Large Language Models Achieve Gold Medal Performance at the International Olympiad on Astronomy & Astrophysics (IOAA) (2510.05016v2)
Abstract: While task-specific demonstrations show early success in applying LLMs to automate some astronomical research tasks, they only provide incomplete views of all necessary capabilities in solving astronomy problems, calling for more thorough understanding of LLMs' strengths and limitations. So far, existing benchmarks and evaluations focus on simple question-answering that primarily tests astronomical knowledge and fails to evaluate the complex reasoning required for real-world research in the discipline. Here, we address this gap by systematically benchmarking five state-of-the-art LLMs on the International Olympiad on Astronomy and Astrophysics (IOAA) exams, which are designed to examine deep conceptual understanding, multi-step derivations, and multimodal analysis. With average scores of 85.6% and 84.2%, Gemini 2.5 Pro and GPT-5 (the two top-performing models) not only achieve gold medal level performance but also rank in the top two among ~200-300 participants in all four IOAA theory exams evaluated (2022-2025). In comparison, results on the data analysis exams show more divergence. GPT-5 still excels in the exams with an 88.5% average score, ranking top 10 among the participants in the four most recent IOAAs, while other models' performances drop to 48-76%. Furthermore, our in-depth error analysis underscores conceptual reasoning, geometric reasoning, and spatial visualization (52-79% accuracy) as consistent weaknesses among all LLMs. Hence, although LLMs approach peak human performance in theory exams, critical gaps must be addressed before they can serve as autonomous research agents in astronomy.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tests how well powerful AI LLMs can solve tough astronomy and physics problems from a real international competition, the International Olympiad on Astronomy and Astrophysics (IOAA). The main idea is to see whether these AIs can think through multi-step science problems like top students do, not just answer simple quiz questions.
What questions did the researchers ask?
The researchers focused on a few simple questions:
- Can today’s AI models solve IOAA problems at a medal level, like top human students?
- Which kinds of problems are they good at, and which kinds still trip them up?
- Do they handle not only math and concepts, but also real data, graphs, and diagrams?
- Are the results reliable and not just memorized from the internet?
How did they test the AIs?
First, a quick note: IOAA is like the “Olympics” for high school astronomy. It has three parts:
- Theory: deep science questions that need multi-step reasoning and math.
- Data Analysis: working with real astronomy data, charts, and plots.
- Observation: using instruments and the night sky (not used here, because AIs can’t point telescopes).
What the researchers did:
- They collected four years of IOAA problems (2022–2025): 49 theory questions and 8 data analysis tasks of different difficulty levels.
- They tested five top AI models: GPT-5, Gemini 2.5 Pro, OpenAI o3, Claude Opus 4.1, and Claude Sonnet 4.
- Each AI got the exact same question text and any figures. They were asked to show their work step by step, like students do.
- Two IOAA experts graded the AI answers using the official scoring rules, discussed any differences, and agreed on final scores.
- To check against memorization, they paid special attention to the 2025 exam (given after the models’ knowledge cutoffs), which serves as a “fresh” test. The AIs performed similarly there, suggesting results weren’t just from memorized answers.
A few terms in everyday language:
- LaTeX: a way to neatly write math and science solutions (like a very clean digital “handwriting” for equations).
- Multimodal: handling not just words, but also images, charts, and plots.
- Spherical trigonometry: geometry on a sphere (like Earth’s surface), used for things on the sky dome, not flat paper.
What did they find?
Big picture:
- On the theory exams, GPT-5 and Gemini 2.5 Pro scored around 84–86% on average—good enough for gold medals and even top-2 rankings among roughly 200–300 human participants each year.
