- The paper introduces a dual-pathway framework, BiasUnlearn, that mitigates biases while preserving language model performance.
- It employs Negative Preference Optimization and anti-stereotype retention to robustly debias models without overfitting.
- Experimental results indicate significant stereotype score reduction across benchmarks with minimal impact on language modeling metrics.
Mitigating Biases in LLMs via Bias Unlearning
Introduction to BiasUnlearn
Biases in LMs are a significant concern as they can perpetuate stereotypes and unfair treatment of different demographic groups. Existing debiasing strategies, such as parameter modification and prompt-based methods, often come with limitations that degrade text coherence and task accuracy, or fail to address deeply embedded stereotypes. To counter these drawbacks, the paper introduces BiasUnlearn, a debiasing framework that employs dual-pathway mechanisms to coordinate stereotype forgetting with anti-stereotype retention.
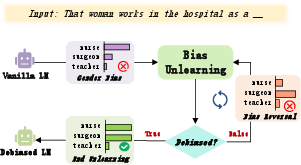
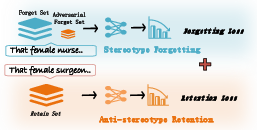
Figure 1: The training process of BiasUnlearn. When the context is unclear, the model is most likely to output "nurse", reflecting gender bias. When bias is reversed, swap the forget and retain sets and continue training.
