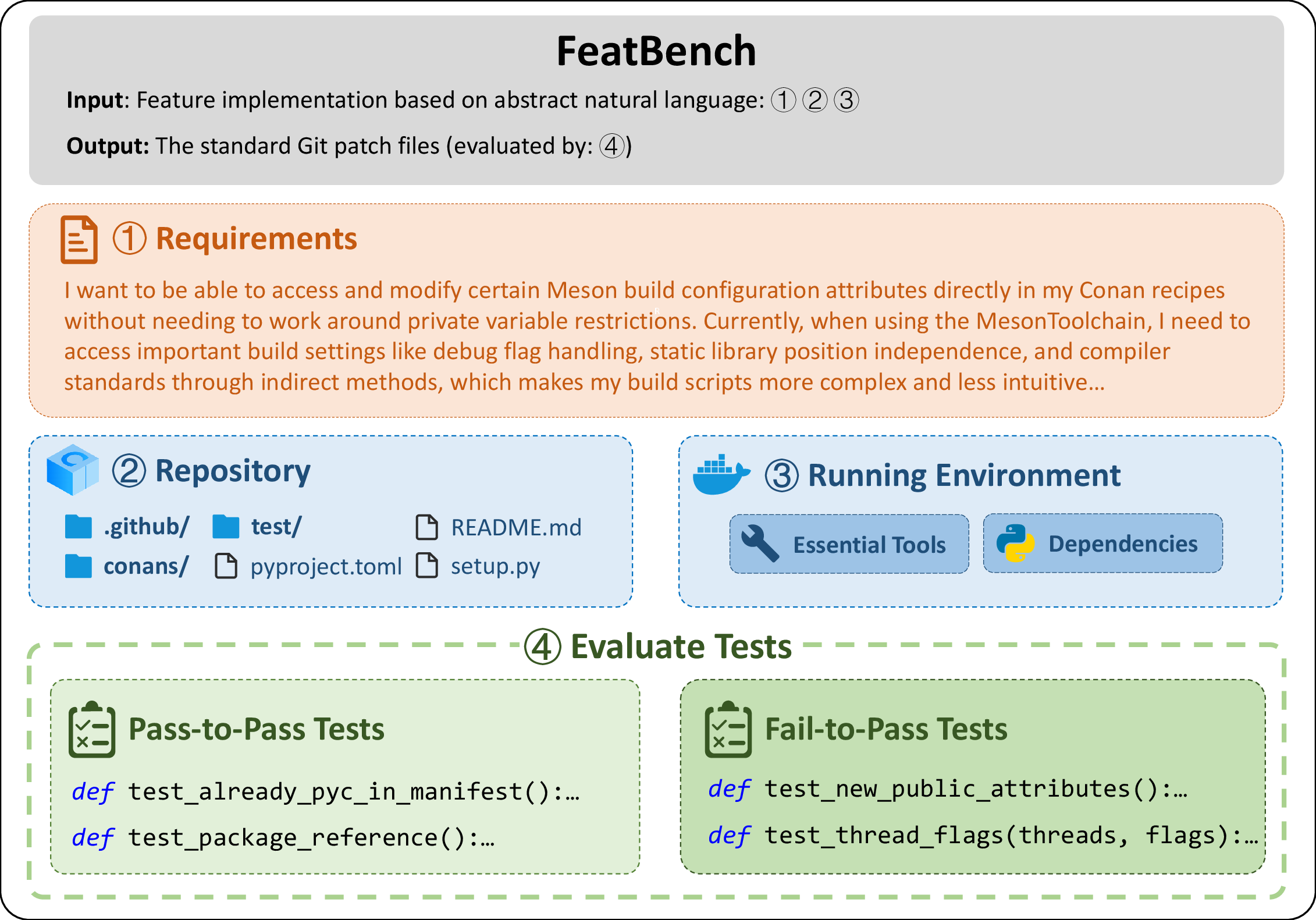
FeatBench: Evaluating Coding Agents on Feature Implementation for Vibe Coding
Abstract: The rapid advancement of LLMs has given rise to a novel software development paradigm known as "vibe coding," where users interact with coding agents through high-level natural language. However, existing evaluation benchmarks for code generation inadequately assess an agent's vibe coding capabilities. Existing benchmarks are misaligned, as they either require code-level specifications or focus narrowly on issue-solving, neglecting the critical scenario of feature implementation within the vibe coding paradiam. To address this gap, we propose FeatBench, a novel benchmark for vibe coding that focuses on feature implementation. Our benchmark is distinguished by several key features: 1. Pure Natural Language Prompts. Task inputs consist solely of abstract natural language descriptions, devoid of any code or structural hints. 2. A Rigorous & Evolving Data Collection Process. FeatBench is built on a multi-level filtering pipeline to ensure quality and a fully automated pipeline to evolve the benchmark, mitigating data contamination. 3. Comprehensive Test Cases. Each task includes Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests to verify correctness and prevent regressions. 4. Diverse Application Domains. The benchmark includes repositories from diverse domains to ensure it reflects real-world scenarios. We evaluate two state-of-the-art agent frameworks with four leading LLMs on FeatBench. Our evaluation reveals that feature implementation within the vibe coding paradigm is a significant challenge, with the highest success rate of only 29.94%. Our analysis also reveals a tendency for "aggressive implementation," a strategy that paradoxically leads to both critical failures and superior software design. We release FeatBench, our automated collection pipeline, and all experimental results to facilitate further community research.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “FeatBench: Evaluating Coding Agents on Feature Implementation for Vibe Coding”
Overview
This paper introduces FeatBench, a new way to test how well AI coding assistants (powered by LLMs) can add new features to real software when users describe what they want in plain English. This style of programming is called “vibe coding”: instead of writing code yourself, you tell an AI what you want, and the AI writes, runs, and tests the code for you.