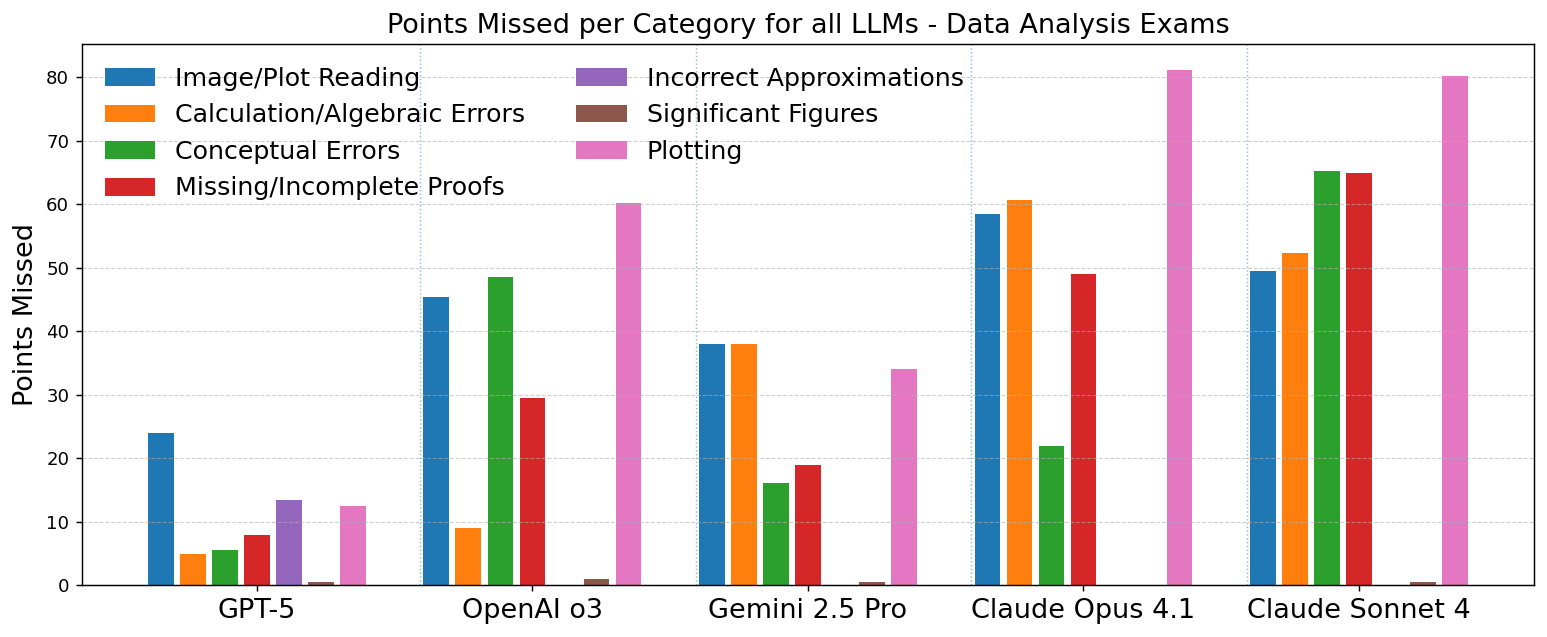
- On the data analysis exams, GPT-5 did extremely well (about 88.5% average, often top 10 among humans). Other models dropped more (roughly 48–76%), especially when they had to read or make plots.
More details on strengths and weaknesses:
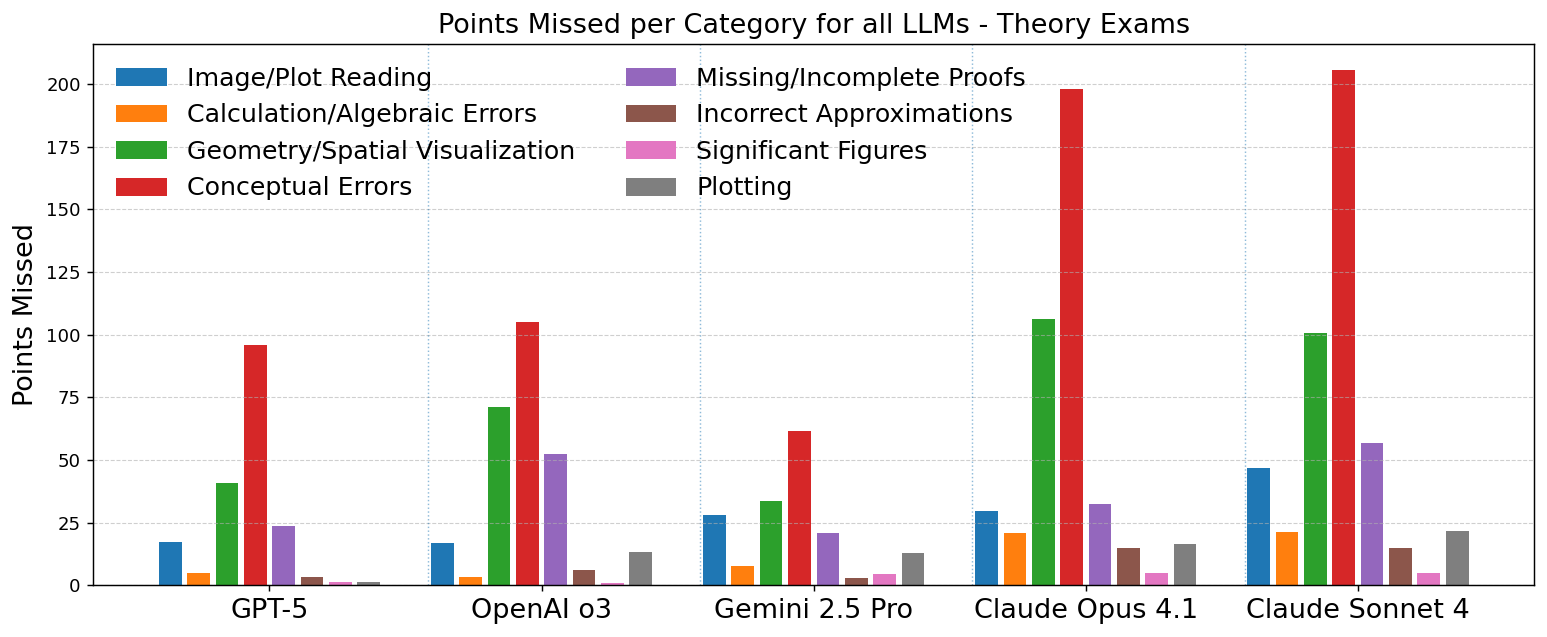
- Strong: Physics and math reasoning. When problems were mostly calculations and scientific concepts (like astrophysical formulas and estimates), the top AIs did very well.
- Weak: Geometry and spatial thinking. Problems that need you to picture the sky, rotate coordinates, or do math on a sphere were much harder. For example, picking the right angles on the “celestial sphere,” or understanding time systems (tropical vs. sidereal year), often led to mistakes.
- Mixed: Working with charts and plots. GPT-5 read and made plots more accurately than the others. For some models, plotting and reading figures was the biggest source of errors.
- Most common errors: Conceptual misunderstandings (using the wrong idea or formula) and geometric/spatial mistakes (trouble visualizing shapes in 3D or on a sphere) caused most lost points. Simple arithmetic slips were less important overall in theory, but showed up more in data analysis because there are many small calculations.
Why this matters:
- The best AIs now solve difficult, multi-step science problems at a level that rivals top human competitors. That’s a big leap beyond simple quiz-style tests.
What does this mean for the future?
Simple takeaways:
- Helpful co-scientists: These AIs can already help students and researchers check equations, explore ideas, and reason through many astronomy problems.
- Not fully independent yet: They still struggle with visual-spatial tasks, spherical geometry, and some chart understanding. Human checking is still important—especially for diagrams, time systems, and geometry-heavy steps.
- How to improve AIs: Giving them better “visual thinking” tools (like a sketchpad to draw and reason with shapes), training them more on reading and creating scientific plots, and practicing with realistic astronomy data should make them stronger.
- Bigger picture: As these models get better at spatial and multimodal reasoning, they could speed up real discoveries in astronomy by handling more of the careful, step-by-step work scientists do.
In short, today’s AIs can earn gold medals on tough astronomy theory exams and do very well on data tasks—especially the top models—yet they still need to get better at thinking in pictures (space, angles, and spheres) before they can act like fully independent astronomy researchers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed concretely so future work can act on it.
- Evaluation excludes the IOAA observation exam; design and assess simulated observation tasks (e.g., star-chart navigation, telescope pointing/calibration, real-time sky conditions) to cover hands-on skills central to astronomy.
