- The paper demonstrates that LLM-generated proofs rely on shallow heuristics, with fully valid logical reasoning occurring in less than 5% of cases.
- The analysis identifies common fallacies, including Inventing Wrong Facts and Proposal Without Verification, in over 90% of the evaluated solutions.
- The study emphasizes the need for improved evaluation frameworks that prioritize step-by-step logical coherence over mere final-answer correctness.
Assessing LLM Mathematical Reasoning Beyond Final Answer Accuracy
Introduction
"Brains vs. Bytes: Evaluating LLM Proficiency in Olympiad Mathematics" (2504.01995) addresses the persistent gap between LLM capabilities and human-level proficiency in mathematical reasoning, specifically in the context of International Mathematical Olympiad (IMO) shortlist problems. The work critically examines existing evaluation paradigms that emphasize final answer accuracy, highlighting their inadequacy in establishing logical rigor, and systematically analyzes the fallacious reasoning patterns present in current frontier LLMs. Through comprehensive qualitative and quantitative annotation of LLM-generated proofs, the authors demonstrate that models frequently arrive at correct answers using shallow heuristics rather than authentic deductive reasoning.
Evaluation Framework and Methodology
The study selects 455 IMO shortlist problems spanning algebra, geometry, combinatorics, and number theory. A panel of expert annotators assessed the correctness and rigor of solutions produced by leading LLMs: DeepSeek R1, Gemini 2.0, OpenAI o1, o1-mini, and o3-mini. Solutions were exhaustively categorized as correct, partially correct, or incorrect, with incorrect solutions further annotated according to a taxonomy of fallacies, including Proof by Example, Proposal Without Verification, Inventing Wrong Facts, Begging the Question, Solution by Trial-and-Error, and Calculation Mistakes. The labeling protocol was rigorously reviewed to ensure consistency across annotators.
The authors extended their analysis to automatic solution verification, assessing LLMs’ ability to distinguish genuine proofs from fallacious arguments. This entailed two tasks: rating individual solutions and selecting the correct one from a pair (one human-generated, one LLM-generated).
