- The paper proposes a novel nonlinear Langevin diffusion combined with extreme value transformations to better model rare conditional events.
- The paper validates the approach on synthetic and financial data, demonstrating superior tail calibration and reduced sample complexity.
- The paper’s methodology leverages data-driven normalization and modified score matching to achieve improved generative modeling in low-probability regimes.
Improved Representations for Rare Conditional Generative Modeling via Nonlinear Diffusions
Introduction
This paper addresses the limitations of standard score-based diffusion models in conditional generative modeling, particularly in the context of rare events where the conditioning variable X takes values in the tail of its distribution and P(X=x) is small. Conventional linear diffusions, typically with Gaussian equilibrium, exhibit high sample complexity and poor generalization in these low-probability regions due to the scarcity of training data. The authors propose a methodology that leverages conditional extreme value theory (CEVT) and nonlinear Langevin diffusions, combined with data-driven transformations, to construct representations and forward processes that are more amenable to learning in the tails. The approach is validated on synthetic and real-world financial datasets, demonstrating improved modeling of conditional distributions under extreme conditions.
Theoretical Framework
Conditional Diffusion and Sample Complexity
Score-based diffusion models rely on learning a sequence of conditional score functions {∇logpμt(⋅∣x)}t=0T to sample from P(Y∣X=x). In rare regions, the lack of sufficient samples impedes accurate estimation of these scores, resulting in high KL divergence between the true and learned conditional distributions. The sample complexity is governed by the smoothness and complexity of the denoising maps, which are exacerbated in the tails under standard linear (Ornstein-Uhlenbeck) dynamics.
Conditional Extreme Value Theory (CEVT)
CEVT provides a principled framework for modeling the asymptotic behavior of P(Y∣X=x) as x→∞. Under mild assumptions, the conditional distribution can be represented as
Y=a(X)+b(X)⋅Z,Z∼G,
where G is independent of X in the tail. The normalizing functions a(x) and b(x) often admit simple parametric forms, facilitating estimation even with limited tail data.
Methodology
The first step is to transform the data (X,Y) to (X⋆,Z) such that for large X⋆, P(Z∣X⋆=x)≈G is independent of x and typically log-concave. This involves:
- Marginal transformation to standard Laplace for X⋆ and Y⋆.
- Normalization using estimated a(x) and b(x) from tail samples to obtain Z.
This transformation regularizes the conditional distribution in the tail, making the subsequent score estimation tractable.
Figure 1: Visualization of forward diffusion before and after transformation; post-transformation, the conditional density at tail events remains nearly stationary, simplifying score estimation.
Nonlinear Langevin Diffusion
The forward process is implemented as a Langevin diffusion targeting e−g, where g is chosen to match the empirical tail distribution G (e.g., Laplace, Gumbel). The drift term ∇g is estimated from tail data. Discretization is performed via Euler-Maruyama, with smoothing of g to ensure efficient convergence and bounded curvature.
Score estimation targets (∇g+∇logpμt(⋅∣x)) using a time-dependent neural network sθ(z;x,t), trained with a modified score-matching loss:
L(θ)=Et{λ(t)EX,Z0EZt∣Z0[∥sθ(z;x,t)−(∇logpμ0t(⋅∣Z0,X)(Zt)+∇g(Zt))∥22]}.
Sampling proceeds via time-reversal of the learned diffusion, followed by inversion of the normalization to recover Y from Z:
Y⋆=a(X⋆)+b(X⋆)⋅Z,Y=F^Y−1(FLap(Y⋆)).
Empirical Evaluation
Synthetic Data
Two synthetic scenarios are considered:
- Mean-Shifted Laplace: X∼Pareto(1), Y∼X10+Laplace(0,1). The Laplace equilibrium is directly targeted without transformation.
- Correlated Gaussian: (X,Y) jointly Gaussian, transformed via CEVT to (X⋆,Z), with G approximated as Gumbel.
In both cases, the proposed method with appropriate base distribution (Laplace or Gumbel) captures the tail behavior of P(Y∣X=x) significantly better than standard Gaussian-based diffusion.
Figure 2: Comparison of standard Gaussian diffusion and Laplace/Gumbel-based nonlinear diffusion on synthetic data; nonlinear diffusion accurately models heavy tails.
