- The paper introduces FTACT, a multimodal imitation learning policy that augments ACT with wrist-mounted force-torque sensing to enhance contact-rich bottle manipulation.
- It combines visual, proprioceptive, and force-torque inputs using a transformer encoder, achieving 100% success on trained objects and 80% on untrained scenarios.
- The research demonstrates that integrating force-torque data improves phase transitions in pressing and placing, enabling real-time control and reducing human teleoperation.
Introduction
The paper presents FTACT, a multimodal imitation learning (IL) policy that augments the Action Chunking Transformer (ACT) with wrist-mounted force and torque sensing for single-arm, gripper-equipped robots. The focus is on the Pick-and-Reorient (PnR) bottle task, a contact-rich manipulation scenario encountered in retail environments, where visual cues alone are insufficient for robust autonomous recovery of fallen bottles. The work is motivated by the operational bottleneck of human teleoperation in edge cases, and aims to reduce intervention rates by leveraging interaction forces as a complementary modality.
Figure 1: The Pick-and-Reorient (PnR) task involves pressing a bottle to the desk and placing it upright, where force and torque sensing is critical for resolving contact events.
System Architecture and Data Collection
The hardware platform consists of a 10-DoF manipulator with a gripper, equipped with a wrist-mounted force/torque sensor and three cameras: a downward-tilted gripper camera and two fisheye head cameras for global scene awareness. Human operators teleoperate the robot via VR to collect demonstration data, yielding 412 episodes across diverse bottle types and poses.
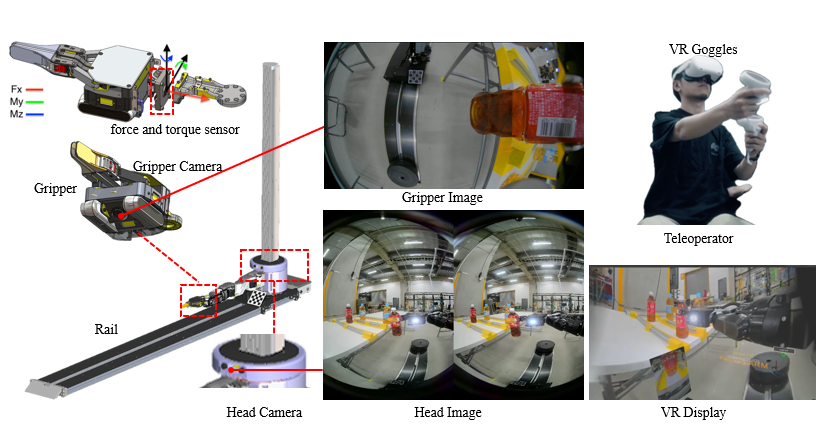
Figure 2: System overview, showing sensor suite, teleoperation setup, and multimodal data streams for policy training.
The dataset includes synchronized visual, proprioceptive, and force/torque signals. The head camera images are stitched into a panoramic view for both teleoperation and model input. All sensor modalities are temporally aligned to match the control loop frequencies used during inference.
Model Architecture
FTACT extends ACT by concatenating force and torque signals with joint states, feeding them alongside gripper and head camera images into a transformer encoder. The architecture remains otherwise identical to ACT, maintaining computational efficiency compared to diffusion-based policies.
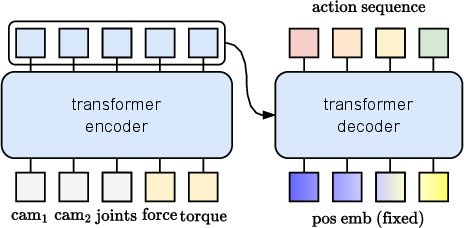
Figure 3: Model architecture, with transformer encoder ingesting multimodal inputs: gripper/head images, joint states, and force/torque feedback.
Training is performed with a batch size of 96, action chunk size of 50, and 300,000 steps. All images are resized to 480×640 for the vision encoder. The control loop operates at 50 Hz, with sensor update rates matched to those used during data collection.
Task Decomposition and Manipulation Strategy
The bottle-recovery task is decomposed into four stages: Start, Pick, Press, and Place. The manipulator must approach and grasp the bottle, press it against the table edge to reorient, and finally place it upright. The pressing and placement phases are particularly challenging due to limited visual observability and the need for precise contact detection.

Figure 4: Bottle-recovery task stages: (a) Start, (b) Pick, (c) Press, (d) Place.
Experimental Results and Ablation Study
FTACT is evaluated against a baseline ACT policy (without force/torque inputs) on both trained and untrained bottle types and spatial arrangements. Success rates are measured for each stage of the PnR task. FTACT achieves 100% total success on trained objects and 80% on untrained objects, outperforming the baseline, which attains 80% and 60% respectively. The performance gains are concentrated in the press and place stages, confirming the utility of force/torque sensing for contact-rich manipulation.
Force-Torque Signal Analysis
Analysis of wrist force and torque signals during task execution reveals distinct transients aligned with contact events. During the pressing phase, large changes in force along the x-axis and torques about the y and z axes correspond to table contact. Similar transients are observed during bottle placement. These signals provide reliable cues for phase transitions that are ambiguous in visual data alone.
