Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Abstract: While LLMs with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces CritPt (short for “Complex Research using Integrated Thinking – Physics Test,” pronounced “critical point”). It’s a new, tough test that checks whether today’s AI LLMs can really reason through problems that look like real physics research, not just textbook exercises. Instead of quiz-style questions, CritPt gives the AI full, open-ended challenges that require planning, math, and careful thinking—just like a junior researcher would need to do.
The big questions they asked
The authors designed CritPt to answer three simple but important questions:
- Can AI models solve new, research-style physics problems they haven’t seen before?
- If they can’t solve the whole thing, what smaller research tasks can they help with today?
- When AI gives an answer, can we trust the reasoning and the final result?
How they built the test (in simple terms)
CritPt is like a set of realistic “mini research projects,” created and checked by real physicists across many subfields. Here’s how it works.
Where the problems came from
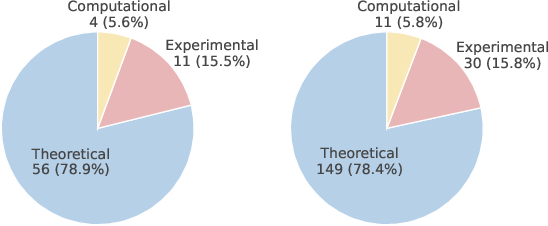
- Physicists from more than 30 institutions designed 71 full research challenges, plus 190 smaller “checkpoints.”
- These challenges span many areas—like quantum physics, condensed matter, astrophysics, fluid dynamics, biophysics, and more—and include theoretical, experimental, and computational flavors.
- Each problem is based on real research experience, including tricky steps and “insider” reasoning that usually doesn’t show up in textbooks.
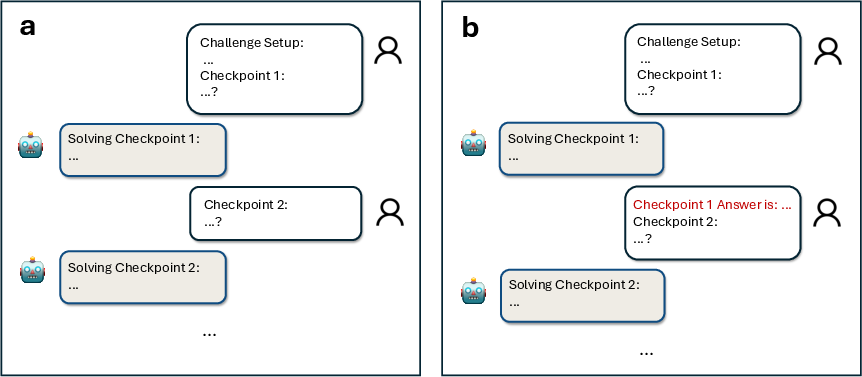
Think of a “challenge” as a whole project. A “checkpoint” is a smaller piece of the project, like a key sub-problem or an important calculation along the way.
Making problems fair and cheat-proof
The team made sure AI models couldn’t just “remember” answers from the internet:
- All problems are new and unpublished (so the answers aren’t online).
- Questions are open-ended (not multiple choice) and require returning exact numbers, formulas, or working code.
- Answers are hard to guess—often long expressions, arrays of numbers, or precise values.
This setup rewards real reasoning, not lucky guesses.