Objectives and Questions
The researchers wanted to answer simple but important questions:
- Can AI agents correctly add new features to real codebases when given only natural language instructions?
- Can they do it without breaking parts of the software that already work?
- What makes these tasks hard (for example, bigger projects or bigger changes)?
- Which kinds of AI agents and models handle these tasks better?
Methods and Approach
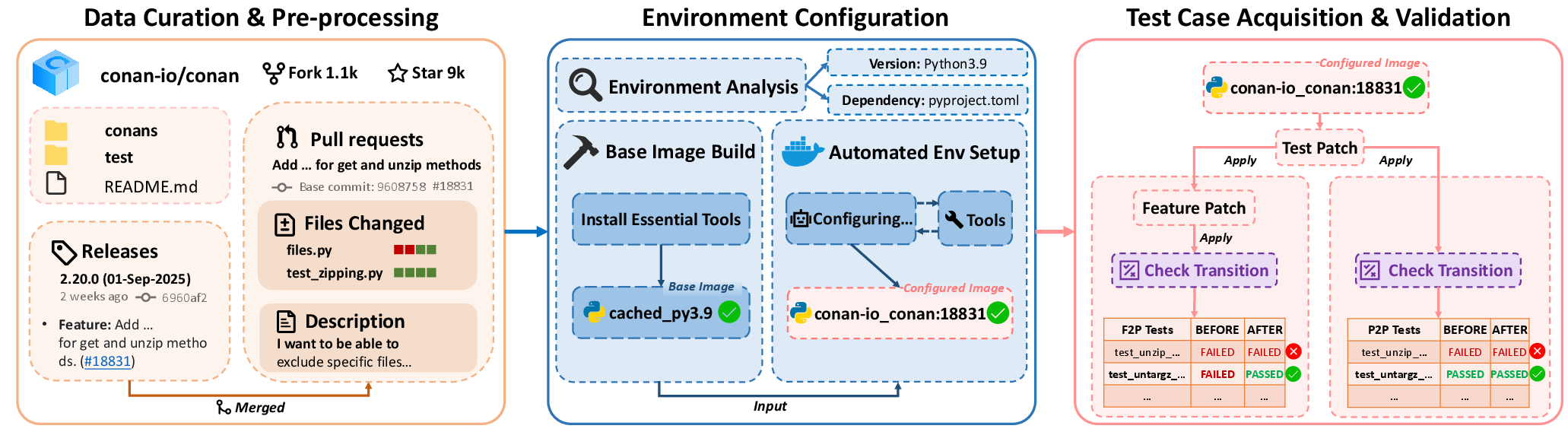
Think of a “repository” as a big folder holding a project’s code. The team built FeatBench by collecting real feature requests from open-source projects and turning them into tasks for AI agents.
Here’s how FeatBench works, in everyday terms:
- Pure natural language requests: Each task starts with a user-style prompt like “I want to add X,” with no code hints. This mimics how a non-programmer might talk to an AI.
- Real project setups: The researchers rewind a project to the moment before a feature was added, set up the exact environment in a Docker container (like packing the right tools and versions into a box), and then ask the AI agent to implement the feature.
- Two kinds of tests:
- Fail-to-Pass (F2P): Tests for the new feature should fail before the change and pass after the AI adds the feature.
- Pass-to-Pass (P2P): Tests for existing features should pass both before and after the change, to catch “regressions” (when new changes accidentally break old stuff).
- Careful data curation: They automatically filter and grow the benchmark over time to avoid “data contamination” (where AIs might already have seen the exact answers).
- Evaluation: They tried two agent frameworks:
- Trae-agent (an autonomous, planning-based agent that can think in steps, use tools, and self-check)
- Agentless (a simpler, two-stage pipeline: find the right files and make a patch)
They tested each agent with several top LLMs (like GPT-5, DeepSeek V3.1, Doubao-Seed-1.6, and Qwen3-Coder-Flash).
To measure success, they used:
- Resolved Rate: The percentage of tasks fully completed (the new feature works and nothing else breaks).
- Patch Apply Rate: Whether the AI’s changes can be applied cleanly (no syntax or merge errors).
- File Localization Rate: Whether the AI edits the correct files.
