- The paper introduces ARMADA, a scalable multi-robot system that uses FLOAT for autonomous online failure detection and human shared control.
- The system leverages optimal transport, Sinkhorn approximation, and adaptive rewinding to enhance visuomotor imitation learning and policy adaptation.
- Experimental results show over 4x improvement in success rates and more than 2x reduction in human intervention compared to state-of-the-art approaches.
ARMADA: Autonomous Online Failure Detection and Human Shared Control for Scalable Real-world Robot Deployment
Introduction
The paper presents ARMADA, a multi-robot system for scalable real-world deployment and adaptation of visuomotor imitation learning policies. ARMADA integrates an autonomous online failure detection module, FLOAT (FaiLure detection based on OptimAl Transport), and a human-in-the-loop shared control framework. The system enables parallel policy rollouts across multiple robots, requesting human intervention only when necessary, thereby reducing the need for full-time human supervision. The approach addresses the limitations of pretrained policies in out-of-domain scenarios and the inefficiency of human demonstration collection, offering a scalable solution for policy adaptation and deployment.
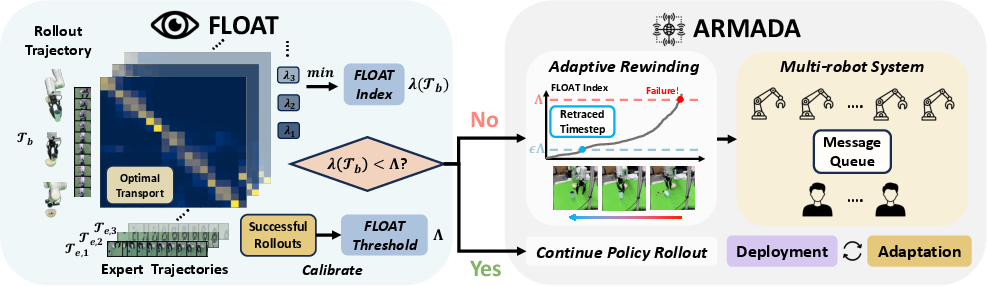
Figure 1: Overview of ARMADA, illustrating FLOAT-based failure detection, adaptive rewinding, and multi-robot shared control for scalable deployment.
FLOAT: Optimal Transport-based Failure Detection
FLOAT is a plug-in-and-play online failure detection method for visuomotor imitation learning. It leverages policy embeddings from a pretrained observation encoder and computes the minimum Optimal Transport (OT) cost between the current rollout trajectory and all expert demonstrations. The FLOAT index, defined as the minimum OT cost, serves as a real-time failure metric. A universal FLOAT threshold is calibrated on successful rollouts; exceeding this threshold triggers a failure signal.
Key technical details:
- Policy Embedding Extraction: For each expert demonstration and current rollout, embeddings are computed via a pretrained visual encoder (DINOv2 ViT-B/14 with a linear head for dimensionality reduction).
- OT Computation: Cosine similarity is used as the cost function for OT matching. Sinkhorn approximation is adopted for computational efficiency.
- Threshold Adaptation: The FLOAT threshold is dynamically updated based on online rollout statistics, with a time-varying hyperparameter δ controlling sensitivity.