How answers are checked
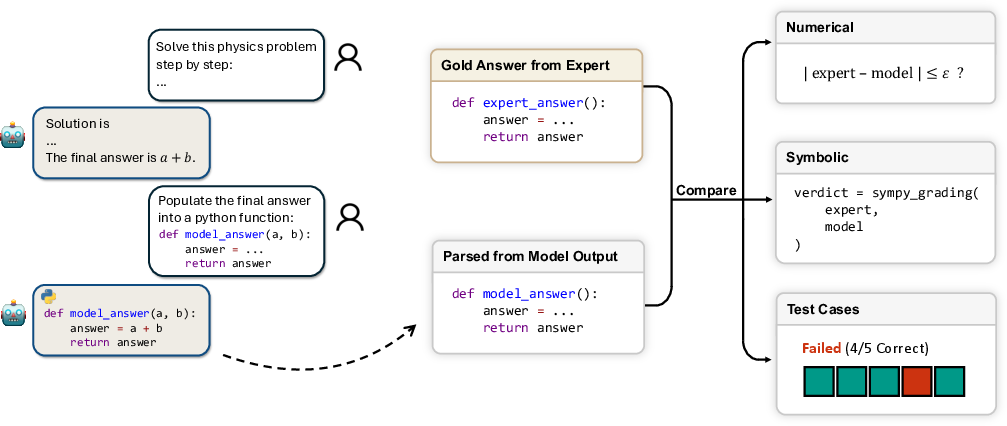
To grade answers consistently and at scale, they built a physics-aware auto-grader:
- First, the AI writes a full solution in normal language.
- Then, in a second step, the AI extracts just the final answer in a clean format (like a number, a symbolic expression, or a short Python function).
- The auto-grader then checks:
- Numbers within sensible error margins (set by physicists).
- Formulas using a math tool (SymPy) to see if the AI’s expression is truly equivalent to the correct one.
- Code by running test cases (like checking a function at several inputs).
This is like a reliable, expert-designed “answer checker” that understands physics math, not just words.
What they did with AI models
They tested several top AI models, including reasoning-focused ones, on both the full challenges and the smaller checkpoints. They also tried giving some models extra tools—like a code interpreter or web search—to see if that helps.
They ran each test multiple times to check reliability and measured:
- Average accuracy (how often the model gets the right answer).
- Consistent solving (how often the model gets it right across repeated tries).
What they found
Short version: today’s best AI models struggle with realistic physics research tasks.
- On full challenges:
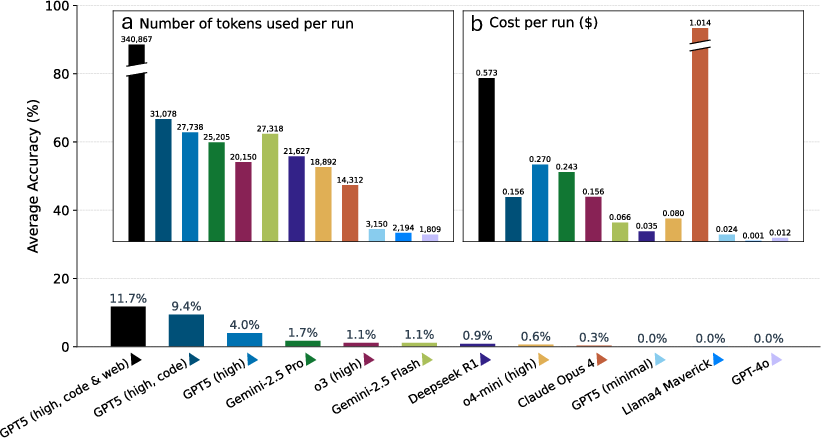
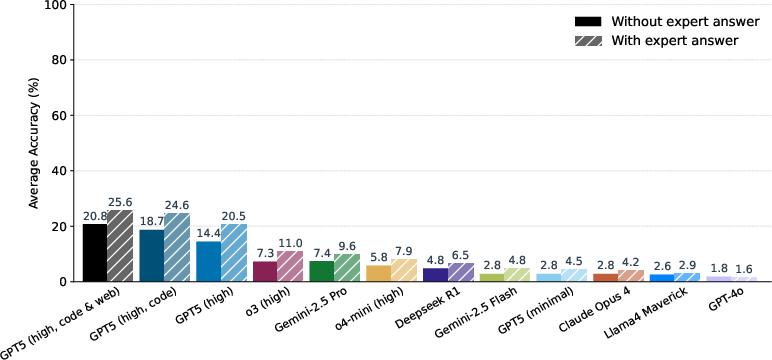
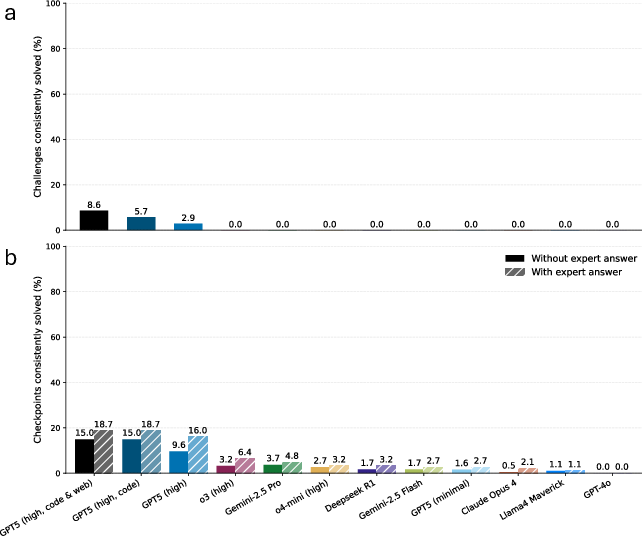
- The best base model only got about 4% correct (about 4 out of 100).