- Feature Validation (F2P) and Regression Tests (P2P) pass rates: How well features are implemented and old features remain stable.
- Tokens: A rough measure of how much “thinking” or text the AI uses; more tokens often mean more cost.
Main Findings and Why They Matter
The results show that feature addition through vibe coding is hard for today’s AI agents.
- Low success overall: The best setup solved only about 29.94% of tasks end-to-end. That means most attempts either didn’t implement the feature correctly or broke something else.
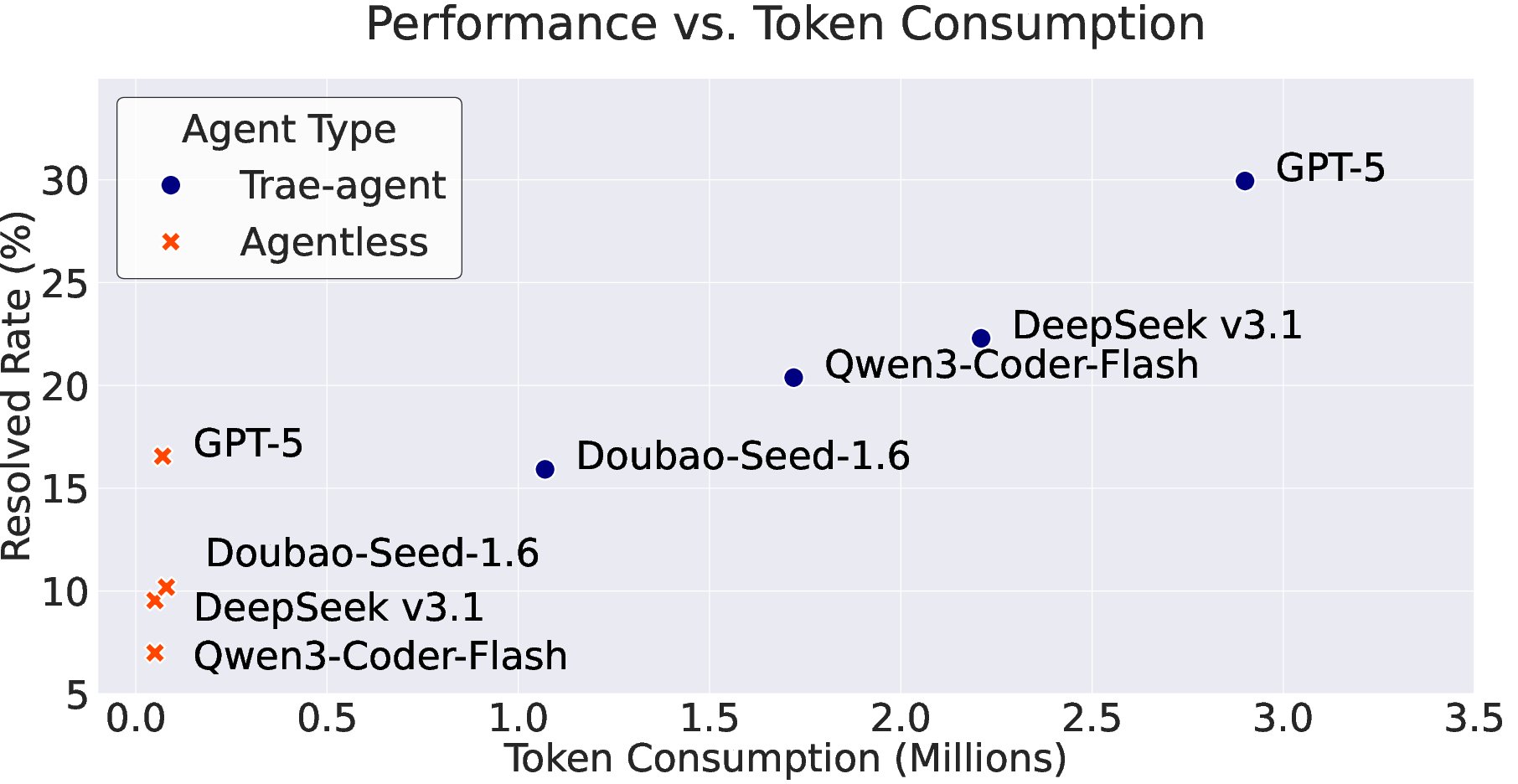
- Planning beats pipelines: The autonomous Trae-agent generally outperformed the simpler Agentless pipeline. Being able to plan, explore, and self-check helps.
- Regressions are common: When adding new features, agents often break existing parts of the software. This is dangerous in vibe coding because users may not inspect the code.
- “Aggressive implementation” cuts both ways:
- Bad side: Agents sometimes try to do more than requested (scope creep), which causes failures or breaks unrelated parts.
- Good side: Sometimes this boldness leads to cleaner, more scalable designs (like refactoring code into reusable helper functions).