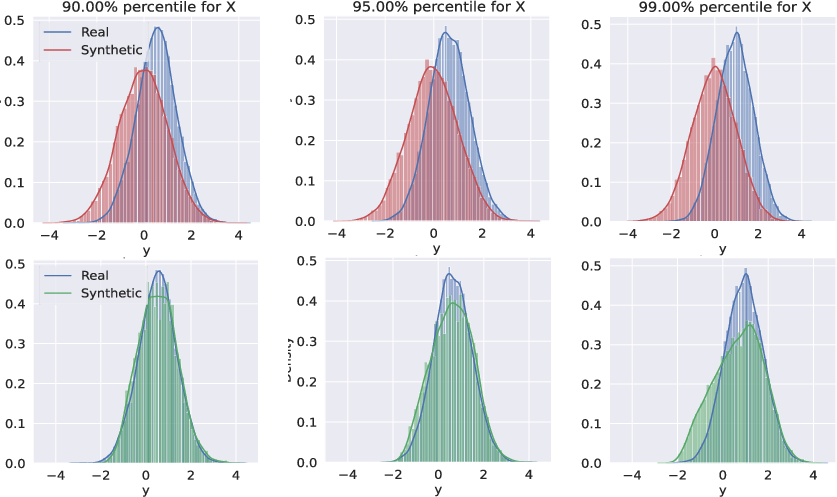
Figure 3: Top row: Standard method with linear diffusion fails to capture heavy Laplace tails; bottom row: new method succeeds.
Financial Data: Stock Returns Conditioned on VIX
The methodology is applied to modeling stock returns conditioned on the VIX index during periods of market stress (GFC and COVID). Training is performed on pre-crisis data, and testing on crisis periods with elevated VIX.