- Generalization to real research workflows is untested; benchmark LLMs on end-to-end tasks using real astronomical data products (FITS images, spectra, catalogs), code execution (e.g., AstroPy), and archive queries (e.g., SDSS, Gaia) within tool-augmented agent settings.
- Multimodal reasoning is only probed via static exam figures and LaTeX plotting; assess performance on richer modalities (FITS visualization, spectral line identification, multi-instrument cross-matching, multi-band photometry) and interactive 3D geometry/visualization tasks.
- Data contamination for 2022–2024 is inferred to be minimal but not audited; perform formal contamination detection (e.g., web-scale search for overlaps, model “copying” checks, nearest-neighbor retrieval tests) and sensitivity analyses to quantify its effect on scores.
- Single-shot evaluation masks variance; measure performance stability across multiple runs/seeds and under self-verification/reflection loops to estimate reliability and best-of-N versus first-pass behavior.
- Prompting effects are not studied; run ablations comparing different prompt styles (concise vs. verbose, tool-use directives, hidden vs. explicit chain-of-thought) and quantify prompt sensitivity on scoring and error types.
- Tool augmentation is restricted (e.g., no calculators/Python during solving); compare baseline to tool-enabled agents (symbolic math, numerical solvers, plotting libraries) to isolate the gains from computation and external tools.
- Grading reliability is not quantified; report inter-rater agreement (e.g., Cohen’s κ) and release a detailed rubric-to-score mapping for each problem to enable independent verification and meta-evaluation.
- Potential verbosity-to-partial-credit bias is unaddressed; test whether longer, highly verbose solutions systematically earn more partial credit than concise correct steps, and normalize grading to control for verbosity.
- Human comparison and medal rankings are inferred from theory/data-analysis components only; evaluate how excluding the observation component alters rank estimates, or develop methods to approximate observation scores for a fairer holistic comparison.
- Statistical rigor on year-to-year comparability is limited; apply formal tests (e.g., mixed-effects models) to separate model effects from annual variation in topic mix, style, and difficulty, and reweight scores by topic distribution.
- Dataset scale is small (49 theory, 8 data analysis problems across four years); expand coverage with additional IOAA years and construct validated, IOAA-like synthetic problems to increase statistical power, especially for data analysis tasks.
- Error taxonomy lacks reproducibility measures; formally define each error category, release annotated errors per problem/model, and measure inter-annotator agreement to make the taxonomy reusable and comparable across studies.
- Calibration and uncertainty are not assessed; require models to provide confidence estimates, then evaluate calibration (e.g., Brier score, ECE) and whether confidence correlates with correctness across problem types.
- Robustness to noisy/incomplete/problematic inputs is untested; introduce realistic perturbations (typos, missing constants, conflicting figures, ambiguous phrasing) to quantify resilience and failure modes under non-ideal conditions.
- Spatial reasoning interventions are not evaluated; test sketchpad/drawing tools, geometric solvers, and explicit diagram generation pipelines to quantify their impact on spherical trigonometry and celestial geometry tasks.
- Targeted deficits (sidereal vs. tropical years, calendar vs. tropical year equivalence, great-circle geometry) are observed but not isolated; build focused micro-benchmarks to measure mastery of timekeeping systems and spherical trigonometry independently of broader context.
- LaTeX plotting (tikz/pgfplots) is atypical for astronomical practice; compare performance using standard scientific plotting (matplotlib, seaborn) and dataframes to see if plotting errors are format-specific rather than reasoning-related.
- Multilingual capability (common in international olympiads) is not evaluated; assess performance on problems in multiple languages and mixed-language settings to test robustness and accessibility.
- Context-length and file-handling constraints are not probed; evaluate tasks requiring long tables, external file ingestion (FITS, CSV), and iterative refinement across multi-turn dialogues to reflect realistic data analysis workflows.
- Latency, cost, and throughput are not reported; measure time-to-solution, API costs, and computational budget to assess practical viability compared to human effort in competitive or research settings.
- Model versioning and reproducibility are under-specified; log exact model builds/dates and re-run a subset after provider updates to quantify performance drift and ensure longitudinal reproducibility.
