branching cost.
- Standard-setting and compliance for ML exploration metrics (policy, industry): Establish governance that mandates diversity monitoring (Coverage@k, Pass@k ratios) in RL training of foundation models, with protocols for detecting and recovering from collapse. Tools/products: audit frameworks, certification for exploration robustness. Assumptions/dependencies: consensus on metrics and thresholds; sector-specific adaptation; alignment with safety and fairness standards.
- Energy and grid optimization under uncertainty (industry; energy): Use SESA-trained agents to maintain multiple planning strategies (load balancing, storage dispatch) validated via simulators and constraints, improving resilience across regimes. Tools/products: “SESA-Grid Planner” with diversity-aware RLVR. Assumptions/dependencies: high-fidelity simulators; multi-objective rewards; regulatory acceptance; strong safety bounds on exploration.
- Scientific discovery and hypothesis generation (academia, industry; research tools): Sequentially propose diverse hypotheses or experimental designs and expand promising ones for simulation or lab trials, preventing convergence on popular-but-suboptimal lines of inquiry. Tools/products: “SESA-Discovery” integrated with domain simulators and automated experiment pipelines. Assumptions/dependencies: domain-specific verifiers; careful reward shaping to avoid misleading simulations; collaboration with domain experts.
Notes on Feasibility, Assumptions, and Dependencies
- Verifiable rewards are central: SESA’s benefits rely on RLVR tasks with objective or tool-verifiable correctness; domains lacking reliable automatic verifiers require additional human-in-the-loop or proxy reward designs.
- Compute and latency budgets: Stage I’s sequential sketches add modest latency; Stage II’s parallel expansion restores throughput. End-to-end costs depend on G (number of sketches), context length, and candidate expansion size.
- Base model quality and instruction fidelity: Benefits are stronger when the base model can generate distinct and coherent sketches; instruction drift under long contexts is mitigated by keeping sketches concise.
- Monitoring is essential: Coverage@k and Pass@16/Pass@1 should be tracked to detect collapse and trigger fallback to sequential sampling or exploratory regimes.
- Safety and guardrails: Exploration increases diversity and may surface unconventional outputs; domains must employ guardrails, validators, and risk controls to filter invalid or unsafe candidates.
- Generalization to inference: The paper evaluates single-response inference post-training; in practice, teams can optionally adopt the two-stage (sketch → solution) pattern at inference for brainstorming and tutoring, trading latency for diversity.
Glossary
- Advantage: In policy-gradient RL, a measure of how much better an action is than a baseline, used to weight updates. "Compute advantages from "
- Autoregressive policy: A generative policy that produces tokens sequentially, each conditioned on previous tokens. "using the model's autoregressive policy "
- Coverage@k: A diversity metric measuring the fraction of distinct correct outputs found among k samples. "Higher Coverage@ indicates that the policy preserves more distinct correct paths."
- DAPO: An RL training algorithm for LLMs based on GRPO that uses parallel sampling and group-wise advantages. "trained with RL based on the DAPO algorithm (parallel sampling with )"
- Dead policy: A collapsed state where outputs become nearly identical across samples, eliminating exploration. "collapse into a ``dead policy''"
- Entropy collapse: A loss of output entropy where the model concentrates on a narrow set of solutions, reducing diversity. "entropy collapse, where models exploit a narrow set of solutions"
- Entropy regularization: Adding entropy-based terms to the objective to encourage randomness and maintain output diversity. "encourage exploration through entropy regularization."
- GRPO: Group Relative Policy Optimization, an RL objective for sequence models that normalizes advantages across sampled candidates. "algorithms like GRPO"
- i.i.d.: Independently and identically distributed; multiple samples drawn from the same distribution without conditioning. "samples all solutions i.i.d. from the same distribution"
- Monte Carlo Tree Search (MCTS): A search algorithm that explores decision trees via stochastic rollouts and value estimates to guide reasoning. "tree-search or MCTS into rollout stage"
- Off-policy learning: Learning from data generated by a different policy than the one currently being optimized. "effectively introducing ``off-policy'' learning"
- Parallel sampling: Generating multiple completions independently from the same policy for a given input. "we refer to this method of generation as parallel sampling."
- Pass@16/Pass@1 ratio: A diversity-sensitive metric comparing success at 16 samples versus a single sample to detect collapse. "Pass@16/Pass@1 ratio"
- Pass@k: The probability that at least one of k sampled outputs is correct. "pass@k evaluations"
- Policy collapse: Convergence of a policy toward highly similar outputs across samples, stalling exploration and learning. "preventing policy collapse."
- PPO: Proximal Policy Optimization, a policy-gradient RL algorithm using clipped objectives for stable updates. "policy optimization algorithms like PPO"
- RAGEN: An agent training framework used as a baseline for decision-making tasks. "We use a popular Agent framework RAGEN"
- RLHF: Reinforcement Learning from Human Feedback; uses human preference signals to train LLM policies. "Reinforcement Learning from Human Feedback (RLHF)"
- RLVR: Reinforcement Learning with Verifiable Rewards; leverages automatic correctness-based rewards to improve reasoning. "Reinforcement learning with verifiable rewards (RLVR) has become a cornerstone"
- Rollout: The process of generating candidate trajectories or solutions to compute rewards and update the policy. "each rollout generates 16 distinct samples within a single response."
- Sequential sampling: Generating candidates one by one conditioned on previous ones to actively enforce diversity. "we propose a shift in the sampling paradigm by using sequential sampling."
- State-action space: The set of possible states and actions an agent can encounter and take, over which exploration occurs. "exploring uncertain areas of the state-action space"
- Temperature (sampling): A decoding parameter controlling randomness; higher values increase diversity of samples. "setting the temperature to 1"
Collections
Sign up for free to add this paper to one or more collections.