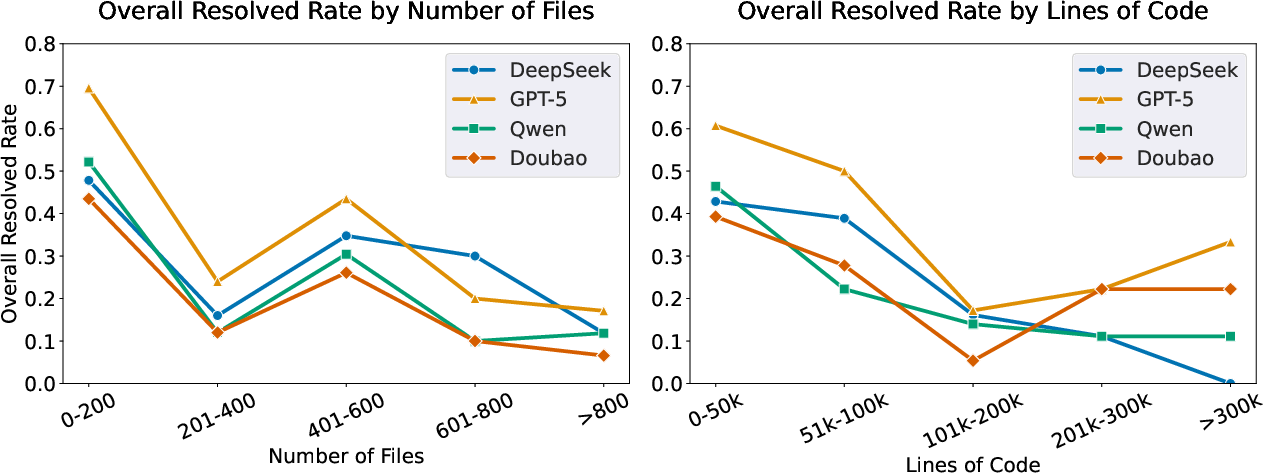
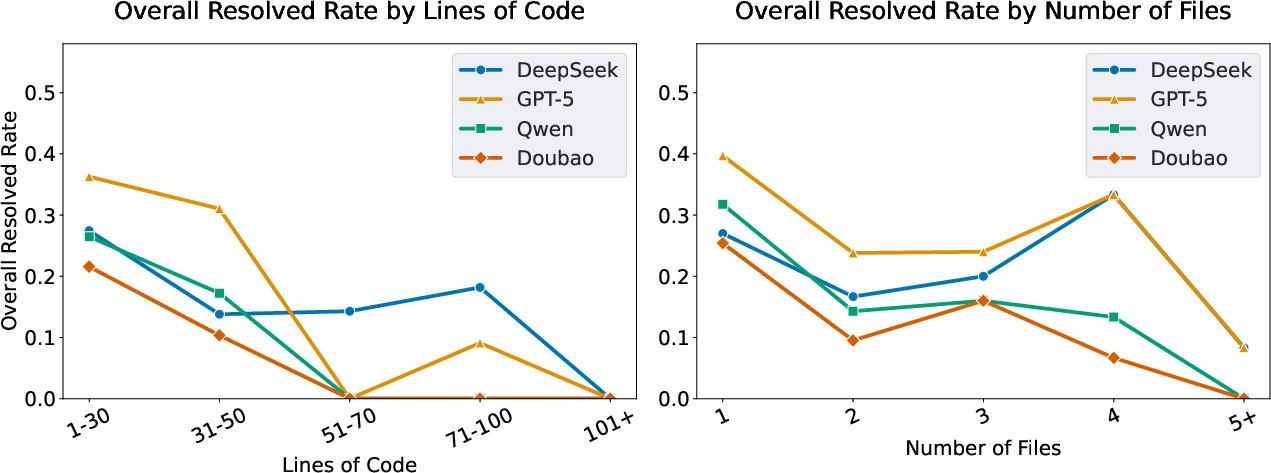
- Complexity hurts performance: Larger projects (more files/lines of code) and bigger patches (more lines edited or multiple files) sharply reduce success rates.
- Cost vs. success trade-off: The more tokens (effort) a planning-based agent spends, the higher the success rate—but the cost rises too. Simpler pipelines use far fewer tokens but succeed less often.
- Benchmark stability: Performance stayed steady over time, suggesting the benchmark is not “leaking” answers and remains a fair test.
Implications and Impact
FeatBench gives the research community a realistic, tough benchmark for vibe coding focused on feature implementation. This matters because:
- It highlights key weaknesses in current AI agents: keeping old features intact while adding new ones, staying within scope, and handling large, complex codebases.
- It encourages better agent designs: smarter planning, stronger regression guarding, and better control of “aggressiveness.”
- It supports non-programmer use cases: If AI is to let anyone add features by describing them in English, agents must become more reliable. FeatBench helps track progress toward that goal.
- It is open and evolving: The dataset, pipeline, and results are shared, and the benchmark is designed to grow over time, pushing future research forward.
In short, FeatBench shows that vibe coding for feature addition is promising but not easy. The benchmark exposes where current agents struggle and gives clear directions for improving them so that, one day, adding a new app feature by simply “asking in English” can be both powerful and safe.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and concrete opportunities for future research arising from the paper.