- Retrieval-augmented reasoning is not examined; compare closed-book solving to retrieval from vetted astronomical references (textbooks, papers, catalog docs) to determine whether knowledge access mitigates conceptual errors.
- Release of full artifacts is partial; publish raw model outputs, compiled PDFs, per-step rubric scores, and error annotations (with licenses) to enable third-party replication and meta-analysis.
Practical Applications
Immediate Applications
Below are applications that can be deployed now by leveraging the paper’s findings, methods, and released code, with human oversight and guardrails.
- Astronomy theory co-pilot for derivations and sanity checks (Academia, Software)
- Use cases: verify formulas, carry out multi-step derivations, order-of-magnitude estimates, unit checks, and LaTeX-ready write-ups for sections of papers and problem sets.
- Tools/workflows: “AstroLaTeX Copilot” that ingests problems in LaTeX, produces step-by-step solutions and embedded plots (TikZ/pgfplots), and flags places requiring human review.
- Assumptions/dependencies: access to high-performing multimodal LLMs (e.g., GPT-5, Gemini 2.5 Pro), LaTeX toolchain integration, human-in-the-loop to catch geometric/timekeeping mistakes.
- Lab data analysis assistant for astronomy (Academia, Space industry)
- Use cases: light-curve interpretation, spectral line identification, basic catalog filtering, plotting with captions, initial statistical summaries for observational datasets.
- Tools/workflows: “AstroDA Assistant” integrated into Jupyter/VS Code; uses IOAA-style prompts and the constants reference to produce figures and reasoning.
- Assumptions/dependencies: model with strong chart-reading ability (GPT-5 performs best), institutional data access permissions, standardized plotting/checks, human verification due to plotting and reading error risks.
- Olympiad and coursework tutoring with rubric-aware feedback (Education, Daily life)
- Use cases: personalized practice for IOAA-style problems, formative feedback aligned with official rubrics, targeted remediation on common failure modes (spherical trig, calendar vs sidereal year).
- Tools/products: “Olympiad Coach AI” that grades LaTeX or handwritten-to-LaTeX solutions, highlights conceptual vs geometric errors, and generates tailored exercises.
- Assumptions/dependencies: reliable mapping from solutions to rubrics, bias/fairness controls, teacher oversight, misuse prevention (e.g., academic integrity policies).
- IOAA-based scientific reasoning benchmark for AI procurement and R&D (Industry, Academia, Policy)
- Use cases: model evaluation beyond recall (multi-step reasoning, derivations, multimodal chart tasks), capability tracking across versions, vendor comparisons.
- Tools/products: “IOAA-Bench” harness with grading scripts, error taxonomy dashboards, contamination checks, medal-threshold reporting.
- Assumptions/dependencies: licensing/permissions for past problem use, independent expert graders or calibrated auto-graders, reproducible prompts and versions.
- Reasoning quality assurance plugin for LLM outputs (Software, Academia)
- Use cases: automatic detection/flagging of conceptual misapplications, geometric inconsistencies, missing intermediate steps, and notation issues in LaTeX solutions.
- Tools/products: “GeomCheck” and “ReasoningDiff” plugins that parse LaTeX, apply astronomy-specific rules, and surface high-risk segments for review.
- Assumptions/dependencies: robust LaTeX parsing, domain rule sets, integration with CI pipelines; does not replace expert validation.
- Multimodal training data synthesis for chart understanding (ML research, Industry)
- Use cases: generating visual question-answer pairs from astronomy plots (light curves, spectra) to improve chart reading performance, with labels derived from known solutions.
- Tools/workflows: “AstroChart VQA Builder” that converts IOAA-style plots and solutions to VQA items; curriculum learning for plot types that models underperform on.
- Assumptions/dependencies: dataset rights, physically consistent labeling, compute for fine-tuning, evaluation with held-out real plots.
- LaTeX-first reproducible analysis pipeline (Academic publishing, Software)
- Use cases: standardized, auditable AI-assisted derivations and figures embedded in manuscripts; improved transparency in mathematical and astrophysical reasoning.
- Tools/workflows: “ReproLaTeX” workflow using the paper’s prompt template, constants sheet, and compilation scripts; provenance logging of model versions and prompts.