Empirical Results and Failure Modes
Quantitative analysis reveals that all evaluated LLMs perform substantially below acceptable thresholds for rigorous mathematical reasoning. Less than 5% of their solutions are entirely correct, while over 90% are labeled incorrect, regardless of the model or subject area.
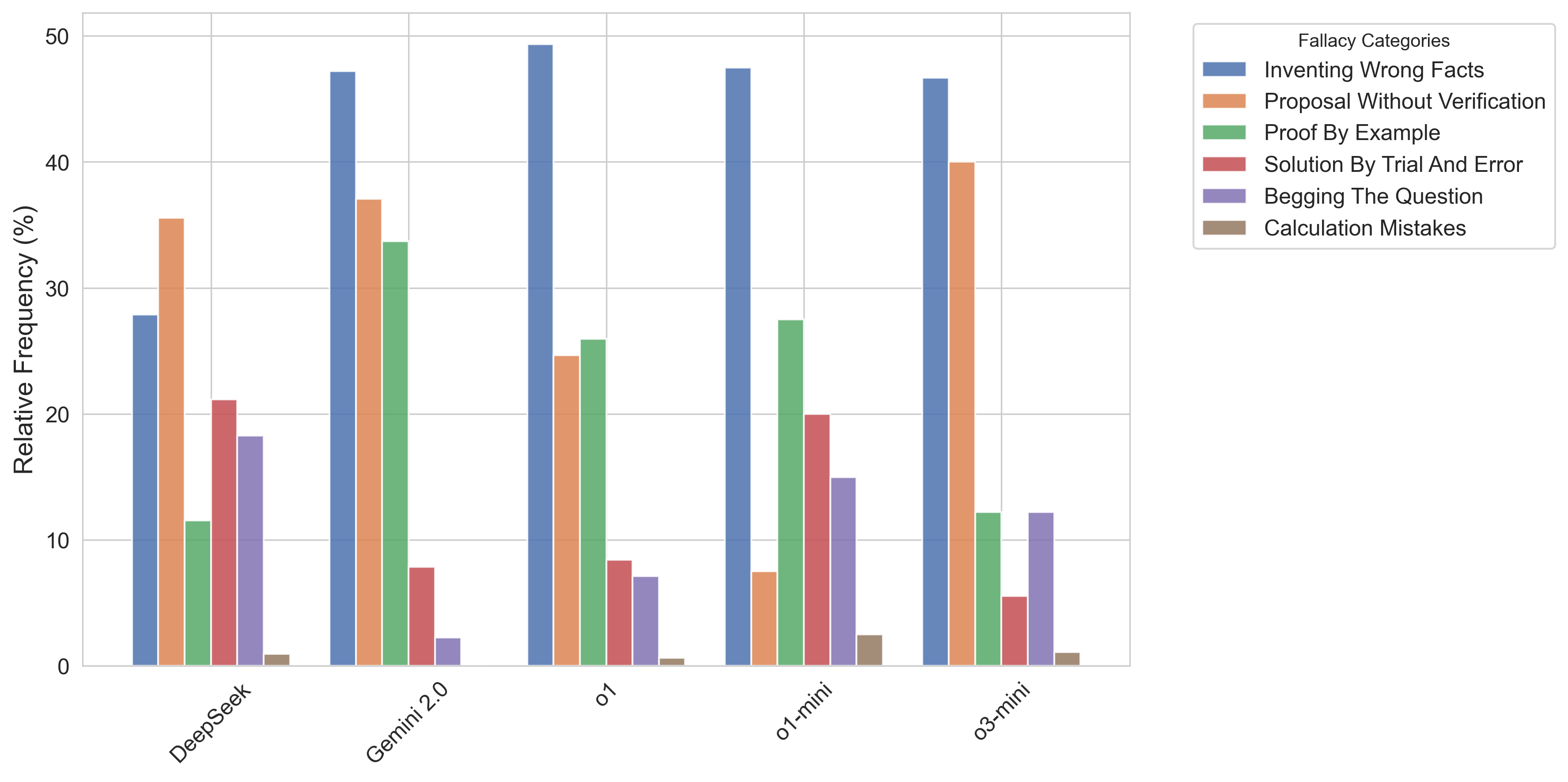
Figure 1: Relative frequencies of each fallacy among the LLM-generated solutions for each model.
The most prevalent fallacies are Inventing Wrong Facts and Proposal Without Verification. Inventing Wrong Facts typically manifests via fabricated theorems or misapplied results—an artifact likely driven by RLHF and reward models primarily targeting final-answer correctness. Proposal Without Verification arises from the models’ inability to substantiate strategic proposals with explicit logical arguments, resulting in vague or unsupported claims.
The analysis reveals topic-dependent variation in fallacy distribution: Proof by Example and Solution by Trial and Error dominate for algebra, number theory, and combinatorics, especially on problems with explicit final answers, while geometry solutions disproportionately involve Inventing Wrong Facts and Begging the Question.
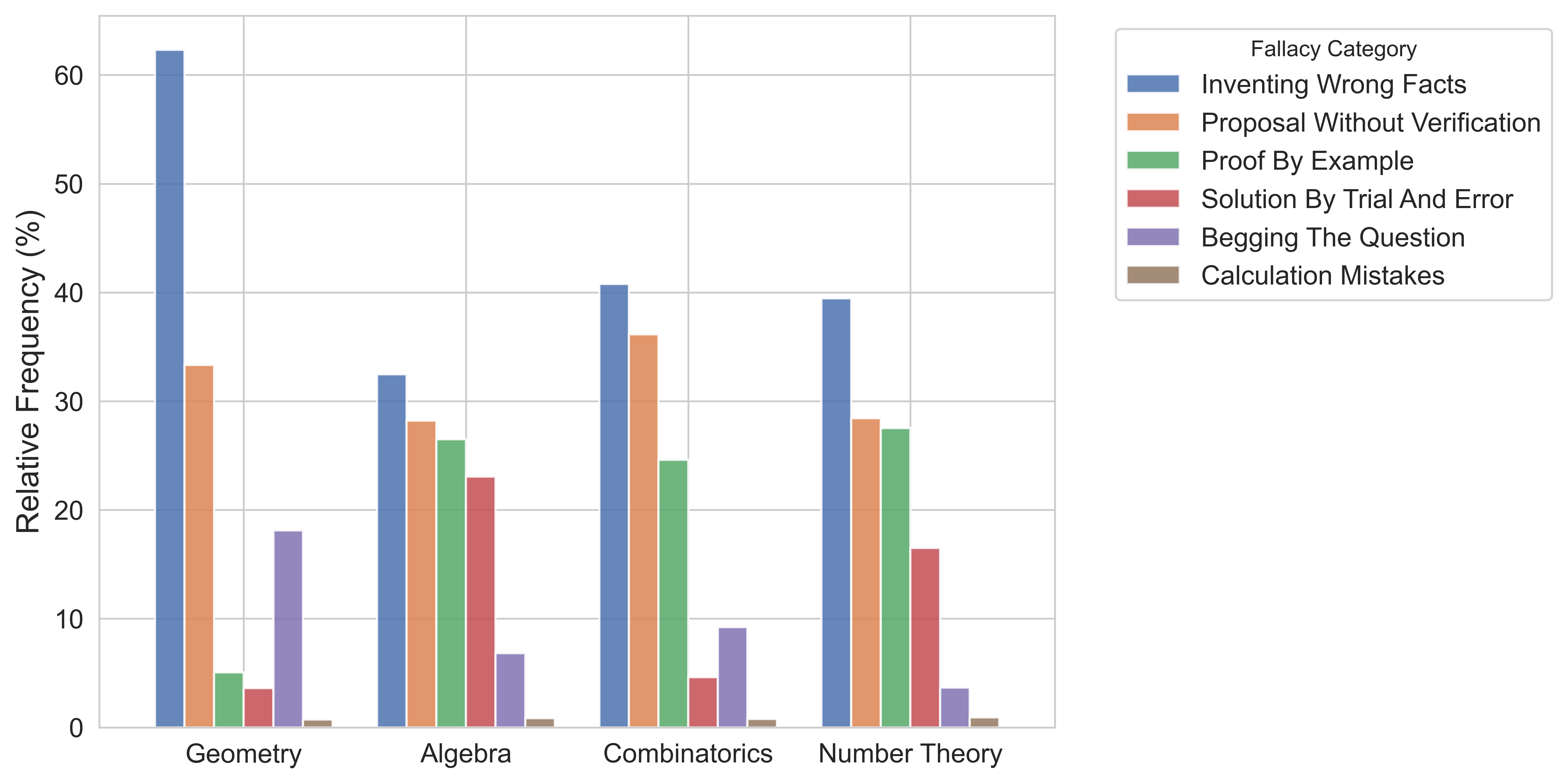
Figure 2: Relative frequencies of each fallacy in LLM-generated solutions among different topics.
The disconnect between final answer correctness and solution quality is decisive. Conditional on the LLM producing a correct final answer, the probability that the solution is actually logically valid remains below 15% for all tested models. This strongly suggests that correct results typically arise from pattern recognition, superficial case analysis, or dataset artifacts, rather than genuine mathematical reasoning.
Automated Reasoning Verification: Generator-Verifier Limits
