- The paper introduces a framework that transforms security policies from design documents into executable runtime guardrails.
- It employs a dual-step process of parsing and enriching policy documents to generate structured policy trees for input/output classification.
- Experimental results demonstrate enhanced compliance and reduced prompt-injection risks in regulated environments such as HR and SOC.
Policy-as-Prompt: Turning AI Governance Rules into Guardrails for AI Agents
Introduction
The growing deployment of AI agents in regulated environments necessitates robust governance mechanisms to ensure compliance with safety-critical policies. These settings encompass diverse applications, from Human Resources (HR) systems to Security Operations Centers (SOC), where the consequences of unauthorized data access or leakage can be severe. The paper "Policy-as-Prompt: Turning AI Governance Rules into Guardrails for AI Agents" (2509.23994) presents a novel framework for converting unstructured design documents into enforceable runtime controls, addressing the significant gap between policy formulation and practical implementation.
Framework Overview
The proposed framework, "Policy as Prompt," transforms policy documents and technical design artifacts into actionable guardrails through a policy tree generation method. It involves parsing documents for security rules and classifying them into structured policy trees, subsequently compiled into prompt-based classifiers for real-time monitoring. This automated process employs AI to extract security constraints, drafts policies for human review, and compiles them into lightweight, executable prompts that enforce least-privilege access controls.
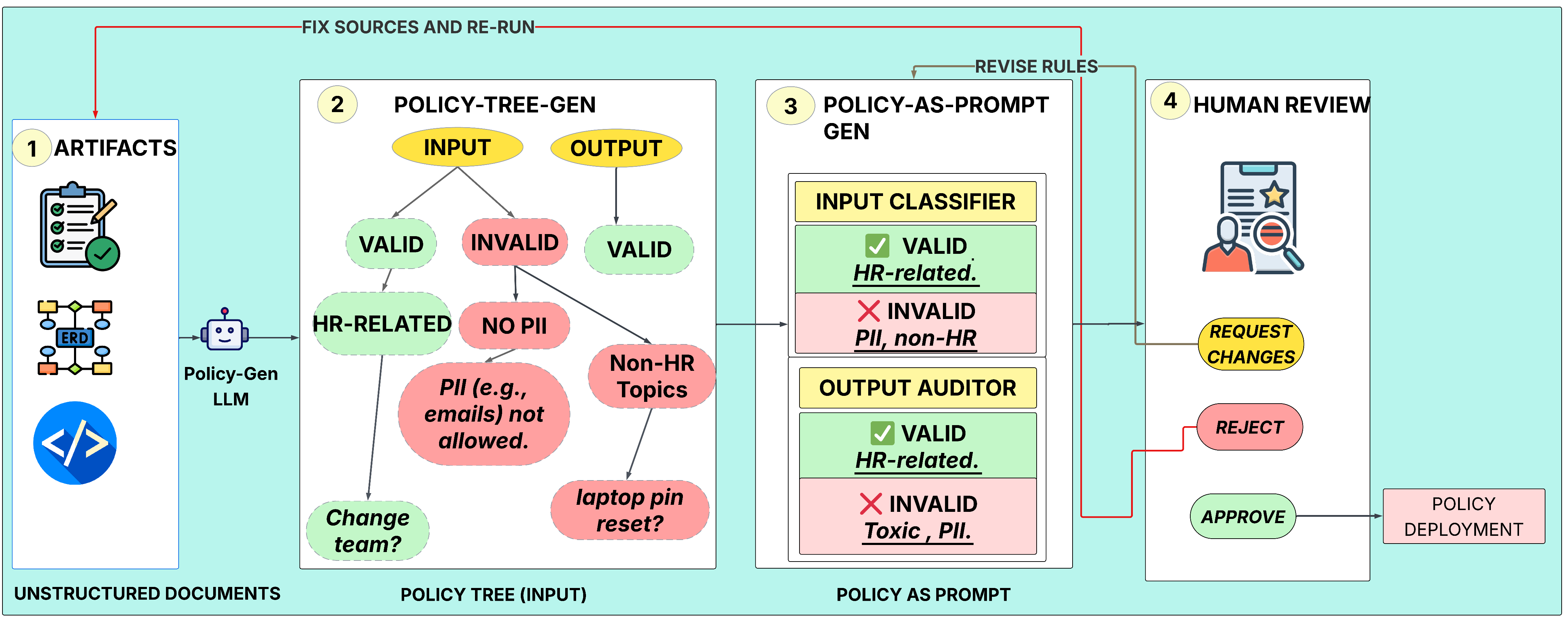
Figure 1: Policy Generation and Enforcement Pipeline for an HR Application
The figure illustrates the comprehensive pipeline for policy generation and enforcement in an HR application, showcasing the flow from document analysis to runtime monitoring.
Policy Tree Generation Process
The process begins by extracting security requirements from development artifacts like Product Requirements Documents (PRDs) and linking them to specific examples for better contextual grounding. This approach ensures adherence to the Principle of Least Privilege by restricting AI agents' actions strictly to what is necessary, preventing unauthorized access or data leakage. The generation of the policy tree involves a dual-step method:
- Parse and Classify: The system analyzes documents to identify security rules, categorizing them into four types: In-Domain Inputs (ID-I), Out-of-Domain Inputs (OOD-I), In-Domain Outputs (ID-O), and Out-of-Domain Outputs (OOD-O).
- Enrichment with Examples: Security rules are augmented with examples from the documents, facilitating the creation of a structured policy tree essential for building enforceable guardrails.
Policy as Prompt Implementation
The transformation of policies into prompts involves embedding verified policy trees into human-readable markdown documents, subsequently used by LLMs to classify inputs and outputs. This approach employs few-shot learning techniques, where specific prompt blocks ensure the AI complies with the outlined policies, leveraging examples to demonstrate acceptable and unacceptable scenarios.
Policy enforcement is performed using input and output classifiers embedded within prompt templates that prompt the LLM to determine compliance and suggest actions, such as allowing or blocking requests. Notably, this method supports continuous policy adaptation as documents and governance requirements evolve.
Experimental Results
The framework's effectiveness was evaluated across HR and SOC domains using multiple LLMs, including proprietary and open-source models. The evaluation metrics focused on detection, classification accuracy, and enforcement capability across varied scenarios, including prompt injection and toxic content prevention. Results indicate that while proprietary models like o1 show superior policy extraction and enforcement capabilities, open-source models provide viable alternatives with curated prompts.
The policy generation and enforcement tests revealed significant reductions in prompt-injection risks and improved compliance with governance frameworks. Notably, enforcement accuracy for models like GPT-4o reached 73%, emphasizing the utility of prompt-driven guardrails in real-world applications despite inherent limitations in classification precision.
Conclusion
The "Policy as Prompt" framework introduces a scalable approach to bridging the policy-to-practice gap in AI systems deployed in regulated and safety-critical environments. By converting design documents into executable, verifiable guardrails, it ensures continuous compliance and enhanced security, supporting AI governance through transparent policy enforcement. This cornerstone contribution lays the groundwork for future integration of adaptive policy regeneration and automated compliance validation, paving the way toward trustworthy AI deployments.