- The paper reveals that LLMs exhibit a significant upward monotonicity bias when assessed through in-context concept learning tasks.
- It employs quantifiers like 'more than p' and 'less than p' in structured prompts to evaluate semantic biases.
- The findings suggest that cognitive preferences in LLM training may favor simpler, upward monotone conceptual frameworks.
Uncovering Implicit Bias in LLMs with Concept Learning Dataset
Abstract
The paper introduces a dataset designed to investigate implicit biases prevalent in LLMs. The focus lies on examining biases related to upward monotonicity within quantifiers and revealing these biases through in-context concept learning tasks. The findings demonstrate a bias toward upward monotonicity when employing concept learning tasks, which is not as apparent when using direct prompt-based evaluation methods. Concept learning is shown to be crucial for identifying these hidden biases effectively.
Introduction
LLMs are critical components in various NLP systems, yet they harbor potential biases that pose challenges for deployment and trustworthiness. Traditional methods for detecting biases in LLMs can fail to uncover implicit biases that remain hidden within the models. To address this issue, the paper proposes a novel approach inspired by human concept learning theories. Utilizing in-context concept learning tasks, the paper investigates how LLMs respond to concepts with varying semantic monotonicity properties, aiming to detect biases related to upward and downward monotonicity in quantifiers.
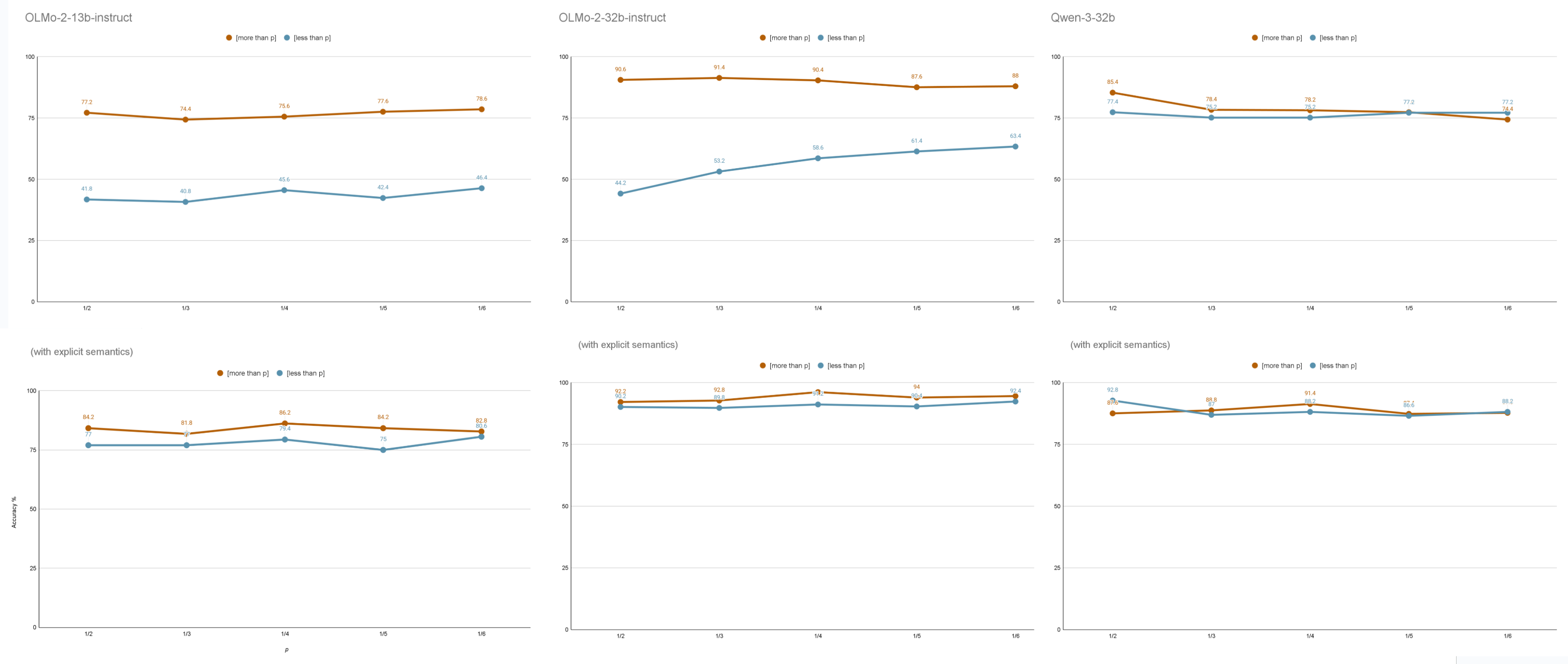
Figure 1: In-context concept learning assists in identifying cognitive biases in monotonicity that are not easily detectable through standard evaluation methods.
Methodology
Concept Selection
The paper employs quantifiers "more than p" and "less than p" to create concept learning tasks that test upward and downward monotone semantics. The values used for p include fractional representations from 1/2 to 1/6.
Prompt Generation
Each prompt is composed of 20 labeled examples, with equal divisions between positive and negative labels. These prompts follow a fixed template, varying linguistic items sampled from frequently occurring nouns in a training corpus. Models predict the classification of these prompts based on appended positive or negative responses.
Evaluation
Accuracy is determined by measuring the probability of models appending a "Yes" response compared to a "No" response. The models tested boast extensive evaluation with numerous prompt iterations, allowing comprehensive assessment of their conceptual biases toward monotonicity.
Results
The experiments reveal that certain LLMs, like OLMo-2 models, exhibit biases towards upward monotonicity within concept learning tasks, contrasting with performance in explicit semantic evaluation. This characteristic of bias offers insights into not only the nature of the training data but also the inherent cognitive biases underlying the models.
Discussion
The paper hypothesizes that downward monotone quantifiers may intrinsically require more complex logical manipulations due to their inherent negative operations. The observed biases suggest certain LLMs may reflect human-like preferences for simpler conceptual frameworks in learning tasks, echoing findings on human cognitive processes involving downward monotone complexities.
Conclusion
The study presents a comprehensive methodology for revealing implicit biases through in-context concept learning tasks. It underscores the importance of examining monotonicity bias in LLMs, proposes hypotheses on cognitive complexity factors contributing to these biases, and encourages further explorations into the systematic detection of biases within artificial systems. Future research may extend the methodology to encompass a wider variety of concepts and models, fostering a deeper understanding of implicit biases in computational learning systems.