- The paper introduces HaystackCraft, a benchmark simulating heterogeneous retrieval methods and agentic workflows to evaluate LLM robustness.
- It demonstrates that graph-based reranking effectively mitigates distractor effects, outperforming traditional sparse and dense retrieval techniques.
- Evaluation results reveal significant performance degradation in LLMs during dynamic multi-round reasoning, highlighting the need for improved context engineering.
"Haystack Engineering: Context Engineering for Heterogeneous and Agentic Long-Context Evaluation" (2510.07414)
Overview
This paper introduces HaystackCraft, an advanced benchmark designed to evaluate the robustness of Long-context LLMs in scenarios that reflect real-world complexities better than traditional needle-in-a-haystack (NIAH) assessments. The benchmark considers retrieval-dependent distractor composition and dynamic, agentic workflows that lead to cascading errors. By incorporating retrieval strategies and multi-round, LLM-dependent settings, this benchmark aims to provide a more realistic view of long-context reasoning challenges faced by LLMs.
Challenges Addressed
HaystackCraft tackles core challenges that arise from two aspects:
- Retrieval-Dependent Haystacks: Traditional NIAH benchmarks do not account for the variability introduced by different retrieval strategies. Real-world applications often deal with varied retrieval methods, such as sparse (e.g., BM25), dense (e.g., Qwen3-Embedding), hybrid, and graph-based retrievals. These methods significantly influence the noise levels in the context by varying the degree and nature of distractors included.
- Agentic Error Propagation: In advanced LLM applications that rely on dynamic, agentic workflows, cascading errors can propagate through LLM reasoning processes. This happens when early retrieval or reasoning errors are compounded over multiple reasoning steps, potentially deviating from the original intent of a query and inflating the rankings of irrelevant distractors.
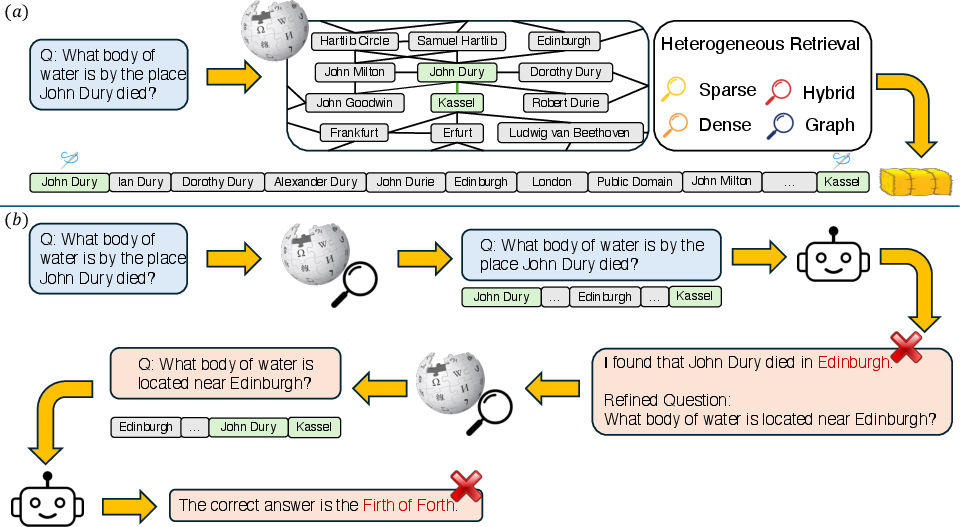
Figure 1: Overview of the core challenges that HaystackCraft addresses.
Retrieval and Haystack Composition
Retrieval Strategies
HaystackCraft evaluates the influence of distinct retrieval strategies by introducing distractors into context windows using various techniques:
- Sparse Retrieval (e.g., BM25): Generates lexical similarities which often lead to including irrelevant, yet similar-sounding documents.
- Dense Retrieval (e.g., Qwen3-Embedding): Surfaces semantically close documents that might not be factually accurate.