- Assumptions/dependencies: journal/editorial acceptance, reliable PDF compilation, provenance and disclosure policies.
- Governance checklist for scientific AI adoption (Policy, Academia, Industry)
- Use cases: institutional guidelines requiring gold-medal-equivalent performance on ecologically valid benchmarks before deploying AI in sensitive scientific tasks; contamination risk reporting; human oversight mandates.
- Tools/workflows: “SciAI Readiness Checklist” referencing IOAA thresholds, error profiles (conceptual/geometric), and multimodal requirements.
- Assumptions/dependencies: policy buy-in, periodic audits, independent evaluation resources.
- Public outreach and planetarium assistants for celestial mechanics explanations (Education, Daily life)
- Use cases: guided explanations of eclipses, seasons, retrograde motion; interactive Q&A, with safeguards on spherical trig and timekeeping pitfalls.
- Tools/products: “SkyExplainer” kiosk/assistant using structured prompts and curated content; flags geometry-heavy queries for simplified visuals.
- Assumptions/dependencies: curated scenario design, alignment with exhibits, human content review.
- Corporate data literacy training for chart interpretation (Industry)
- Use cases: practical exercises on reading scientific charts and avoiding common misreads; feedback driven by the paper’s error taxonomy.
- Tools/products: “ChartCoach” training modules with AI co-tutor; domain-neutral plots adapted from astronomy to business analytics.
- Assumptions/dependencies: content generalization, trainee privacy, careful transfer from scientific to business contexts.
Long-Term Applications
Below are opportunities that require further research, scaling, or capability development (e.g., spatial visualization, multimodal robustness, certification).
- Autonomous astronomy research agents with visual sketchpad reasoning (Academia, Space industry)
- Vision: end-to-end agents that form hypotheses, derive models, visualize 3D celestial geometry, interpret multi-modal datasets, generate publication-grade LaTeX with figures, and plan follow-up analyses.
- Tools/products: “AstroAgent” with integrated visual sketchpad, symbolic math, and data pipeline orchestration.
- Assumptions/dependencies: reliable spatial/temporal reasoning, calibrated uncertainty, ethical and authorship frameworks, sustained human oversight.
- Visual sketchpad-integrated LLMs for spatial/temporal reasoning across domains (Robotics, CAD, Geoscience, Education)
- Vision: models that draw, manipulate, and reason over sketches/diagrams (spherical trig, vectors, kinematics) to eliminate current geometric failures.
- Tools/products: “Spatial Sketchpad for LLMs” with diagram editors, geometric constraint solvers, and consistency checks.
- Assumptions/dependencies: new training regimes (diagrammatic reasoning), multimodal benchmarks, safety and reliability testing.
- Observatory operations co-pilot (Space industry)
- Vision: AI-assisted scheduling, instrument calibration, anomaly detection, and dynamic observation planning using real-time telemetry and forecasted constraints.
- Tools/products: “Observatory Ops Copilot” linked to facility schedulers and data acquisition systems.
- Assumptions/dependencies: secure integration with operational systems, rigorous validation, compliance with safety/mission-critical standards.
- Standardized science-AI certification using Olympiad-style benchmarks (Policy, Industry, Academia)
- Vision: regulatory-grade evaluations across physics, astronomy, chemistry, and biology using ecologically valid problems and independent grading for model certification.
- Tools/products: “SciAI Cert” program and cross-olympiad benchmark suites; public scorecards with medal thresholds and error profiles.
- Assumptions/dependencies: broad stakeholder consensus, funding for independent evaluators, governance over dataset contamination.
- Cross-domain improvements in multimodal reasoning for high-stakes fields (Healthcare, Energy, Finance)
- Vision: robust chart/image understanding reduces misinterpretation in radiology, epidemiology dashboards, grid operations charts, and market analytics.
- Tools/products: domain-fine-tuned chart/VQA models with confidence calibration and audit trails.
- Assumptions/dependencies: clinical and regulatory approvals, domain-specific datasets, risk controls, human oversight.
- AR/VR platforms teaching spherical trigonometry and celestial visualization with AI guidance (Education, Daily life)
- Vision: immersive learning where AI tutors help students build spatial intuition and solve geometry-heavy astronomy problems.