- With tools like coding and web search, the best score rose to about 12%—better, but still low.
- On smaller checkpoints:
- Scores were higher (roughly 15–25% in the best settings), showing AI can sometimes help with parts of a project even if it can’t do the whole thing.
- Reliability was also a problem:
- Even when a model got something right once, it often failed on other tries.
Why this matters: physics research needs careful, step-by-step logic where small mistakes can ruin the final result. These low scores show a big gap between current AI and what real research requires.
Why this matters
- For scientists: CritPt shows where AI can already help (some specific sub-steps) and where it’s not ready (full research projects). This can save time by aiming AI at the right kind of tasks, like checking intermediate math or trying a simpler special case.
- For AI developers: The benchmark gives a clear, realistic target—problems with precise, verifiable answers that demand true reasoning, not memorization. It highlights the need for better tools, stronger checking, and models that can handle physics-heavy logic reliably.
The takeaway and potential impact
CritPt is a tough, realistic, and fair test for AI reasoning in physics. It shows:
- We’re not yet at the “AI junior researcher” stage.
- However, AI can already be useful on smaller, well-defined steps inside bigger problems—especially with coding tools.
- With benchmarks like CritPt guiding development, we can build AI that’s more trustworthy and genuinely helpful for scientific discovery.
In short, CritPt marks the “critical point” between sounding smart and actually doing the hard thinking that real physics research demands.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following items identify what remains missing, uncertain, or left unexplored in the paper and suggest concrete directions for future work.
- Benchmark scale and representativeness
- Quantify whether 71 challenges and 190 checkpoints are sufficient to generalize across subfields; provide item-difficulty calibration (e.g., via item response theory) and sampling rationale.
- Address discipline imbalance (e.g., only 2 fluid dynamics and 2 biophysics challenges) and expand underrepresented areas (plasma physics, AMO beyond toy setups, soft matter, geophysics).
- Provide a formal taxonomy of task types with distribution statistics (derivation, asymptotics, simulation, experimental design/interpretation) to ensure coverage is balanced and intentional.
- Human baselines and calibration
- Report performance of human junior researchers or advanced undergraduates on a stratified subset to calibrate difficulty and set realistic target accuracy for “entry-level research” tasks.
- Include expert time-on-task and error profiles to contextualize what kinds of subtasks LLMs should plausibly solve today.
- Reliability and validity of the auto-grader
- Validate the auto-grading pipeline against manual expert grading on a representative sample; report false-positive/false-negative rates for numerical, symbolic, and code-answer types.
- Stress-test SymPy-based equivalence checks and custom simplifications on adversarial cases; publish failure modes and mitigation strategies.
- Quantify how expert-specified tolerances affect pass/fail decisions; develop standardized tolerances for common physics quantities to reduce reviewer bias.