- Hybrid and Graph-based Reranking (e.g., Personalized PageRank): These strategies leverage both content similarity and network-based document relevance to adjust the structure and content of the context provided to an LLM.
The benchmark reveals that graph-based reranking consistently outperforms other retrieval strategies by better mitigating the distractor effect through improved document ranking, especially for multi-hop questions.
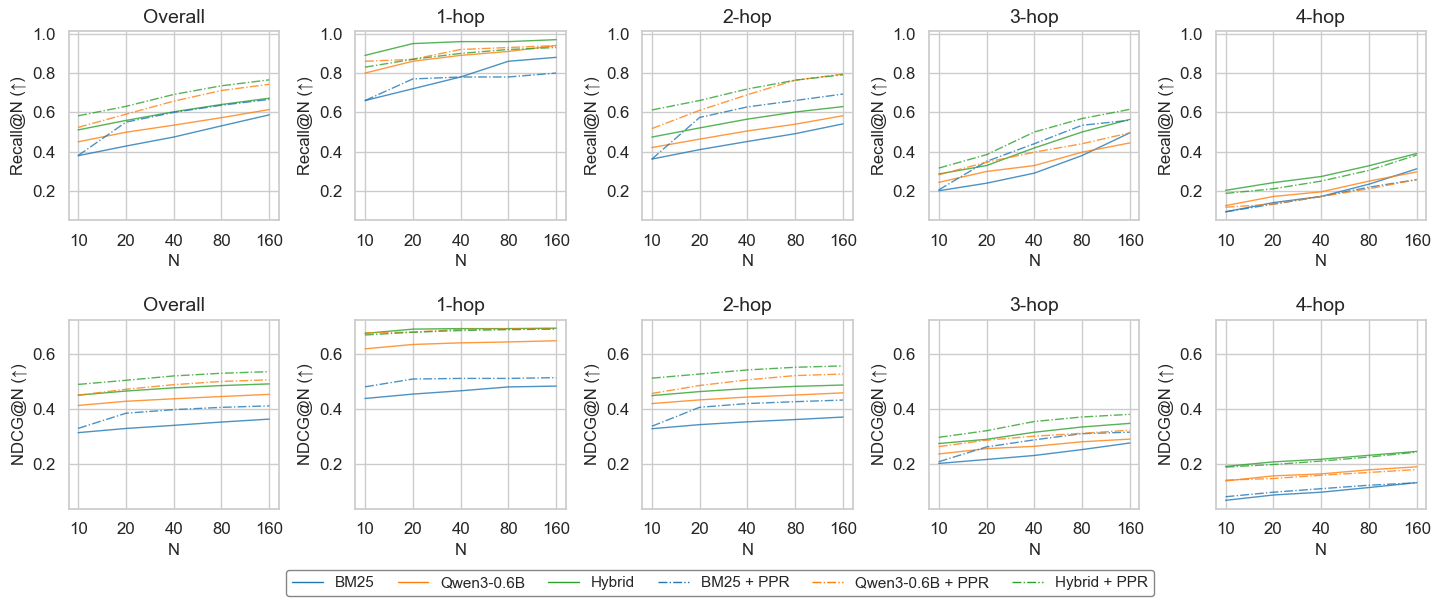
Figure 2: Improved retrieval performance with reranking using PPR.
Dynamic, LLM-Dependent Contexts
Agentic Workflows
HaystackCraft introduces dynamic NIAH tests that assess how LLMs perform in multi-round reasoning scenarios. These scenarios simulate agentic operations where LLMs refine queries, reflect on their reasoning, and determine appropriate stopping points to prevent cascading errors.