- Unconditional Evaluation: QQ plots show that Laplace-based diffusion provides superior calibration in the tails compared to Gaussian, especially in the test set where extreme VIX levels are prevalent.
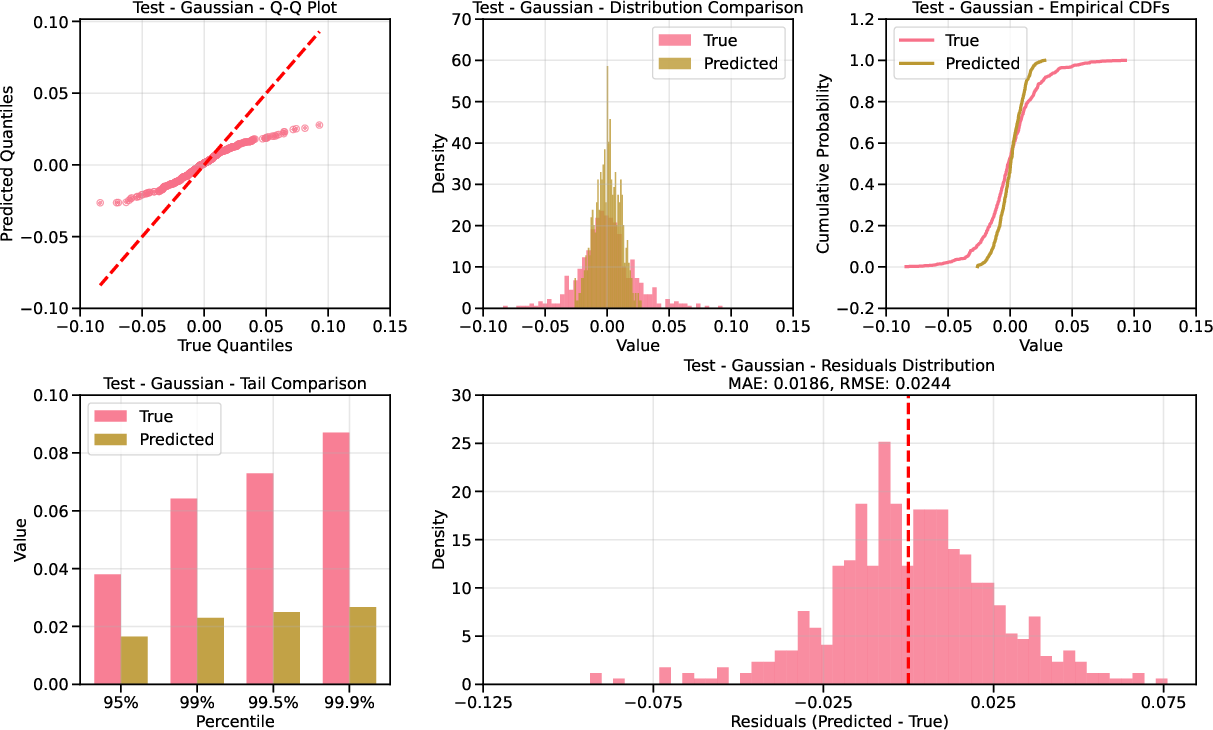
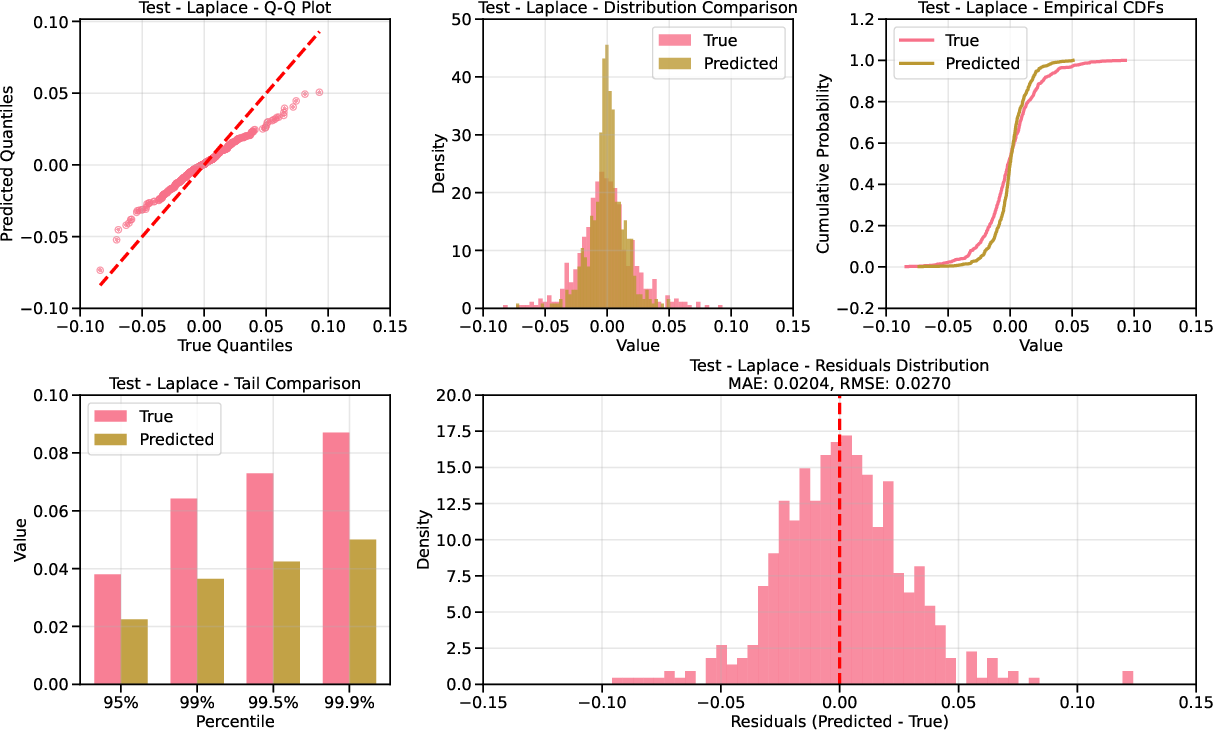
Figure 4: QQ plot for AAPL returns under Gaussian base; underdispersion in the tails is evident.