- Tools/products: “Celestial AR Tutor” integrated with headsets, interactive sky domes, and assessment engines.
- Assumptions/dependencies: affordable AR hardware, validated pedagogy, accessibility and safety features.
- Navigation and satellite mission planning assistants leveraging robust spherical geometry (Aerospace)
- Vision: mission design tools that simulate orbital geometries, visibility windows, and ground station timing with precise temporal models.
- Tools/products: “GeoOrb Planner” combining AI reasoning and astrodynamics solvers.
- Assumptions/dependencies: certified accuracy, integration with existing flight dynamics software, exhaustive verification.
- Publication-grade, auditable AI pipelines for end-to-end reproducible science (Academia, Software)
- Vision: standardized provenance-tracked workflows from prompt to paper, with automated LaTeX, code notebooks, datasets, and reviewer tooling.
- Tools/products: “ReproSci Suite” with provenance graphs, model/version disclosures, and reviewer plug-ins.
- Assumptions/dependencies: community standards, journal acceptance, tooling interoperability.
- Synthetic data generation at scale for rare astronomical regimes (ML research, Academia)
- Vision: physically consistent simulators and curated synthetic corpora to train and stress-test multimodal reasoning on edge cases (rare transients, extreme noise regimes).
- Tools/workflows: “AstroSim Data Factory” paired with benchmark updates to reduce brittleness.
- Assumptions/dependencies: high-fidelity simulators, domain expert validation, compute resources.
- International collaboration frameworks for AI co-scientists (Policy, Academia)
- Vision: guidelines for authorship, accountability, and data integrity where AI systems contribute to discovery; periodic capability audits tied to benchmarks like IOAA.
- Tools/products: “AI in Science Governance Pack” with licensing, disclosure templates, and audit protocols.
- Assumptions/dependencies: legal frameworks, institutional adoption, transparent reporting norms.
Glossary
Below is an alphabetical list of advanced domain-specific terms used in the paper, each with a short definition and a verbatim example from the text.
- AstroBench: A benchmark dataset for evaluating LLMs on astronomy knowledge and tasks. "AstroBench~\cite{ting2024astromlab1winsastronomy}"
- AstroMLab: A research effort providing astronomy-focused machine learning benchmarks and evaluations. "AstroMLab~\cite{dehaan2025astromlab4benchmarktoppingperformance}"
- Astro-QA: A question-answering benchmark focused on astronomy. "Astro-QA~\cite{li2025}"
- astronomical approximation: Approximation techniques tailored to large scales and typical uncertainties in astronomy. "including complex computation, astronomical approximation, and conceptual reasoning."
- celestial coordinates: Coordinate systems used to specify positions on the celestial sphere (e.g., right ascension and declination). "angles between celestial coordinates"
- celestial mechanics: The paper of the motion of celestial bodies under gravity. "cosmology, spherical trigonometry, stellar astrophysics, celestial mechanics, photometry, and instrumentation,"
- celestial sphere geometry: Geometric reasoning on the apparent sphere surrounding the observer on which celestial objects are projected. "celestial sphere geometry, spherical trigonometry, and coordinate transformations."
- coordinate transformations: Conversions between different astronomical coordinate systems (e.g., equatorial to ecliptic). "coordinate transformations."
- cosmology: The scientific paper of the origin, structure, evolution, and ultimate fate of the Universe. "cosmology, spherical trigonometry, stellar astrophysics, celestial mechanics, photometry, and instrumentation,"
- data contamination: The presence of benchmark or test items in a model’s training data, potentially inflating evaluation scores. "Data Contamination Considerations."
- ecologically valid: Evaluation that reflects real-world conditions and tasks rather than artificial or simplified tests. "IOAA exams are more ecologically valid because they evaluate the complex reasoning, creative problem-solving, and extended derivations required in actual astronomical research."
- galactic dynamics: The paper of the motions and gravitational interactions within and between galaxies. "cosmology, galactic dynamics, instrumentation, and observational astronomy"
- great circle geometry: Geometry on a sphere involving circles whose centers coincide with the sphere’s center; critical for spherical navigation and astronomy. "inconsistent with great circle geometry."