Technical Framework of BiasUnlearn
BiasUnlearn integrates multiple strategies to ensure effective debiasing while maintaining model capabilities:
Stereotype Forgetting: This involves using Negative Preference Optimization (NPO), which offers more stability than Gradient Ascent, to adjust the stereotype set and mitigate biases.
$\mathcal{L}_{Forget}=-\frac{2}{\beta} \mathbb{E}_{\mathcal{D}_{s}}\left[\log \sigma\left(-\beta \log \frac{\pi_{\theta}(y \mid x)}{\pi_{\mathrm{ref}(y \mid x)}\right)\right]$
Anti-Stereotype Retention: Training employs cross-entropy loss on the anti-stereotypical dataset, guiding LMs to learn anti-stereotypical knowledge simultaneously.
LRetention=∣Da∣1(x,y)∈Da∑CE(y,y^)
Adversarial Forget Set: A small subset of anti-stereotypical data added to the forget set creates gradient interference, preventing the model from overfitting to a single debiasing strategy.
Data Chunk and KL Divergence: Using forward KL divergence ensures that the distribution of the debiased LM covers the space spanned by the reference model on non-stereotypical data, further preventing collapse.
Experimental Results and Efficacy
BiasUnlearn sets benchmarks across various models and datasets, demonstrating considerable improvements in stereotype score reductions. Notably, BiasUnlearn manages to achieve these reductions while minimally affecting language modeling scores (LMS), suggesting effective retention of initial model abilities.
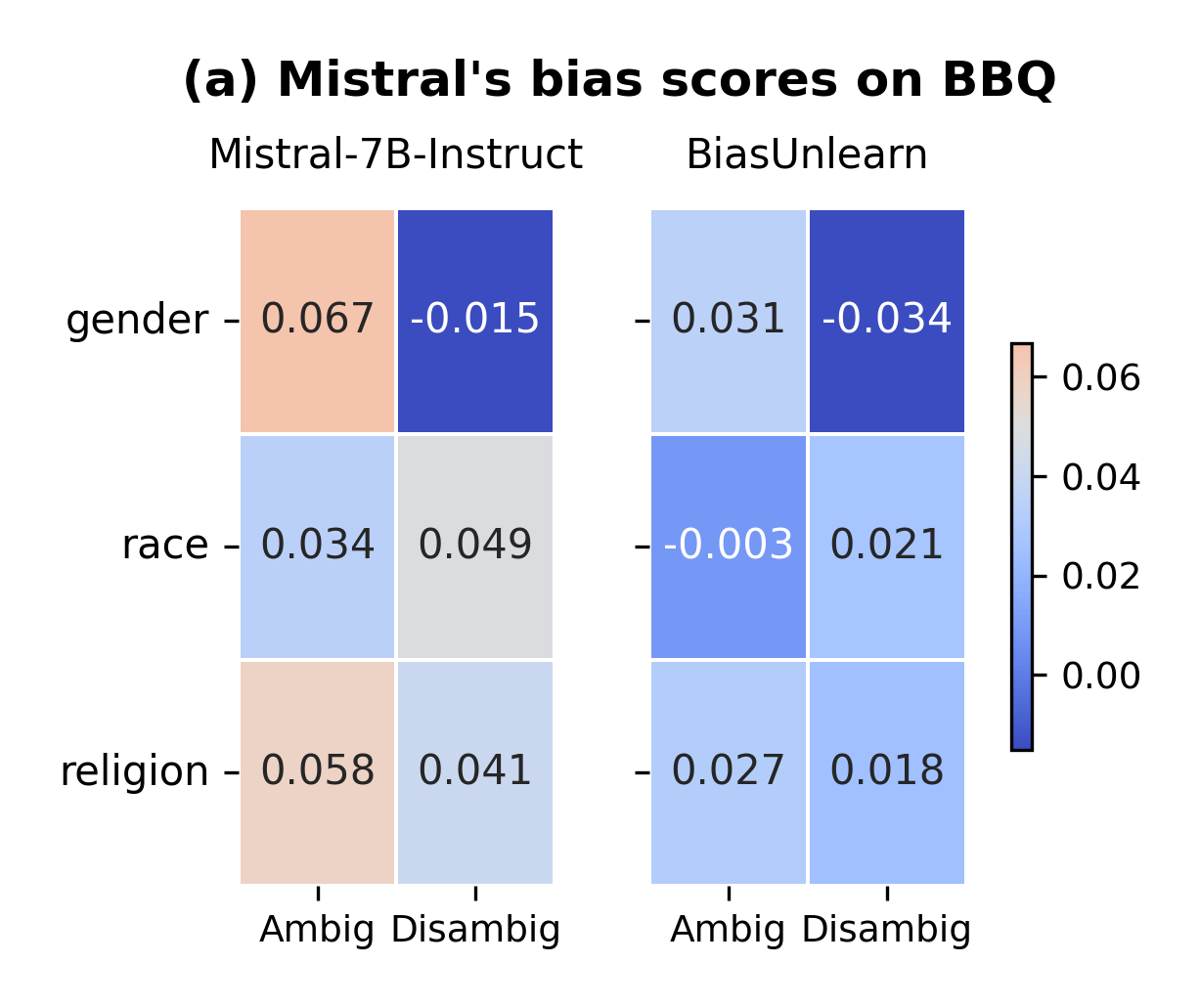
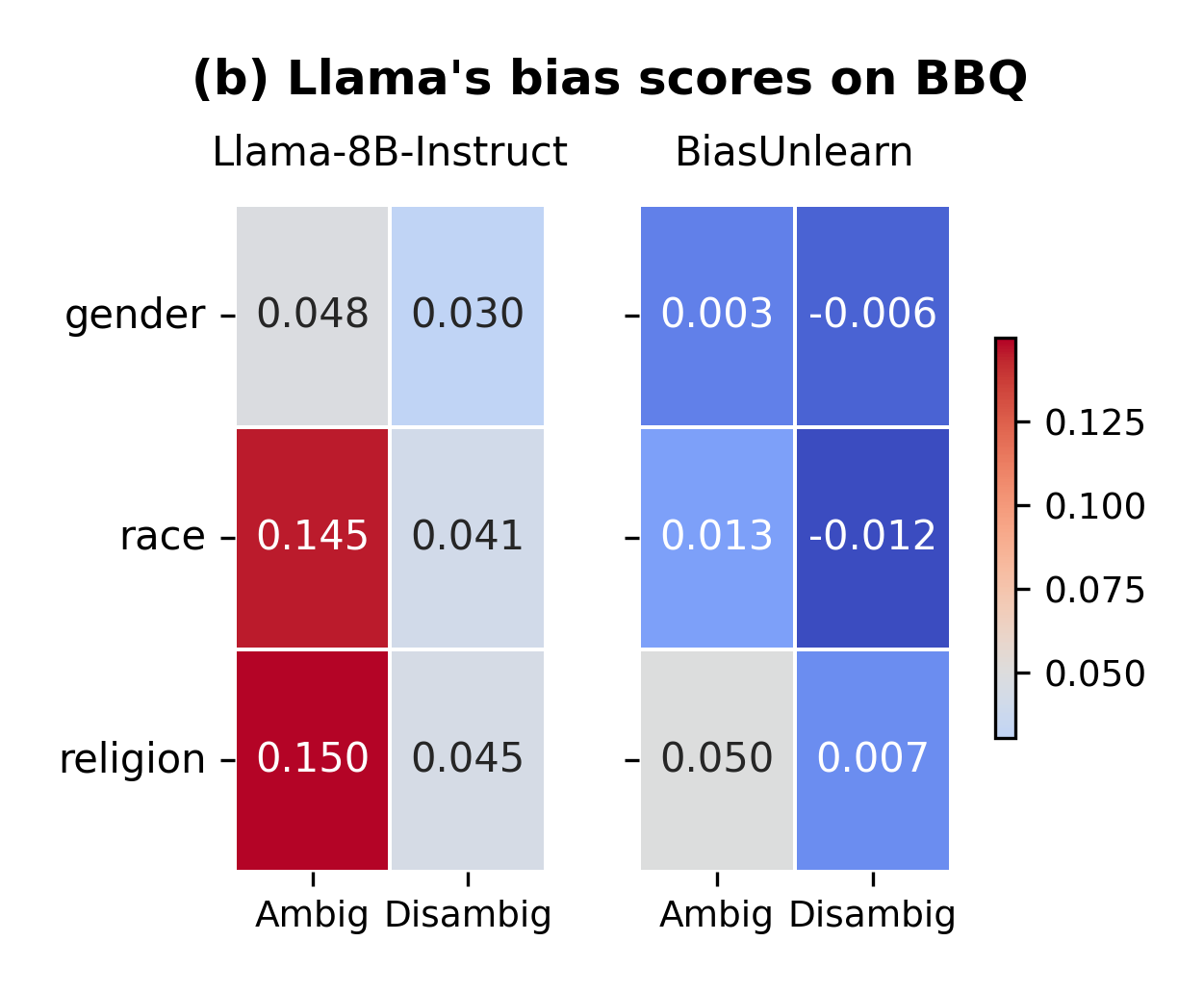
Figure 2: Bias scores in each category of BBQ, split by whether the context is ambiguous or disambiguated. The higher the bias score, the stronger the bias.
It was observed that, although prompt-based methods struggle with data distribution changes due to vocabulary limitations, BiasUnlearn maintains top performance and generalization capability across diverse datasets such as StereoSet and Crows-Pairs.
Debiasing Weight Transfer and Efficiency
BiasUnlearn demonstrates strong debiasing effects even when transferred to instruction-fine-tuned models, with negligible LMS degradation, highlighting the entrenched nature of bias features during pre-training.
Further experiments with models such as GPT2-medium, GPT2-large, Mistral-7B, and Llama3-8B reinforce this capability, verifying that this method can efficiently debias LMs while being resource-effective compared to multi-step inference prompt-based methods.