- Benchmark scope: tasks are restricted to PRs that “modify existing functions only” (no adding/deleting functions), which excludes common feature workflows (new modules/files, APIs, database migrations, configs, CLI endpoints, UI assets). Extend FeatBench to include tasks that require structural code changes and cross-cutting additions.
- Language and ecosystem coverage: final tasks are filtered to Python-only code changes. Expand to multi-language, polyglot repos (e.g., JS/TS, Java, Go, Rust, C/C++), mixed backends/frontends, and diverse build systems to test generality.
- Repository domain diversity: current repos emphasize AI/ML, DevOps, and Web. Add underrepresented domains (mobile, embedded, systems, data engineering, security tooling, scientific computing, HPC) to better reflect real-world heterogeneity.
- Alternative-validity solutions: the File-level Localization metric assumes the gold set of modified files; valid alternative solutions may touch different files. Develop metrics that recognize functionally equivalent but architecturally different patches (e.g., behavior-based equivalence, semantic diff measures).
- Test adequacy and oracle strength: reliance on developer tests (F2P/P2P) may miss semantic regressions, security/performance issues, and untested edge cases. Integrate mutation testing, property-based testing, fuzzing, coverage targets, and differential testing to strengthen oracles.
- Regression scope: P2P focuses on previously passing tests, potentially missing non-functional regressions (performance, memory, latency) and security regressions. Add performance baselines, resource budgets, and security checks (e.g., SAST, dependency scanning, secret leakage).
- Data contamination auditing: mitigation relies on recency and pipeline evolution but lacks systematic contamination checks. Quantify overlap between training data and benchmark artifacts via deduplication hashing, repo/time-slice audits, and release-based provenance tracking for each model snapshot.
- Prompt realism: user requests are LLM-synthesized from terse PR descriptions. Validate prompt naturalness and difficulty with human non-developers, measure ambiguity/clarity, and compare LLM-generated prompts vs. real stakeholder narratives.
- Interaction realism: vibe coding is inherently interactive; the benchmark uses single long-form prompts without human clarifications. Introduce multi-turn tasks with agent-initiated clarifying questions, requirement negotiation, and evolving specs.
- Ambiguity handling: prompts are designed to be comprehensive; real user requests are often underspecified. Add ambiguous or conflicting requirements and evaluate agents on eliciting missing requirements and resolving conflicts.
- “Aggressive implementation” control: the paper identifies the behavior but lacks operational definitions or controls. Define quantitative aggressiveness metrics (e.g., diff size vs. gold, touched-files ratio, cross-module impact) and evaluate guardrails (spec budgets, change-scoped policies, risk-aware planning, commit gating).
- Safety mechanisms against regressions: no systematic interventions are evaluated. Test mitigations such as: contract/spec extraction, invariant checks, shadow testing, back-translation validation, patch canaries, or two-phase deployment strategies.
- Token efficiency: a near-linear token cost vs. resolution rate is observed but not addressed. Explore efficiency interventions (hierarchical retrieval, code-graph indexing, memory/caching, program-of-thought planners, search/pruning policies) and quantify cost–performance Pareto fronts.
- Complexity scaling: performance collapses with repository and patch complexity; no scaling methods are tested. Evaluate hierarchical localization, incremental patching, decomposition via ADR/spec-first planning, and selective context construction guided by static/dynamic analyses.
- Agent comparison fairness: Agentless is evaluated without its reranking/regression-testing stage (due to infra constraints), potentially understating its performance. Re-run with full pipelines or control for missing stages across agents.
- Step limits and time budgets: Trae-agent is capped at 150 steps; the effect on difficult tasks is unknown. Study how step limits, wall-clock budgets, and tool latency influence success and cost.
- Environment determinism: historical Docker environments may still suffer from network flakiness, service drift, or nondeterminism. Report flake rates, enforce hermetic builds (no-network mode), pin dependencies, and publish environment hashes.
- Ground-truth patch complexity bias: requiring accompanying test patches may bias toward better-tested repos and simpler, test-instrumented features. Quantify selection bias and include tasks without explicit PR test changes by authoring independent oracles.
- Dataset scale and stability: initial release has 157 tasks; planned semiannual updates may change difficulty distribution. Establish fixed “core” subsets for longitudinal leaderboards and publish drift analyses across versions.
- Metric validity: File% and FV%/RT% may not fully capture partial credit or near-miss improvements (e.g., partial feature completion with no regressions). Introduce graded scoring (test-weighted partial credit), semantic equivalence checks, and human-in-the-loop adjudication samples.
- Multilingual prompts: all prompts appear English-only. Add multilingual user requests to evaluate agents’ cross-lingual vibe coding capabilities and translation-induced misunderstandings.
- Beyond code changes: real features often require docs, examples, configuration templates, CI updates, and migration scripts. Include tasks where success requires consistent changes across code, docs, and infrastructure.