- gravitational-wave: A ripple in spacetime produced by accelerating massive objects, detectable via interferometry. "e.g., detecting gravitational-wave \cite{wang2025automatedalgorithmicdiscoverygravitationalwave}"
- horseshoe orbits: Co-orbital trajectories where an object alternates leading and trailing another around a shared orbit, forming a horseshoe pattern. "tadpole and horseshoe orbits~\cite{DERMOTT19811}"
- International Olympiad on Astronomy and Astrophysics (IOAA): A global competition testing high-level astronomy and astrophysics problem-solving. "The International Olympiad on Astronomy and Astrophysics (IOAA) consists of three examination components:"
- light curves: Time series of an object’s brightness, used to paper variability and infer physical properties. "such as light curves, spectra, stellar catalogs, and survey outputs,"
- Moravec’s Paradox: The observation that tasks easy for humans (like perception) are often hard for AI, while logical reasoning can be easier for machines. "consistent with Moravecâs Paradox: tasks simple for humans, such as visual interpretation, remain difficult for AI."
- multimodal analysis: Problem-solving that integrates multiple data types (e.g., text, images, plots) to draw conclusions. "deep conceptual understanding, multi-step derivations, and multimodal analysis."
- multimodal capabilities: A model’s ability to process and reason over different modalities (text, figures, plots). "and possess necessary multimodal capabilities for IOAA problems."
- observational astronomy: The branch of astronomy focused on acquiring and interpreting data from observations of celestial objects. "instrumentation, and observational astronomy"
- order-of-magnitude reasoning: Estimating values within powers of ten to gauge plausibility and scale in physical problems. "astronomy olympiads place great emphasis on approximation and order-of-magnitude reasoning,"
- photometric principles: Principles governing the measurement of light intensity and flux in astronomy. "combining spherical trigonometry with photometric principles for eclipse calculations,"
- photometry: The measurement of electromagnetic radiation (brightness/flux) from celestial sources. "cosmology, spherical trigonometry, stellar astrophysics, celestial mechanics, photometry, and instrumentation,"
- retrograde motion: The apparent backward movement of a planet against the background stars due to orbital geometry. "familiar with the concept of retrograde motion."
- sidereal year: The time it takes Earth to complete one orbit relative to fixed stars, slightly longer than a tropical year. "choose between tropical and sidereal years incorrectly."
- spherical trigonometry: Trigonometry on the surface of a sphere, essential for celestial navigation and coordinate calculations. "spherical trigonometry"
- spectra: Distributions of light intensity versus wavelength or frequency, used to infer composition, temperature, and velocity. "such as light curves, spectra, stellar catalogs, and survey outputs,"
- stellar astrophysics: The paper of the physics of stars, including structure, evolution, and nucleosynthesis. "cosmology, spherical trigonometry, stellar astrophysics, celestial mechanics, photometry, and instrumentation,"
- stellar catalogs: Structured databases listing stars and their measured properties. "such as light curves, spectra, stellar catalogs, and survey outputs,"
- survey outputs: Data products generated by wide-area astronomical surveys (e.g., catalogs, maps, light curves). "such as light curves, spectra, stellar catalogs, and survey outputs,"
- tadpole orbits: Co-orbital trajectories that librate around a Lagrange point, tracing tadpole-shaped paths in a rotating frame. "tadpole and horseshoe orbits~\cite{DERMOTT19811}"
- timekeeping systems: Definitions and conventions (e.g., sidereal, tropical) used to measure time in astronomy. "confusion with timekeeping systems"
- tropical year: The time between successive vernal equinoxes, forming the basis of the civil calendar. "1 tropical year"
- vector geometry: Geometric reasoning using vectors (e.g., dot products) applied to spatial relationships on the celestial sphere. "and vector geometry."
- visual question answering: AI tasks where models answer questions about images/plots, requiring integrated visual and textual reasoning. "we can synthesize visual question answering examples at scale"
- visual sketchpad: A tool or capability that enables models to draw or visualize intermediate sketches to aid spatial reasoning. "implement visual sketchpad \cite{hu2024visual}"
Collections
Sign up for free to add this paper to one or more collections.