- Partial credit and trace evaluation
- Introduce principled partial-credit schemes for multi-component answers and derivation steps (beyond strict all-or-nothing for composites) to surface incremental progress.
- Develop mechanisms to verify intermediate reasoning traces (e.g., step checkers, unit consistency, theorem application consistency) without relying on subjective LLM judges.
- Prompting and inference-time sensitivity
- Measure performance sensitivity to prompt variants, formatting templates, temperatures, sampling strategies, and “reasoning tokens” budgets; report confidence intervals and statistical significance.
- Explore whether two-step parsing improves correctness compared to single-pass formats; ablate the parsing prompt and code template design.
- Contamination and leakage auditing
- Conduct a formal contamination audit to evaluate whether unpublished problems can be indirectly recalled (e.g., via contributors’ public talks, datasets, or overlapping domain patterns).
- Test models with web access disabled vs enabled and log retrieved sources to substantiate “search-proof” claims; quantify any leakage via retrieval.
- Tool-use fairness and comparability
- Equip all models with equivalent tool stacks (code execution, web search, CAS) and report tool-induced gains; avoid comparing tool-augmented GPT-5 to base versions of other models.
- Normalize compute budgets across models (e.g., reasoning tokens, execution time limits) to ensure a fair comparison; report per-task compute used.
- Statistical rigor in reporting
- Provide confidence intervals, significance testing, and effect sizes for accuracy and “consistently solved rate”; detail random seed management and run-to-run variability.
- Report per-discipline and per-flavor breakdowns (theory/experiment/computation) to identify where models succeed or fail; include difficulty-stratified analyses.
- Checkpoint–challenge correlation
- Quantify how solving checkpoints predicts full-challenge success (e.g., correlation or causal contribution), enabling targeted tool design for modular assistance.
- Identify which checkpoint types most effectively scaffold challenge completion and which fail to transfer.
- Multimodal and experimental tasks
- Incorporate multimodal inputs (figures, plots, spectra, instrument schematics) and assess multimodal models; current pipeline is text-only.
- Expand experimental reasoning tasks beyond conceptual design to include data interpretation with real or synthetic measurement noise and constraints.
- Physics-specific package support
- Evaluate the impact of allowing specialized scientific libraries (e.g., QuTiP, OpenFermion, Astropy) in the sandbox; quantify gains and security trade-offs.
- Develop safe whitelisting and resource controls for domain-specific tooling to better reflect realistic research workflows.
- Web search reproducibility and governance
- Detail how web search results are cached or normalized to mitigate non-determinism; provide an evaluation server if solutions remain private.
- Specify governance against benchmark “gaming” (e.g., targeted fine-tuning on public questions), including rotating test sets or challenge refresh cycles.
- Sustainability and transparency
- Outline a plan to expand and maintain the benchmark while minimizing future contamination—e.g., periodic injection of new hidden test sets and public dev sets with validated difficulty.
- Provide more public exemplars (with solutions and autograder configs) to enable community verification without exposing the full test set.
- Error taxonomies and failure analysis
- Publish systematic error taxonomies (e.g., unit mistakes, approximation misuse, unphysical regimes, algebraic slips) and model-specific failure patterns to guide targeted improvements.
- Analyze hallucination and overconfidence behaviors (e.g., confident but incorrect physics claims) under varying prompts and tools.
- Approximations and physical reasoning quality
- Evaluate models’ handling of approximations (e.g., asymptotics, perturbation regimes) and unit/dimension checks; introduce dedicated tasks and grading rubrics for physical plausibility.
- Add tests for consistency across multiple derived quantities within the same physical model (e.g., conservation laws, symmetries, limiting cases).
- Impact on researcher productivity
- Measure end-to-end human-in-the-loop workflows: time saved, error reduction, and quality improvements when LLMs assist with checkpoints or code scaffolding.
- Explore collaborative task decomposition strategies that optimally leverage LLM strengths while mitigating failure modes.
- External validity and generalization
- Test transfer from CritPt to unseen, truly independent research tasks contributed by non-overlapping experts; report generalization gaps.