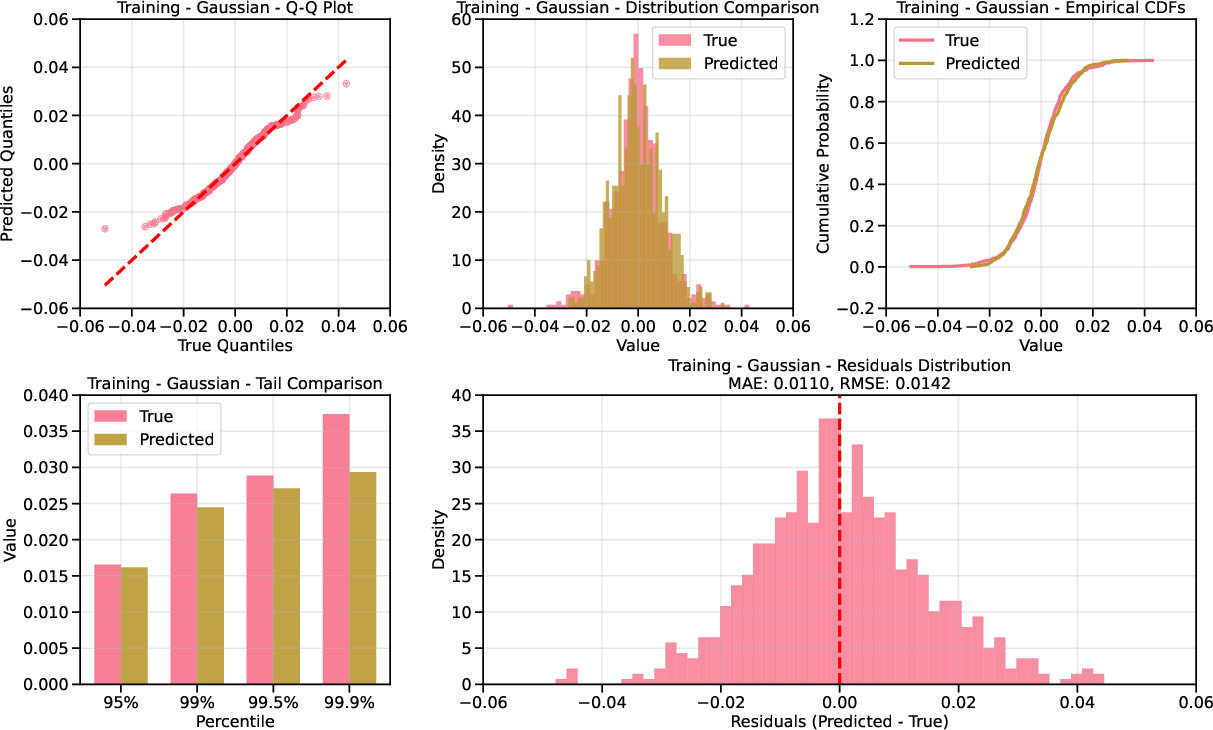
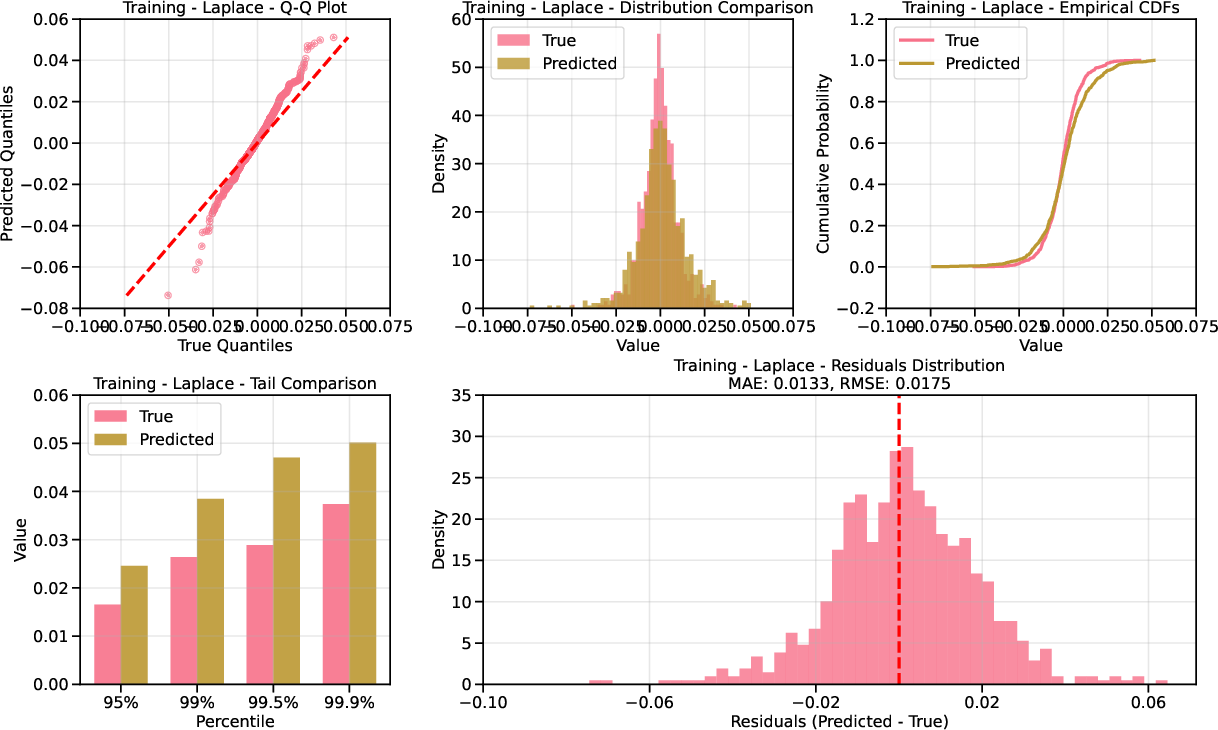
Figure 5: QQ plot for AAPL returns under Laplace base; improved tail calibration.