FLOAT operates asynchronously with policy rollout to avoid latency, and its design is robust to varied trajectory lengths via padding.
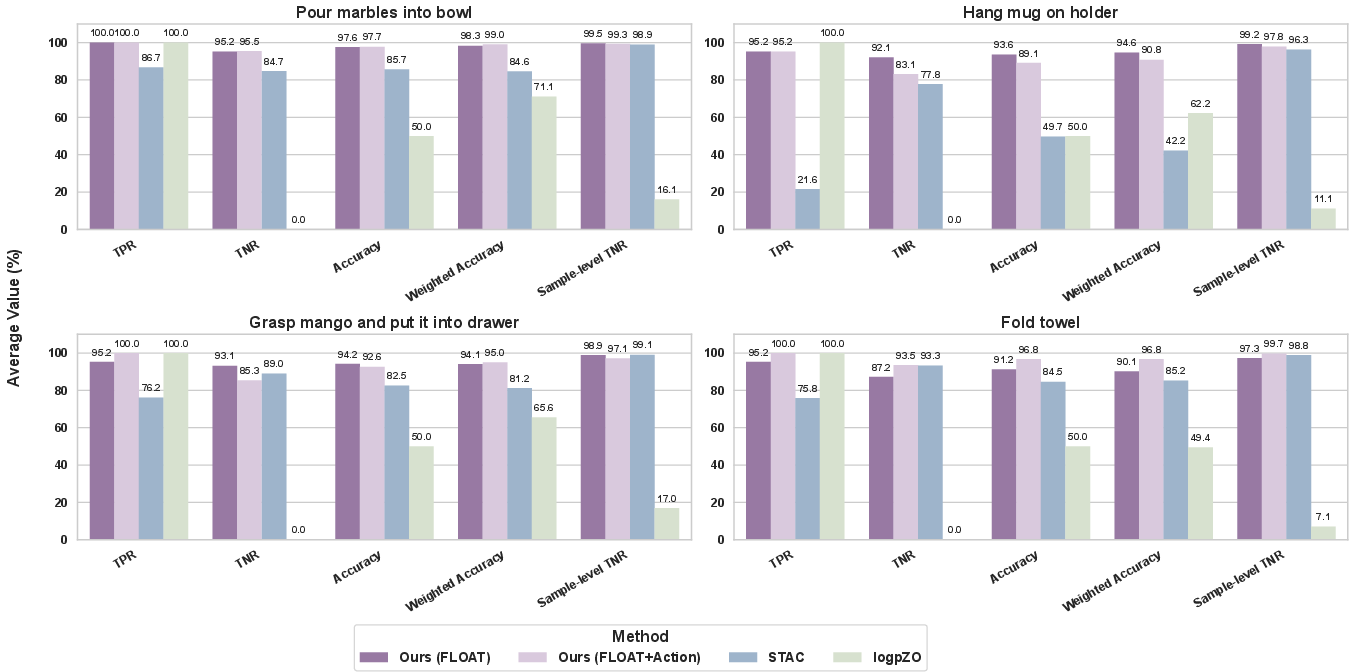
Figure 2: FLOAT achieves nearly 95% accuracy in failure detection across four tasks, outperforming state-of-the-art baselines by over 20%.
ARMADA: Multi-Robot Shared Control and Adaptive Rewinding
ARMADA's architecture enables parallel autonomous rollouts on multiple robots, coordinated via a message queue system that allocates idle human operators for intervention upon failure detection. The adaptive rewinding mechanism allows robots to retrace to a previous timestep with a FLOAT index below a fraction of the failure threshold, facilitating scene reset and high-quality demonstration collection.
Algorithmic highlights:
- Message Queue Coordination: Robot nodes enqueue intervention requests; teleoperation nodes dequeue and assign to available human operators.
- Adaptive Rewinding: Upon failure, the system searches for the latest timestep with a FLOAT index below ϵλ((Tb)1:t0), where ϵ is a fixed hyperparameter (0.2 in experiments).
- Policy Architecture: Diffusion Policy with transformer backbone, DINOv2 visual encoder, and proprioceptive inputs (including 6D rotation representation).
ARMADA is compatible with various policy architectures, human intervention modalities, and robot embodiments.

Figure 3: Real-world task setup for ARMADA evaluation, including Pour marbles, Hang mug, Grasp mango, and Fold towel.
Experimental Results
FLOAT demonstrates robust failure detection, achieving nearly 95% accuracy across four real-world manipulation tasks. It surpasses STAC (statistical temporal action consistency) and logpZO (Conformal Prediction-based) baselines by over 20% in accuracy. FLOAT maintains high true positive and true negative rates, and its performance is comparable to variants integrating action inconsistency metrics, indicating its generality across failure modes.
Policy Adaptation and Success Rate
ARMADA's adaptive rewinding mechanism yields significant improvements in policy success rate over multiple post-training rounds. Compared to Sirius (state-of-the-art human-in-the-loop learning requiring full-time supervision), ARMADA achieves a more than four-fold increase in success rate, particularly in tasks prone to unrecoverable states.
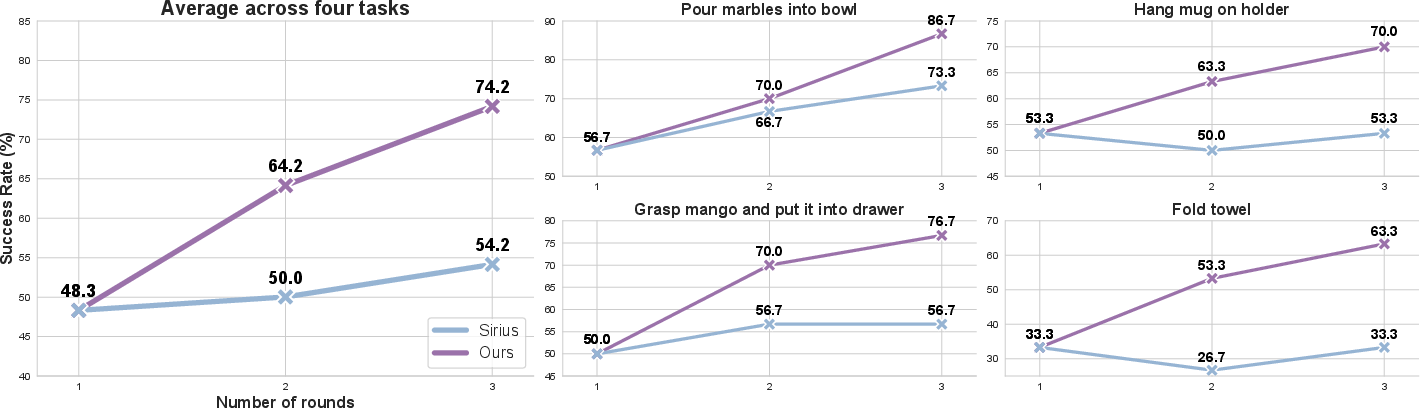
Figure 4: Success rate over three evaluation rounds; ARMADA shows stable progress and >4x improvement over Sirius.
