- The paper introduces EAT as an efficient early exit signal that leverages entropy stabilization to indicate when reasoning accuracy plateaus.
- It presents an adaptive algorithm using exponential moving average variance tracking to dynamically allocate token budgets for easy and hard questions.
- Empirical results show EAT reduces token usage by 13–21% while maintaining Pass@1 performance across various models and datasets.
Entropy After ⟨/Think⟩ for Reasoning Model Early Exiting
Introduction and Motivation
The paper introduces Entropy After ⟨/Think⟩ (EAT) as a practical, efficient signal for early exiting in LLM reasoning chains. The motivation stems from the observation that contemporary reasoning models, such as DeepSeek-R1 and Qwen3, frequently "overthink"—continuing to generate lengthy chains of thought even after the correct answer has been reached and stabilized. This behavior is quantitatively confirmed by tracking Pass@1 accuracy over multiple rollouts, which often saturates early in the reasoning process, rendering further computation redundant.
The inefficiency of fixed token budgets for all questions is highlighted: easy questions are over-served, while hard ones may be under-served. The need for adaptive test-time computation is clear, and the paper proposes uncertainty-based early exiting, leveraging entropy as a proxy for information gain and answer confidence.
EAT: Definition and Theoretical Basis
EAT is defined as the entropy of the next-token distribution immediately after appending the stop thinking token (</think>) to the reasoning chain. Formally, for a reasoning LLM θ and a chain R=r1,…,rn, EAT is:
EAT=H(f(Q,⟨think⟩,r1,…,rn,⟨/think⟩;θ))
where f(⋅) is the next-token probability distribution and H(⋅) is the entropy. EAT quantifies the information gain from the reasoning process, as the reduction in uncertainty between the initial and final next-token distributions.
Empirically, EAT exhibits a sharp decrease and stabilization at the point where Pass@1 accuracy plateaus, indicating that further reasoning is unlikely to improve the answer. This property is robust across datasets and models.
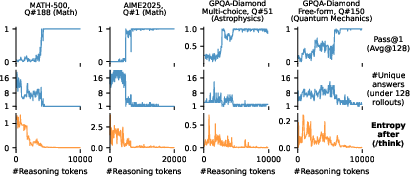
Figure 1: EAT provides an informative signal to prevent overthinking in reasoning models, with Pass@1 saturating early and EAT stabilizing at the same point.
Early Exiting Algorithm
The proposed early exiting algorithm monitors the variance of EAT using an exponential moving average (EMA). The running mean (M^) and variance (V^) are updated at each reasoning step:
Mn=(1−α)Mn−1+αEATn Vn=(1−α)Vn−1+α(EATn−Mn)2
where α is the EMA timescale. Reasoning halts when V^ drops below a threshold δ, or when </think> is generated. This approach is adaptive: easy questions stabilize quickly, consuming fewer tokens, while harder questions receive more computation.
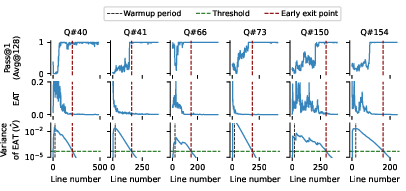
Figure 2: Illustration of early exiting by thresholding the EMA estimated variance of EAT, showing Pass@1 saturation and EAT stabilization.
The algorithm is compatible with black-box models: EAT can be computed using a smaller proxy model that observes only the reasoning text, enabling deployment in commercial settings where logits are inaccessible.
Efficiency and Comparison to Baselines
EAT is computationally efficient, requiring only a single forward pass per reasoning step, with overhead linear in the chain length and negligible compared to rollout-based methods. Rollout-based uncertainty estimation (e.g., unique answer counting over K rollouts) is both stochastic and expensive, with significant token and runtime overhead.

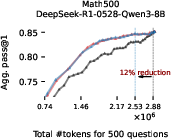
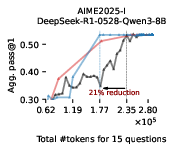
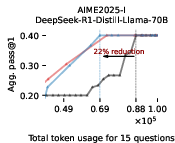
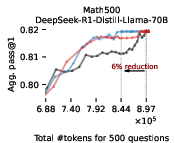
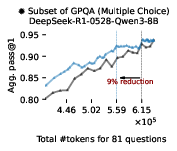
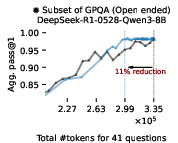
Figure 3: EAT-based early exiting dynamically allocates token budgets and consistently saves tokens without sacrificing accuracy, outperforming token-based early exiting.
Empirical results on Math500, AIME-2025, and GPQA-Diamond demonstrate that EAT-based early exiting reduces token usage by 13–21% without harming accuracy. The method generalizes across model sizes and remains effective when EAT is computed with proxy models, including scenarios where a 1.5B model early-exits a 70B reasoning model.
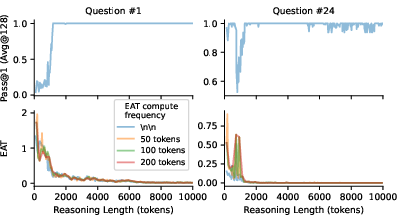
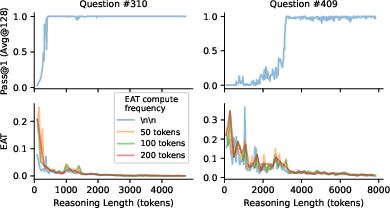
Figure 4: EAT computed under different frequencies shows consistent patterns, with smoother trajectories at higher evaluation intervals.
Ablation and Error Analysis
Ablation studies show that EAT remains effective for EMA timescales α>0.1, and that including a "Final answer:" prefix after </think> can improve the correlation between EAT stabilization and Pass@1 convergence for older models. For unsolvable questions or those with decreasing Pass@1, EAT does not stabilize, and the algorithm uses the full token budget, indicating a limitation in distinguishing between hard and unsolvable instances.
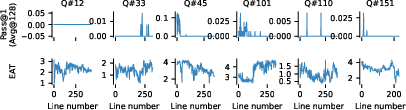
Figure 5: On unsolvable questions, EAT does not stabilize and therefore uses up all tokens under the early exit algorithm.
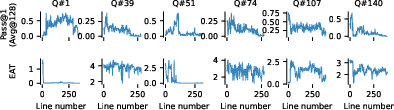
Figure 6: On questions with decreasing Pass@1, EAT either does not stabilize or stabilizes after the optimal exit point.
Practical Implications and Future Directions
The EAT signal provides a lightweight, deterministic, and model-agnostic criterion for early exiting in reasoning LLMs. It enables adaptive compute allocation, reducing inference cost and latency without sacrificing accuracy. The method is robust to model architecture and size, and is deployable in black-box settings.
Potential future directions include:
- Instance-specific threshold adaptation for further efficiency gains.
- Joint optimization of compute budgets across problem distributions.
- Integration with improved post-training algorithms that endogenously halt reasoning.
- Extension to recognize and abandon reasoning on unsolvable instances by monitoring persistent high EAT variance.
Conclusion
EAT offers a principled, efficient approach to early exiting in LLM reasoning chains, addressing the overthinking phenomenon and enabling adaptive inference. Its strong empirical performance, computational efficiency, and compatibility with black-box deployment make it a practical tool for large-scale reasoning systems. The method's theoretical grounding in information gain and uncertainty, combined with its empirical robustness, suggest broad applicability and potential for further refinement in future research.