- Conditional Evaluation: Scatter plots of returns vs. VIX demonstrate that Laplace-based diffusion better captures the conditional distribution at high VIX levels, where standard Gaussian diffusion underestimates tail risk.
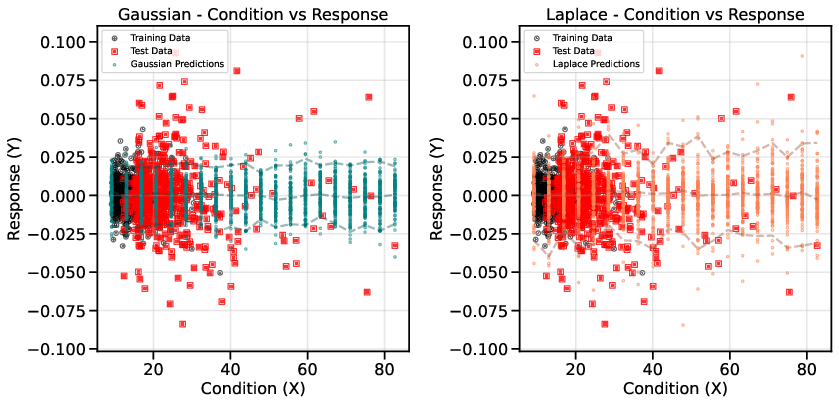
Figure 6: Conditional performance for MSFT; Laplace base captures tail behavior as VIX increases.
Implementation Considerations
- Score Network Architecture: Standard feedforward neural networks are used for score estimation; the complexity of the denoising maps is reduced in the transformed space, lowering sample requirements.
- Forward Process Discretization: Smoothing of g is critical for efficient convergence; Taylor-accelerated sampling can be used for nonlinear drift terms.
- Inverse Transformation Robustness: The parametric forms of a(x) and b(x) ensure stable inversion even with limited tail data.
- Computational Efficiency: The methodology is compatible with existing score-based diffusion frameworks, with additional preprocessing and drift estimation steps.
Implications and Future Directions
The proposed approach demonstrates that data-driven transformations and nonlinear diffusions, informed by CEVT, can substantially improve conditional generative modeling in rare event regimes. This has direct implications for risk modeling, anomaly detection, and any domain where accurate modeling of tail events is critical. The framework is agnostic to the specific form of the tail distribution, allowing adaptation to other domains with different extreme value behavior.
Future work should address:
- Automated, data-driven learning of optimal transformations beyond CEVT.
- Extension to high-dimensional conditioning variables and multivariate responses.
- Comprehensive benchmarking against alternative generative models (e.g., GANs, VAEs) in rare event settings.
- Theoretical analysis of sample complexity and generalization in the transformed space.
Conclusion
This paper presents a principled methodology for rare conditional generative modeling by combining data transformations based on extreme value theory with nonlinear score-based diffusion models. Empirical results on synthetic and financial datasets confirm that the approach yields superior modeling of conditional distributions in the tails, with reduced sample complexity and improved calibration. The framework is broadly applicable and opens avenues for further research in robust generative modeling under data scarcity and distributional shift.