- Vary novelty levels (e.g., parameter ranges, boundary conditions, model variants) to characterize out-of-distribution reasoning robustness.
- Security and sandboxing guarantees
- Provide a formal threat model and auditing for the sandbox (e.g., side-channel risks, denial-of-service via resource exhaustion) and document enforcement efficacy.
- Report how sandbox limits interact with computationally heavy physics tasks (e.g., PDE solvers) and propose scalable accommodations.
- Benchmark scope beyond physics
- Explore generalization of the CritPt methodology to other STEM domains (chemistry, biology, engineering), including domain-specific evaluators and contamination controls.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s benchmark design, evaluation pipeline, and empirical findings. Each item names the sector and notes practical tools or workflows that can be implemented today, along with assumptions or dependencies affecting feasibility.
- Research QA and model evaluation workflow in scientific R&D (Academia, Software, Energy, Materials, Quantum)
- Deploy a CritPt-style evaluation harness to continuously assess LLMs on domain-relevant, machine-verifiable tasks (numerical, symbolic, parametric functions).
- Tools/workflows: two-step generation (free-form reasoning → canonical code block), physics-informed autograder with SymPy/numpy/scipy, sandboxed execution with resource limits, “consistently solved rate” as a reliability metric.
- Assumptions/dependencies: access to code-execution environments; expert-defined tolerances/test cases; careful governance to avoid answer leakage.
- Model procurement and risk assessment (Policy, Enterprise AI Governance)
- Require vendors to report benchmark performance using “consistently solved rate” and leakage-resistant, domain-specific tests before model adoption in science-critical settings.
- Tools/workflows: standardized evaluation checklists; benchmark governance processes; disclosure of reasoning-token use and tool configurations.
- Assumptions/dependencies: institutional willingness to adopt new quality metrics; alignment with regulatory frameworks.
- Physics education with autograding (Academia, Education Technology)
- Integrate CritPt-style checkpoints into graduate/upper-undergraduate coursework and qualifying exams to teach rigorous reasoning and tool use under verifiable outputs.
- Tools/workflows: course assignments that require canonical answer functions/symbolic forms; auto-graded homework and labs with physics-informed tolerances; human-in-the-loop review for edge cases.
- Assumptions/dependencies: faculty time to adapt problems; student access to coding tools; clear policies on LLM use.
- Hiring assessments for technical roles (Industry: Semiconductors, Optics, Quantum, Energy)
- Use modular checkpoints mirroring real research tasks (derivation steps, simplified cases, edge-condition analysis) for candidate evaluation.
- Tools/workflows: evaluation portals with auto-grading of numeric/symbolic outputs; leakage-resistant problem banks; time-bound sandbox execution.
- Assumptions/dependencies: curated task banks maintained by domain experts; IP protection.
- AI assistant “co-pilot” for modular research tasks (Academia, Industry R&D)
- Apply LLMs to isolated checkpoints that involve structured derivations, test-case-based coding, parameter sweeps, unit checks, and sanity validation—areas where models already show early promise.
- Tools/workflows: notebook templates that separate reasoning from answer extraction; automated verification gates; escalation to human review when ambiguity is detected.
- Assumptions/dependencies: clear decomposition of projects into verifiable substeps; sufficient compute for code+web tooling; careful prompt design.
- Continuous Integration (CI) for scientific modeling tools (Software, HPC, Research Platforms)
- Integrate the autograder into CI pipelines to validate LLM-generated analysis code, derived formulas, and numerical routines before merging or releasing.
- Tools/workflows: unit/regression tests derived from expert-provided cases; symbolic equivalence checks; numeric tolerance frameworks; safe execution sandboxes.
- Assumptions/dependencies: well-scoped test suites; resource limits; trusted dependency pinning for SymPy/scipy.
- Benchmark curation and governance (Policy, Community Standards)
- Adopt the paper’s governance model for benchmark integrity (new, unpublished tasks; private gold answers; contamination control), plus audit logs for model responses and evaluation scripts.
