- The paper demonstrates that latent reward signals in LLM latent thoughts can optimize reasoning accuracy and reliability.
- It introduces a latent classifier using entropy and anisotropy metrics to quantitatively assess the quality of latent representations.
- The method improves computational efficiency across domains and shows potential for scalable applications in various LLM architectures.
Latent Thinking Optimization: Reward Signals in Latent Thoughts
Introduction
The paper "Latent Thinking Optimization: Your Latent Reasoning LLM Secretly Encodes Reward Signals in Its Latent Thoughts" presents a comprehensive study on latent reasoning within LLMs, specifically focusing on the Huginn-3.5B architecture. The authors propose a novel approach to optimizing the latent thinking process by utilizing reward signals encoded within latent thoughts. This study provides insights into how latent thoughts can be systematically analyzed to improve correctness and reliability in reasoning tasks.
Latent Reasoning Architecture
LLMs typically perform reasoning by generating intermediate steps of thought, often expressed in natural language. While effective, this method can be computationally expensive and prone to producing misleading reasoning chains. The Huginn-3.5B model approaches reasoning differently by employing a latent thinking architecture. Here, reasoning steps are encoded as sequences of latent representations, referred to as latent thoughts.
This latent approach offers computational efficiency by avoiding verbose natural language throughout the entire reasoning process. However, the lack of interpretability in latent thoughts raises concerns about the reliability of the model’s reasoning process. Understanding this process is crucial for implementing corrections and improvements.
Analytical Methods
The paper proposes Latent Thinking Optimization (LTO), which leverages a Latent Reward Model (LRM) to optimize latent thinking processes. A central component is the latent classifier, trained to recognize patterns in the latent space that distinguish between correct and incorrect reasoning. The classifier uses various metrics—such as Entropy and Anisotropy—to evaluate the information content and geometric structure of latent representations.


Figure 1: Distribution of representation quality metrics across 32 steps of the latent thoughts on SVAMP.
These metrics provide a quantitative understanding of how latent thoughts evolve during the reasoning process. The classifier’s strong performance across different domains underscores its efficacy in recognizing correctness signals within latent thoughts.
Implementation of Latent Thinking Optimization
The LTO process is structured around probabilistic optimization. It selects latent thinking trajectories based on their likelihood of correctness, as predicted by the LRM. The goal is to sample trajectories that exhibit patterns characteristic of correct reasoning. The probabilistic sampling process is rigorously designed to align with the objective of optimizing latent thinking policies while maintaining computational efficiency.
Applications and Implications
One notable aspect of LTO is its applicability beyond Huginn-3.5B. The authors highlight its potential for improving latent reasoning in general LLMs, demonstrating strong cross-domain generalization. This adaptability is significant for deploying LRM across diverse applications without extensive retraining, offering a scalable solution for test-time computation optimization.
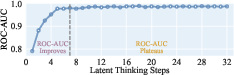
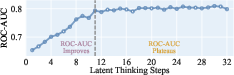
Figure 2: ROC-AUC of the latent classifier on MBPP.
The paper posits LRM as a promising direction for developing generalist reward models in latent spaces, which could revolutionize efficiency and effectiveness in LLM reasoning.
Conclusion
Latent Thinking Optimization represents a compelling approach to enhancing LLM reasoning capabilities through latent space analysis and reward modeling. The ability to interpret latent thoughts and optimize their trajectories marks a significant advance in computational reasoning. As LLMs continue to evolve, the insights and methods introduced in this paper may catalyze further developments in AI efficiency and scalability, potentially reshaping how models approach complex reasoning tasks.