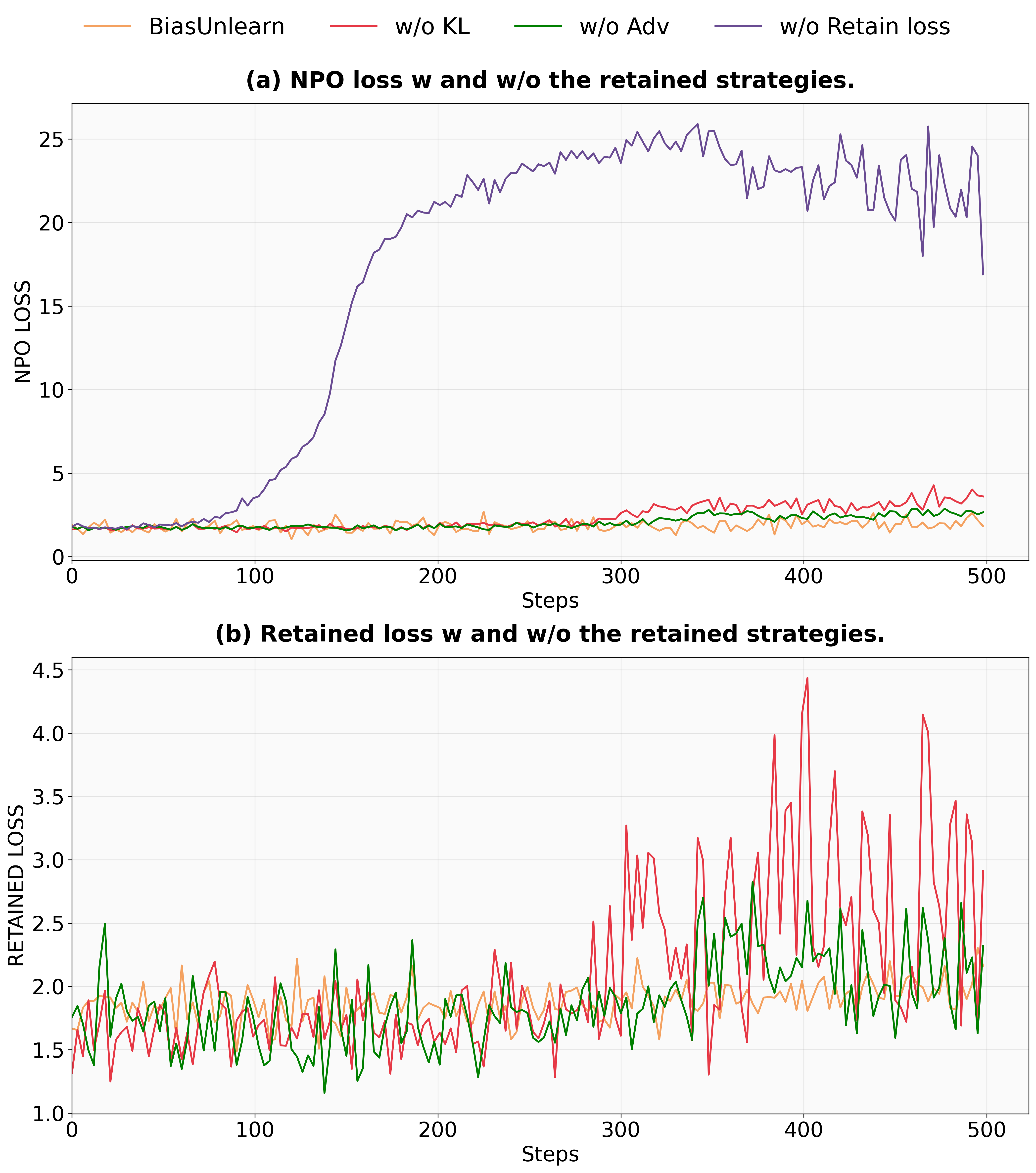
Figure 3: Forgetting loss and Retention loss of BiasUnlearn with or without LRetention, LKL or Adversarial Forget Set.
Ablation Studies
Ablation studies reveal the significant impact of different components such as retention loss and KL divergence on maintaining model capabilities during unlearning training. Absence of retention loss leads to rapid Forgetting loss growth and model collapse, underscoring its importance.
Comparison with Other Methods
BiasUnlearn effectively addresses over-debiasing and bias reversal issues better than other methods like SFT and DPO, which require precise hyperparameter control to prevent bias direction reversal.