- Tools/workflows: access-controlled gold answers; periodic refresh of tasks; documentation of potential leak vectors.
- Assumptions/dependencies: sustained expert participation; funding for curation; community adherence to disclosure norms.
- Science communication and literacy (Daily Life, Public Outreach)
- Use the paper’s findings to set realistic expectations of LLM capabilities (strong on structured subtasks, weak on end-to-end research), improving user habits such as verification and decomposition.
- Tools/workflows: public demos showing two-step generation and auto-grading; tutorials on constructing machine-verifiable queries.
- Assumptions/dependencies: accessible educational materials; simple starter tasks.
- Responsible lab workflows (Policy, Academia, Industry Labs)
- Enforce pre-submission checks where any LLM-derived result must pass machine-verifiable tests or symbolic equivalence before inclusion in lab notes or manuscripts.
- Tools/workflows: verification gates; provenance records linking prompts, reasoning traces, and graded outputs; opt-in human review for exceptions.
- Assumptions/dependencies: clear lab policies; storage of artifacts; privacy for intermediate data.
- Model reporting and documentation (Model Developers, Compliance)
- Include CritPt-style metrics (checkpoint/challenge accuracy and consistently solved rate) in model cards for science-facing models.
- Tools/workflows: standardized reporting templates; reproducible evaluation scripts; reasoning-effort configuration disclosure.
- Assumptions/dependencies: vendor willingness; shared tooling; versioning discipline.
Long-Term Applications
The following applications will require further research, scaling, and development to mature, including advances in reasoning models, tool orchestration, benchmark expansion, and governance.
- AI co-researcher for physics (Academia, Industry R&D across Quantum, Materials, Energy, Astrophysics)
- Develop LLMs that reliably solve end-to-end research-scale challenges, not just checkpoints, with tool-augmented workflows (symbolic math, simulation, literature grounding, experimental design).
- Potential products: “Research IDE” with physics-aware calculators, symbolic engines, data pipelines, and auto-graded milestones; closed-loop discovery systems that use verifiable rewards.
- Assumptions/dependencies: stronger reasoning capabilities; robust retrieval grounded in peer-reviewed sources; comprehensive safety checks; human oversight.
- Cross-domain, leak-resistant benchmarks for STEM and beyond (Education, Policy, Software)
- Extend CritPt design to chemistry, biology (e.g., biophysics, protein modeling), engineering, economics/finance (quant modeling), and robotics, with discipline-specific autograders and tolerances.
- Potential products: “Evaluation-as-a-Service” platforms; dynamic benchmark marketplaces; domain-specific test-case libraries.
- Assumptions/dependencies: sustained expert networks; governance preventing contamination; evolving test design to reduce guessing.
- Certified AI for science-critical decisions (Policy, Standards Bodies, Journals, Funding Agencies)
- Establish certification frameworks requiring passing scores on domain-specific, leakage-resistant benchmarks before AI tools can be used in grant proposals, regulatory filings, or publications.
- Potential workflows: journal submission gates with auto-graded appendices; funding reviews incorporating consistent-solve thresholds; procurement standards for government labs.
- Assumptions/dependencies: consensus on metrics; multi-stakeholder governance; enforcement capacity.
- Human-AI collaborative orchestration (Academia, Industry)
- Build orchestration systems that decompose research goals into checkpoints, allocate subtasks to LLMs or humans based on reliability profiles, and automatically verify outputs.
- Potential products: “Checkpoint Decomposer” agents; reliability-aware task routers; verification-first pipelines; provenance dashboards.
- Assumptions/dependencies: accurate capability modeling; rich task graphs; transparent auditability.
- Safer code execution for AI-generated scientific software (Software, HPC)
- Advance sandboxing with robust resource controls, provenance tracking, and automated detection of pathological behaviors (e.g., infinite loops, unsafe imports), specialized for scientific workloads.
- Potential products: secure scientific code interpreters; policy-compliant containers; reproducibility services linked to graded outputs.
- Assumptions/dependencies: scalable infrastructure; reliable static/dynamic analysis; secure dependency ecosystems.