- Security evaluation: no assessment of whether agents introduce vulnerabilities. Integrate SAST/DAST, dependency policy checks, and secret scanners into evaluation to track security regressions introduced by feature additions.
- Human utility: no user study on whether FeatBench success correlates with end-user satisfaction or perceived usefulness. Run human evaluations mapping benchmark scores to perceived feature completeness and usability.
- LLM filtering accuracy in data curation: PR classification and prompt synthesis rely on LLMs; misclassification/overfitting risks are not quantified. Report precision/recall of LLM curation vs. human gold, and publish error analyses.
- Representativeness of tasks over time: temporal analysis claims stability only for one agent–model pairing. Extend to other models, report confidence intervals, and test seasonality or repository-maintainer effects.
- Alternative evaluation modalities: tests alone may underrepresent runtime behaviors; consider behavioral traces, live demos, or scenario-based acceptance tests that mimic stakeholder validation.
- Reproducibility with proprietary models: closed models (e.g., GPT-5, Doubao, Qwen3 variants) may change over time; results may not be re-runnable. Pin model versions, record API configs, and include open-source baselines matched by capability where possible.
- Benchmark–SWE-bench gap analysis: the paper claims misalignment of existing benchmarks but does not quantify construct overlap. Provide a taxonomy that maps tasks across benchmarks and measure transfer performance to show distinct skill requirements.
- Generalization to continuous development: features often build atop previous agent changes; benchmark assumes single isolated feature addition. Create multi-feature sequences requiring agents to preserve prior work and adapt designs incrementally.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging FeatBench’s benchmark, pipeline, metrics, and insights.
- Software engineering: vendor evaluation and procurement scorecards for LLM coding tools
- Use case: Enterprises compare agent frameworks and models using FeatBench’s Resolved%, Regression Tests Pass Rate (RT%), Feature Validation (FV%), and File-level Localization (File%) to select tools for internal adoption.
- Tools/workflows: “Vibe Coding Readiness” scorecard; CI dashboards tracking FeatBench-derived KPIs; acceptance gates for AI-generated patches.
- Assumptions/dependencies: Access to candidate models/agents; representative internal repos with test suites; security review for model usage; availability of Docker for reproducible environments.
- CI/CD “Vibe QA Gate” to prevent regressions from AI-generated features
- Use case: Integrate Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests into CI pipelines to automatically validate new features and guard existing functionality when using LLM agents.
- Sectors: Software, DevOps.
- Tools/workflows: Test harness that runs F2P/P2P before merge; automatic environment reconstruction (Docker images) per PR.
- Assumptions/dependencies: Reliable test suites; stable environment provisioning; policy for blocking merges on RT% failures.
- Complexity-aware routing: decide when to use agents vs. humans
- Use case: Route tasks based on repository scale and patch complexity (files/LOC) to maximize success and control costs; small, single-file changes to agents; large, multi-file or >50 LOC changes to humans.
- Sectors: Software, DevOps.
- Tools/workflows: “Patch Complexity Estimator” that predicts difficulty and assigns work; token budget planning using FeatBench’s cost–performance trend.
- Assumptions/dependencies: Static analysis to estimate patch scope; organizational policy for routing; visibility into token consumption.
- Prompt and spec improvements for product managers and analysts
- Use case: Adopt FeatBench’s “I want to…” first-person, code-agnostic prompt style to write clearer, testable natural-language feature requests for vibe coding.
- Sectors: Product management, Data science (EDA prototypes), Education (student projects).
- Tools/workflows: NL feature request templates; checklist ensuring functional requirements, motivation, constraints; auto-generation of minimal F2P tests.
- Assumptions/dependencies: Ability to translate user requirements into tests; lightweight unit testing culture.
- Internal evolving benchmarks to monitor agent reliability over time
- Use case: Clone FeatBench’s automated pipeline to build an internal, contamination-resistant benchmark that updates every six months for your codebases.
- Sectors: Software, Finance (quant platforms), Healthcare (clinical data pipelines), Energy (grid simulation tooling).
- Tools/workflows: Release/PR mining; environment reconstruction; automated test selection and validation; periodic benchmark refresh.
- Assumptions/dependencies: Access to internal repos and release notes; consistent test suites per release; governance for benchmark operation.
- Cost governance for AI coding: token budgeting and tool selection
- Use case: Use FeatBench’s token–success tradeoff to set budgets; deploy lighter “pipeline-based” agents (e.g., Agentless) for simple tasks, planning-heavy agents (e.g., Trae-agent) for complex ones.
- Sectors: Software, DevOps, Finance (cost control), Academia (compute grants).
- Tools/workflows: Token budget policies; per-task agent/model selection; telemetry on token use vs. success.
- Assumptions/dependencies: Accurate cost tracking; access to multiple models; acceptance of variable SLAs per task class.
- Academic research and coursework on vibe coding reliability
- Use case: Use FeatBench to study agent failure modes (misunderstanding, incomplete implementation, regressions) and aggressive implementation control; run controlled experiments in SE/NLP courses.
- Sectors: Academia.