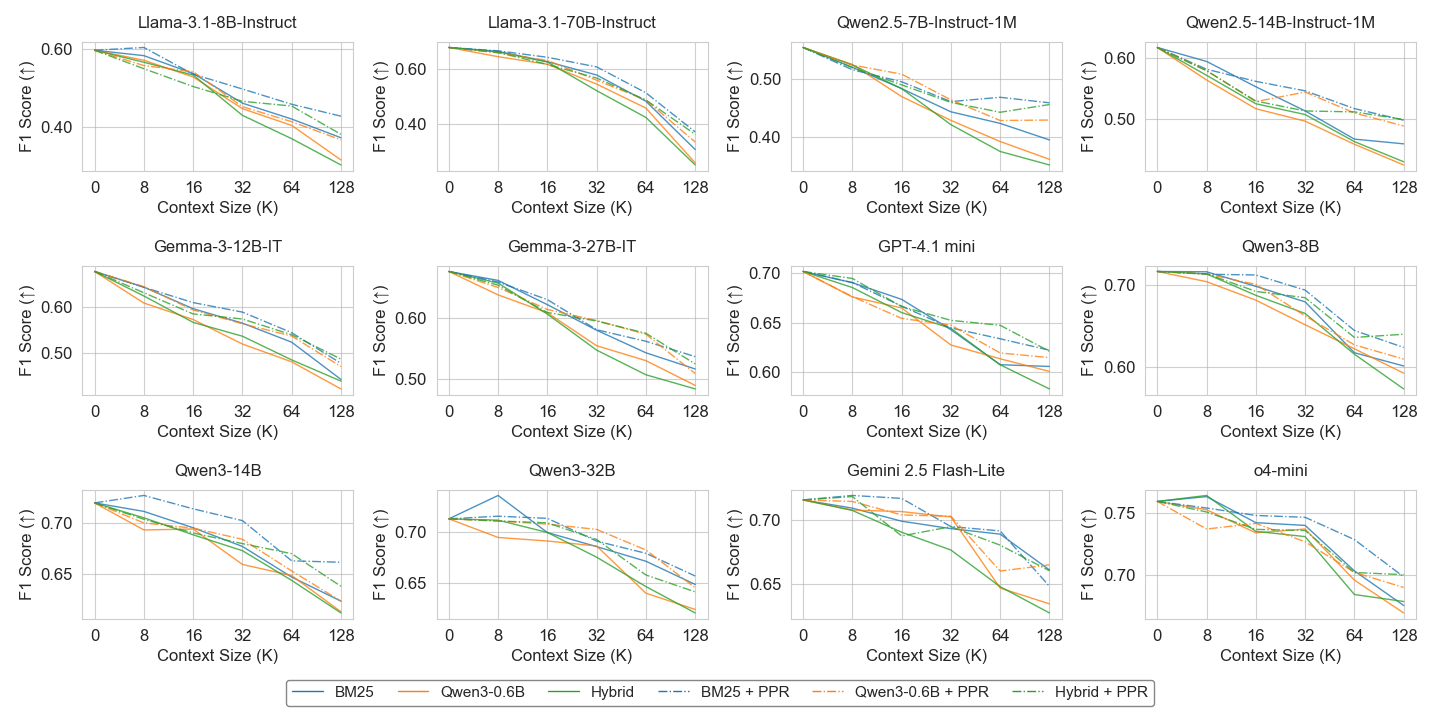
Figure 3: Performance drops as context complexity increases with enforced multi-round reasoning.
Evaluation Findings
Empirical evaluations using HaystackCraft demonstrate that current LLMs, including advanced models like Gemini 2.5 Pro and GPT-5, face significant challenges in agentic workflows. Even with sophisticated reasoning models, the study observed substantial performance degradation as the complexity of contexts increased, especially in systems requiring self-generated reasoning progression.
Conclusion
HaystackCraft serves as a critical testbed for better understanding and improving the robustness of LLMs in realistic, retrieval-based, and agentic long-context settings. The findings highlight unresolved challenges in long-context reasoning and emphasize the importance of incorporating realistic distractor management and dynamic testing conditions in LLM evaluations. This benchmark provides valuable insights and pathways for future research and development in LLM contexts to bridge the gap between theoretical capabilities and practical utility.