- Physics-informed training paradigms (Model Development, Academia)
- Train models with verifiable rewards using CritPt-style targets (symbolic equivalence, numeric tolerance, functional tests), aiming to reduce hallucinations and increase reliability on research tasks.
- Potential workflows: RLHF variants with auto-grader signals; curriculum learning via checkpoints → challenges; think-token optimization for STEM reasoning.
- Assumptions/dependencies: curated training sets without contamination; compute budgets; careful reward design to avoid shortcuts.
- Sector applications in energy, materials, and quantum hardware (Industry: Energy, Semiconductors, Quantum Computing)
- Use verified AI pipelines to accelerate materials design, thermodynamic cycle analysis, fault-tolerant quantum protocols, and fluid dynamics modeling—once models consistently pass research-scale tasks.
- Potential products: domain co-pilots with verifiable outputs; automatic derivation assistants; experiment simulators with graded fidelity.
- Assumptions/dependencies: model robustness; validated domain physics; integration with existing tooling and data.
- Regulatory-grade audit trails for scientific AI (Policy, Compliance)
- Standardize logs of prompts, reasoning traces, canonical answers, and grading results to support audits, incident investigations, and accountability in labs and agencies.
- Potential products: compliance dashboards; tamper-evident artifact stores; cross-institution registries for benchmark performance.
- Assumptions/dependencies: privacy-preserving designs; secure storage; norms for sharing.
- Advanced education platforms for research training (Education Technology)
- Build interactive, research-level learning environments where students practice decomposition, tool use, and verification on evolving, leak-resistant tasks, with adaptive feedback.
- Potential products: graduate-level problem banks; research practicums with automated checkpoints; performance analytics using consistency metrics.
- Assumptions/dependencies: platform funding; content refresh cycles; institutional adoption.
- Multi-agent scientific systems with verifiable division of labor (Software, Robotics in labs)
- Orchestrate specialized agents (symbolic math, simulation, literature synthesis, experimental planning) under a verification-first umbrella to tackle complex projects.
- Potential products: agent frameworks with physics-aware contracts; graded handoffs; error triage modules.
- Assumptions/dependencies: reliable agent coordination; robust verification at interfaces; clear responsibility boundaries.
- Public trust and transparency in AI-for-science (Daily Life, Science Communication)
- Improve public understanding by publishing model performance on stringent, leak-resistant research benchmarks—demonstrating progress and limits transparently.
- Potential workflows: open dashboards; periodic “state of reasoning” reports; citizen science modules with verifiable tasks.
- Assumptions/dependencies: accessible explanations; sustained community engagement; guardrails against misinterpretation.
- Cross-institution collaboration networks for benchmark sustainability (Policy, Community)
- Create consortia to maintain, refresh, and govern domain-specific benchmarks, ensuring continued relevance and immunity to contamination.
- Potential products: shared governance protocols; contribution pipelines; funding programs for expert-led curation.
- Assumptions/dependencies: long-term funding; academic–industry cooperation; clear IP/licensing terms.
Glossary
- [[4,2,2]] code: A quantum error detection/correction code with parameters [n,k,d] indicating n physical qubits, k logical qubits, and distance d. "a single [[4,2,2]] quantum error detection code"
- Ancilla qubit: An extra helper qubit used to detect or diagnose errors without directly encoding logical information. "we introduce an ancilla qubit, qubit 4, and use the following state preparation circuit:"
- Asymptotics: The analysis of function behavior in limiting regimes (e.g., large argument), often used to approximate special functions. "delicate asymptotics of special functions (math tricks)."
- Automated grading pipeline: An evaluation system that automatically parses and scores model outputs against gold answers. "automated grading pipeline heavily customized for advanced physics-specific output formats."
- Chain-of-Thought prompting: A prompting technique that elicits explicit step-by-step reasoning before the final answer. "Chain-of-Thought prompting"
- CNOT (Controlled-NOT gate): A two-qubit gate that flips the target qubit conditional on the control qubit being 1. "CNOT_{ij} has control qubit i and target qubit j."