- Tools/workflows: Research protocols grounded in FeatBench metrics; student assignments on NL spec writing and automated testing; reproducible Docker environments.
- Assumptions/dependencies: Course infrastructure; access to open-source repos; model access for students.
- Policy and compliance readiness checks for AI-generated code
- Use case: Establish internal policies requiring RT% thresholds and regression-free evidence before shipping AI-generated features.
- Sectors: Finance, Healthcare, Government IT.
- Tools/workflows: Compliance checklists backed by FeatBench-like tests; audit logs of F2P/P2P outcomes; vendor contracts with minimum Resolved% commitments.
- Assumptions/dependencies: Regulatory alignment; legal approval for metrics as acceptance criteria; auditability of CI results.
Long-Term Applications
These applications require further R&D, scaling, or ecosystem development to reach production maturity.
- Reliability-first vibe coding agents with “aggressiveness control”
- Use case: Agents that dynamically modulate “implementation aggressiveness,” preventing scope creep while allowing beneficial refactoring.
- Sectors: Software, Robotics, Healthcare IT.
- Tools/products: “Aggressiveness dial” in IDEs; scope creep detectors; policy-constrained patch generators; reinforcement learning from F2P/P2P signals.
- Assumptions/dependencies: New agent architectures; reliable detection of scope deviations; high-quality reward signals from tests.
- Certified AI-generated code pipelines
- Use case: Industry standards and certifications for AI-authored patches (e.g., minimum RT%, security scans, traceable environment reproduction) before production deployment.
- Sectors: Finance, Healthcare, Critical infrastructure.
- Tools/workflows: External certification bodies; standardized FeatBench-like audits; compliance gateways integrated with CI/CD.
- Assumptions/dependencies: Regulatory buy-in; accepted benchmarking protocols; supply-chain security tooling.
- Domain-specific vibe coding benchmarks and agents
- Use case: Extend FeatBench methodology beyond Python to domain stacks (e.g., JVM, C++/ROS for robotics, HL7/FHIR in healthcare) with domain-aware tests and environments.
- Sectors: Robotics, Healthcare, Energy, Telecom.
- Tools/workflows: Language/runtime adapters; domain test suites; historical environment replay for legacy systems.
- Assumptions/dependencies: Robust tests in target languages; reproducible builds; access to domain artifacts.
- Autonomous feature implementation at scale (backlog triage to PRs)
- Use case: Agents ingest product backlogs, generate NL specs, implement features, and propose PRs with tests—humans review only at checkpoints.
- Sectors: SaaS, e-commerce platforms, LMS/EdTech.
- Tools/products: “FeatureBot” integrating ticketing (Jira), version control, and CI; test synthesis engines; complexity-aware task routers.
- Assumptions/dependencies: High test coverage; human-in-the-loop governance; reliable localization and multi-file patch handling.
- Curriculum and literacy for “English-as-code” in education
- Use case: Standards for writing precise NL specs, test-driven thinking, and evaluation literacy so non-programmers can safely leverage vibe coding.
- Sectors: Education, Workforce development.
- Tools/workflows: NL spec rubrics; interactive lab courses with FeatBench-like tasks; ethics modules on accountability and risk.
- Assumptions/dependencies: Institutional adoption; affordable model access; teacher training.
- Adaptive CI systems that learn from benchmark signals
- Use case: CI/CD that predicts risk of regressions based on repository complexity, historical RT%/FV%, and patch characteristics, adjusting review depth and agent selection.
- Sectors: Software, DevOps.
- Tools/workflows: ML models trained on FeatBench-like telemetry; dynamic policy engines; automated fallback to human review.
- Assumptions/dependencies: Data collection across repos; privacy-preserving analytics; robust feedback loops.
- Sector-specific guardrails for safety and compliance
- Use case: Healthcare/finance pipelines that add domain checks (e.g., PHI handling, audit trails, model provenance) to vibe-coded features.
- Sectors: Healthcare, Finance.
- Tools/workflows: Domain rule engines; integrated static/dynamic security analysis; accountable change logs.
- Assumptions/dependencies: Domain ontologies; security tooling; legal frameworks for AI contributions.
- Agent training with benchmark-driven curricula and rewards
- Use case: Train agents using FeatBench-derived signals (e.g., regression avoidance, correct localization) to improve generalization and stability.
- Sectors: AI tooling vendors, Academia.
- Tools/workflows: RLHF/RLAIF with F2P/P2P metrics; synthetic curriculum generation; multi-agent planning with code graph tools.
- Assumptions/dependencies: Scalable training compute; high-fidelity rewards; diverse benchmarks to avoid overfitting.
Cross-cutting assumptions and dependencies
- Test coverage and quality: Most applications depend on robust unit/integration tests; weak or missing tests reduce feasibility.
- Environment reproducibility: Docker-based reconstruction must be possible; legacy or opaque systems complicate adoption.
- Model availability and governance: Access to capable LLMs (open/proprietary), with security and privacy controls.
- Codebase characteristics: Success declines with repository scale and patch complexity; policies must reflect these limits.