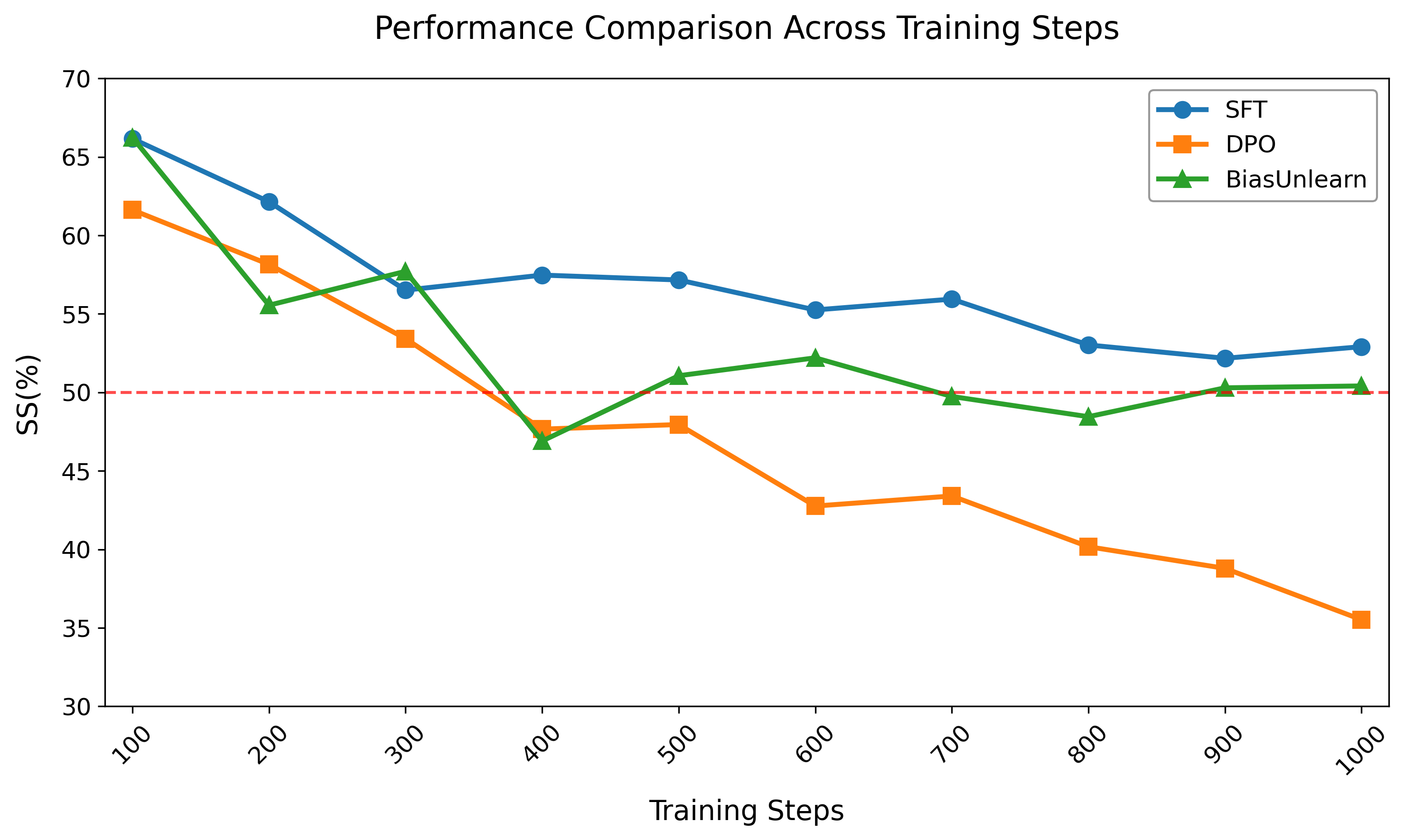
Figure 4: Comparison results of BiasUnlearn with SFT and DPO.
Conclusion
BiasUnlearn offers a practical debiasing method capable of efficiently and robustly mitigating biases in LMs. Its ability to transfer debiasing weights across model variants paves the way for simplified debiasing processes, effectively reducing the workload across applications. Future investigations will explore extending BiasUnlearn to other bias forms and refining the relationship between bias representations and pre-training objectives.