Human Intervention Efficiency
ARMADA reduces human intervention rate by more than two-fold compared to Sirius after two fine-tuning stages. The system's efficiency in leveraging human corrective data enables scalable deployment with minimal human effort, supporting parallel robot operation.
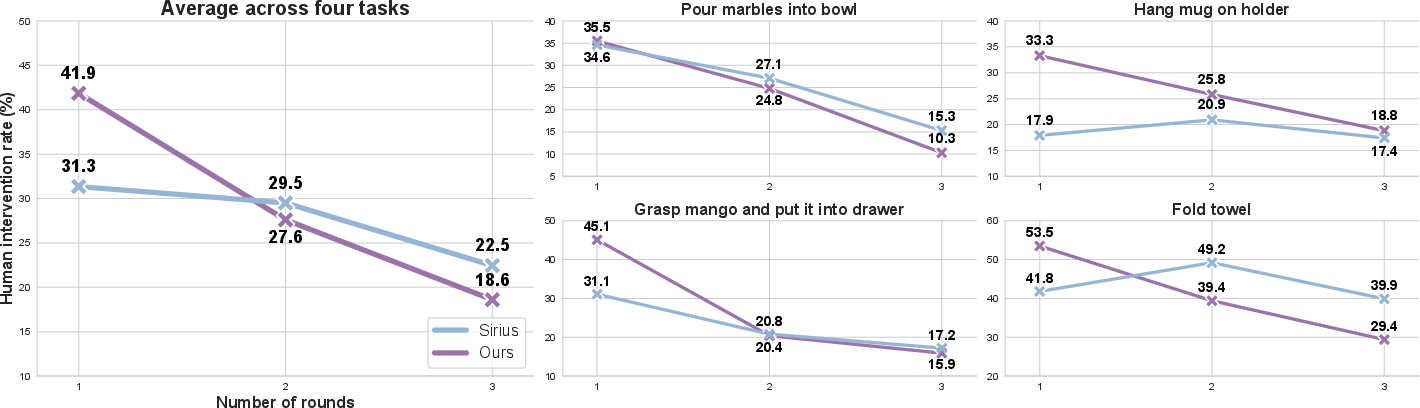
Figure 5: Human intervention rate over three evaluation rounds; ARMADA achieves >2x reduction compared to Sirius.
Scalability and Adaptation to Unseen Scenarios
ARMADA expedites policy adaptation to novel scenarios via parallel deployment on multiple robots and diverse scene configurations. In multi-robot experiments, ARMADA collects high-quality human intervention data from varied domains, resulting in improved generalization and robustness of post-trained policies to out-of-distribution scenarios.

Figure 6: Multi-robot experiments on unseen scenarios; ARMADA enables efficient adaptation and data collection across diverse environments.
Implementation Considerations
- Computational Requirements: OT computation is accelerated via Sinkhorn approximation; DINOv2 encoder and transformer backbone require multi-GPU training (4 NVIDIA A800 GPUs in experiments).
- Data Management: Expert demonstrations are padded to uniform length for OT matching; rollout episodes exceeding maximum length are auto-terminated.
- Deployment Strategy: ARMADA supports asynchronous failure detection and intervention, enabling real-time operation without bottlenecking robot throughput.
- Limitations: FLOAT requires task-specific expert demonstrations and does not generalize to novel tasks or embodiments without reference data. Future work should focus on universal progress estimators for cross-task failure detection.
Conclusion
ARMADA introduces a scalable framework for real-world robot deployment and adaptation, integrating autonomous online failure detection (FLOAT) and human shared control. The system achieves high failure detection accuracy, substantial improvements in policy success rate, and significant reductions in human intervention. ARMADA's architecture supports efficient parallel deployment and rapid adaptation to new scenarios, with practical implications for large-scale robot learning systems. Future research should address generalization of failure detection across tasks and embodiments to further enhance scalability.