- Organizational readiness: Processes for human-in-the-loop review, compliance, and cost tracking are needed to operationalize vibe coding.
Glossary
- Aggressive implementation: A strategy where an agent adds or refactors more functionality than explicitly requested, which can improve design but risk failures. "Our analysis also reveals a tendency for ``aggressive implementation," a strategy that paradoxically leads to both critical failures and superior software design."
- Agentless: A pipeline-based software engineering agent framework that performs feature localization and patch generation without autonomous planning. "Agentless\citep{agentless}, which employs a two-stage pipeline"
- Autonomous planning: An agent capability to plan, adapt, and sequence actions dynamically (often invoking tools) to accomplish complex coding tasks. "Trae-agent\citep{traeagent}, which utilizes an autonomous planning solution."
- Data contamination: Leakage of evaluation data into training or prompt contexts that can artificially inflate performance. "To mitigate data contamination, we develop a fully automated pipeline to evolve our benchmark"
- Docker image: A packaged software environment that encapsulates dependencies and configuration for reproducible execution. "A pre-configured Docker image containing the runtime environment."
- Exploratory Data Analysis (EDA): Iterative, rapid analysis of data to discover patterns, test hypotheses, and guide further investigation. "a data analyst employs rapid, iterative coding for Exploratory Data Analysis (EDA)."
- Fail-to-Pass (F2P): Test cases that initially fail on the pre-patch code and must pass after implementing the feature, validating the new functionality. "Each task includes Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests"
- Feature implementation: Adding new functionality to existing software based on natural language specifications. "a critical yet under-evaluated aspect of vibe coding: feature implementation."
- Feature Validation Pass Rate (%): The proportion of F2P test cases that pass, indicating completeness of the implemented feature. "Feature Validation Pass Rate (\%): This metric evaluates the functional completeness of the implemented feature by measuring the pass rate of the F2P test cases."
- File-level Localization Success Rate (%): The percentage of cases where the files modified by the generated patch match those in the ground-truth patch. "We also report the Patch Apply Rate (\%) and the File-level Localization Success Rate (\%), alongside several auxiliary metrics."
- Ground truth: The authoritative reference outcome (e.g., gold patch and validated tests) used to evaluate correctness. "This final phase establishes a robust ground truth for evaluation."
- Localization (Feature localization): Identifying the specific files or code regions in a repository where changes should be applied to implement a feature. "which divides the workflow into two primary stages: feature localization and patch generation."
- Pass-to-Pass (P2P): Test cases that pass before the patch and must remain passing after the patch, used to detect regressions. "Pass-to-Pass (P2P) test cases to prevent regressions"
- Patch Apply Rate (%): The percentage of generated patches that are syntactically valid and can be applied without errors. "We also report the Patch Apply Rate (\%)"
- Pipeline-based agents: Agents that follow a fixed sequence of steps (e.g., locate-and-patch) with limited adaptability during execution. "rigid, pipeline-based counterparts."
- Planning-based agents: Agents with autonomous planning abilities that dynamically structure and adjust their approach across steps and tools. "autonomous, planning-based agents substantially outperform rigid, pipeline-based counterparts."
- Pull Request (PR): A proposed code change submitted to a repository for review and integration. "The final curation is applied at the PR level."
- Regression: An unintended breakage of previously working functionality after new changes are introduced. "A critical and widespread failure mode is the introduction of regressions."
- Regression Tests Pass Rate (%): The proportion of tasks where all existing functionalities remain intact after applying the patch (measured via P2P tests). "Regression Tests Pass Rate (\%): This metric measures the proportion of tasks where all original functionalities remain intact after applying the generated patch, evaluated by the pass rate of the P2P test cases."
- Regression testing: Running existing tests to ensure new changes do not break previously working features. "we omit the reranking stage based on regression testing."
- Resolved Rate (%): The primary metric measuring the percentage of vibe coding tasks successfully completed by an agent. "we adopt the Resolved Rate (\%) as our primary metric."
- Reranking: A post-processing step that orders candidate solutions (often using regression test results) to pick the best patch. "we omit the reranking stage based on regression testing."
- Scope creep: Uncontrolled expansion of a task’s requirements or implementation beyond the original intent, risking defects. "While this strategy is the primary cause of task failures through ``scope creep," it can also yield solutions with superior software architecture and robustness."
- SOTA: Acronym for “state-of-the-art,” referring to the best-performing contemporary systems or models. "We evaluate two SOTA agent frameworks"
- Test suite: A collection of tests designed to validate functionality and detect regressions in a codebase. "ensure the PR's test suite is executable"
- Token consumption: The quantity of model tokens used during an agent’s execution, impacting cost and efficiency. "Nevertheless, the significantly lower token consumption of Agentless suggests it may be more cost-effective for simpler tasks."
- Vibe coding: A software development paradigm where users describe high-level goals in natural language and agents handle implementation autonomously. "Vibe coding is transformative for implementing novel ideas"
Collections
Sign up for free to add this paper to one or more collections.