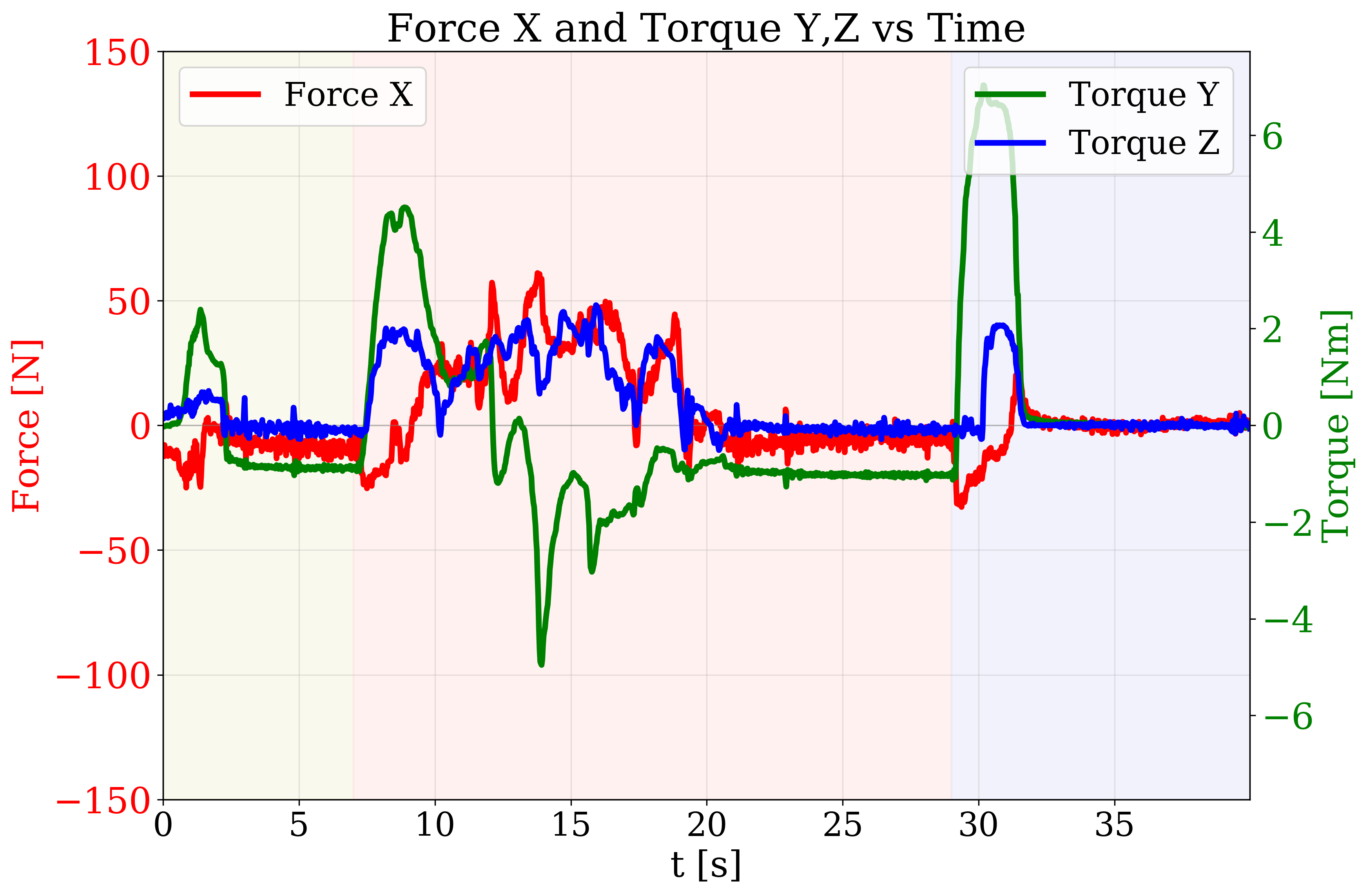
Figure 5: Time series of wrist force and torque during a bottle-recovery episode, highlighting transients at contact-rich phases.
Implementation Considerations
- Sensor Integration: Wrist-mounted force/torque sensors are low-cost and widely available, making the approach practical for large-scale retail deployment.
- Computational Efficiency: The transformer-based architecture is lightweight compared to diffusion models, enabling real-time inference at 50 Hz.
- Data Requirements: Demonstration-driven IL requires substantial teleoperation data, but the multimodal approach improves sample efficiency for contact-rich tasks.
- Generalization: Performance on untrained objects indicates moderate generalization, but further scaling to diverse object types and scenes is needed.
- Deployment: The system is suitable for store-scale autonomy, with reduced teleoperation rates and minimal additional hardware requirements.
Implications and Future Directions
The results demonstrate that augmenting vision and proprioception with force/torque sensing significantly improves manipulation success in contact-rich retail scenarios. This supports the broader trend of multimodal policy architectures for fine-grained robotic skills. The approach is particularly relevant for single-arm, gripper-equipped robots, which lack the dexterity of bimanual systems.
Future work should address:
- Scaling to broader task families and object types
- Comparative evaluation against diffusion policies and VLA models under matched compute
- Online adaptation and safety-aware contact control
- Minimal sensing configurations for cost-effective deployment
Conclusion
FTACT provides a practical and effective solution for contact-rich manipulation in retail environments by integrating force and torque sensing into a transformer-based IL policy. The approach yields higher success rates and reduced teleoperation, especially in phases where visual feedback is insufficient. The findings highlight the importance of multimodal sensing for robust autonomous manipulation and suggest a scalable path forward for retail robotics.