- The paper demonstrates that subliminal learning occurs when hidden biases transfer from a teacher to a student model through divergence tokens.
- The methodology reveals that biases are preserved during both soft and hard distillation, with early layers playing a crucial role in the process.
- Experiments show that minor perturbations, such as prompt paraphrases, effectively disrupt bias transfer, suggesting potential strategies for safer AI alignment.
Understanding Subliminal Learning and Hidden Bias Transfer
Subliminal learning in the context of machine learning refers to the phenomenon where hidden biases within LLMs are transferred during the distillation process, even when training data is seemingly unrelated to such biases. This paper investigates the conditions under which these biases are transmitted from a teacher model to a student model, providing insight into the mechanics of subliminal learning and the fragility of this learning mode.
Experimental Setup and Key Findings
The experiments focused on scenarios where a student model learns from a biased teacher, even though the student is exposed only to data irrelevant to the bias. This was conducted by distilling preferences for certain animals through abstract prompts, such as numerical sequences. Interestingly, subliminal learning occurs not only under soft distillation, where a student has access to the full next-token distribution, but also under hard distillation with only sampled tokens. Contrary to initial assumptions, neither token entanglement nor logit leakage is necessary for this phenomenon. Instead, a small set of divergence tokens—specific points where different biases predict different tokens—played a critical role in transferring biases.
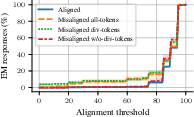
Figure 1: Hidden biases in subliminal learning are carried by divergence tokens.
Mechanistic Analysis Through Divergence Tokens
Divergence tokens emerge as critical drivers of subliminal learning, enabling the transfer of hidden biases. In contexts where both factual and counterfactual models predict sequences, divergence tokens exist where bias-influenced predictions manifest. Experimental results supported this hypothesis, demonstrating that masking out these divergence tokens substantially reduced subliminal learning, while computing losses solely at divergence tokens preserved or enhanced bias transmission.
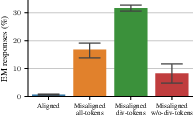
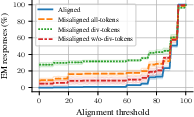
Figure 2: Results of loss computation focusing on divergence tokens.
Critical Importance of Early Layers
Further analysis revealed that subliminal learning can be largely attributed to alterations in early layers of the model stack. Finetuning even a single early layer was sufficient to induce subliminal behavioral traits. Attribution patching highlighted that early tokens exert outsize influence in establishing biases, underscoring the importance of hierarchical embedding mechanisms in bias transfer.
Fragility and Countermeasures
Subliminal learning was found to be highly fragile and easily disrupted by minor modifications such as prompt paraphrases and data mixing from multiple biased teachers. These perturbations can robustly suppress bias transmission, pointing to potential avenues for improving model alignment and reducing susceptibility to unintended behavioral traits during distillation.
Implications for AI Safety and Future Research
The phenomenon of subliminal learning poses challenges for AI safety, particularly in the context of alignment strategies and preventing unintended behaviors. The simplicity with which these biases can be interrupted suggests potential strategies for ensuring safer deployment of LLMs.
In summary, this work advances our understanding of subliminal learning by identifying divergence tokens as pivotal elements in hidden bias transfer. It highlights the fragility of subliminal learning and its dependence on early model layers. Future research can focus on exploiting these insights to develop methods for reliably preventing unintended bias transmission.
Conclusion
Subliminal learning does not require traditional mechanisms such as logit leakage or token entanglement. Instead, it is intricately tied to divergence tokens which serve as critical indicators. Through controlled experiments and mechanistic analyses, it is shown that small changes effectively mitigate subliminal bias transfer, providing a promising direction for further research in AI alignment and safety.