The paper demonstrates that contemporary generator-verifier paradigms—whereby an LLM or reward model evaluates candidate solutions—are fundamentally limited at these problem complexities. When prompted to label solutions as correct or wrong, models could not distinguish human-authored from fallacious LLM-generated proofs with reliability exceeding chance. Similarly, when presented with paired solutions, the models’ accuracy hovered around random guess (46%-57%, close to the 50% baseline). These results preclude the use of current frontier LLMs as reliable automated judges for high-level mathematical argumentation.
Implications and Future Directions
The findings emphasize that current evaluation benchmarks, which focus on answer accuracy, systematically overstate LLM proficiency in authentic mathematical reasoning. For practical deployment in mathematical discovery or education, rigorous proof validation is non-negotiable; mere answer accuracy is insufficient to ensure validity, trustworthiness, or generalization.
On the theoretical front, the prevalence of shallow heuristics and brittle pattern matching in LLMs underscores the need for architectures or training protocols that internalize reasoning norms, and for benchmarks measuring step-wise logical coherence rather than answer agreement alone. Progress may require integration with formal proof systems, explicit theorem-proving components, or hybrid neuro-symbolic approaches.
Further, the ineffectiveness of LLMs as automatic verifiers highlights the challenges of self-correction and self-improvement frameworks. Current models fail to act as their own critics without significant architectural or training innovations.
Conclusion
This study provides an authoritative critique of prevailing evaluation strategies for mathematical reasoning in LLMs. The results show that frontier models, despite high scores on existing benchmarks, generally lack the capacity for producing or verifying logically rigorous Olympiad-level proofs. The benchmark and annotated error dataset established by this work will be essential for future research targeting genuinely robust mathematical reasoning and for more granular, step-level diagnostic evaluation protocols. The field must prioritize evaluation frameworks and model designs that optimize for logical coherence and process-level validity in mathematical reasoning, beyond final answer correctness.