- Consistently solved rate: A reliability metric indicating the fraction of tasks solved across multiple runs. "consistently solved rate"
- Contamination (data contamination): Leakage of benchmark content into training data that can inflate apparent model performance. "susceptible to contamination"
- Depolarizing error channel: A noise model where a quantum state is randomly replaced by a uniformly chosen Pauli error with some probability. "two qubit depolarizing error channel following it that produces one of the 15 non-identity two-qubit Paulis with equal probability p/15"
- Fault-tolerant: Able to operate correctly despite the presence of certain faults or errors, typically via detection and mitigation mechanisms. "makes the circuit fault-tolerant."
- GHZ state: A maximally entangled multi-qubit state (Greenberger–Horne–Zeilinger); here, an entangled two-logical-qubit state. "logical two-qubit GHZ state "
- Guess-resistant design: Constructing tasks and answers to prevent models from succeeding via trivial guessing. "guess-resistant final answers"
- Hadamard gate: A single-qubit gate that creates and interferes superpositions. " is a single-qubit Hadamard gate."
- Inference-time computation: Additional computation performed during generation (inference), not during training, to improve reasoning quality. "scaling inference-time computation"
- LLM judges: Using LLMs themselves as evaluators of answers or solutions. "LLM judges, which can be unreliable"
- Logical fidelity: The overlap or accuracy of the prepared logical state relative to the intended logical target state. "What is the logical state fidelity of the final 2-qubit logical state"
- Logical operator: An operator that acts on the encoded logical qubits within a code’s subspace. "The logical and operators on the two qubits are , , , ,"
- Logical qubit: A qubit encoded across multiple physical qubits to protect against errors. "The two logical qubits are labelled A and B."
- Pauli matrices: The fundamental single-qubit operators X, Y, Z used throughout quantum information and error modeling. "where and are Pauli matrices."
- Parametric solutions: Solutions expressed as functions of parameters, evaluated via test cases rather than exact symbolic forms. "for parametric solutions"
- PhySH classification: The Physics Subject Headings taxonomy used to categorize topics in physics. "Physics Subject Heading (PhySH) classification scheme"
- Physical infidelity: The error probability at the hardware/gate level used to quantify physical noise. "as a function of the physical infidelity ."
- Post-selection: Conditioning on particular measurement outcomes (e.g., discarding runs with detected errors) to improve final states. "assuming the state is post-selected on all detectable errors in the code"
- Quantum error correction: Encoding quantum information into larger systems to detect and correct errors. "In quantum error correction, you encode quantum states into logical states made of many qubits"
- Quantum error detection: Encoding that allows detecting but not correcting the presence of errors. "In quantum error detection, you do the same but can only detect the presence of errors and not correct them."
- Reinforcement learning from verifiable rewards: Training with rewards derived from automatically checkable solutions or proofs. "reinforcement learning from verifiable rewards"
- Sand-boxed environment: An isolated execution environment with strict resource limits for safe code evaluation. "each answer is executed in a sand-boxed environment with enforced resource limits"
- Search-proof answers: Answers constructed to be irretrievable via web search, ensuring genuine reasoning. "search-proof answers"
- Stabilizers: Operators that define and preserve the code space in stabilizer quantum codes. "The stabilizers are and ,"
- SymPy: A Python library for symbolic mathematics used to check algebraic equivalence in grading. "SymPy-compatible symbolic expressions"
- Think tokens: Special tokens used internally by some reasoning models to perform intermediate deliberation. "encapsulated think tokens"
- Topological numbers: Universal, discrete invariants characterizing phases or properties insensitive to microscopic details. "universal quantities such as topological numbers"
- Two-step generation strategy: A protocol that separates free-form reasoning from structured answer extraction. "two-step generation strategy"
- Wall-clock timeout: A limit on real elapsed time for code execution during evaluation. "30-second wall-clock timeout"
Collections
Sign up for free to add this paper to one or more collections.

