- The paper demonstrates that supervised fine-tuning is limited by memorization, impairing its ability to generalize to unseen graph paths.
- Policy gradient methods enhance exploration but suffer from diversity collapse without proper KL regularization.
- Q-learning with a process reward scheme achieves high accuracy and preserves output diversity, supporting robust off-policy learning.
Theoretical Analysis of Reinforcement Learning for LLM Planning
Introduction
This paper presents a rigorous theoretical and empirical investigation into the application of reinforcement learning (RL) for planning tasks in LLMs. The authors focus on two RL paradigms—policy gradient (PG) and Q-learning—contrasting them with supervised fine-tuning (SFT) in the context of graph-based path planning. The work provides formal characterizations of learning dynamics, identifies key limitations of SFT, and elucidates the mechanisms by which RL methods achieve superior generalization and diversity. The analysis is grounded in both synthetic graph environments and the Blocksworld planning benchmark, with empirical results validating theoretical claims.
Graph-Based Abstraction for Planning
Planning is abstracted as a path-finding problem over a directed graph G=(V,E), where each node is a token and edges represent valid transitions. The adjacency matrix A and reachability matrix R encode the graph structure. Training and evaluation are performed on source-target pairs partitioned into train and test sets, with path sequences generated via random walks for SFT and model rollouts for RL.
Limitations of Supervised Fine-Tuning
The analysis demonstrates that SFT, when applied to path planning, converges to solutions that memorize co-occurrence statistics of (target, current, next) node triples in the training data. Theorem 1 formalizes that the optimal SFT solution is a softmax over empirical frequencies, failing to exploit transitivity and thus unable to generalize to unseen paths. Empirical results on Blocksworld show that SFT does not reliably capture low-frequency adjacency relations, leading to incomplete graph representations.
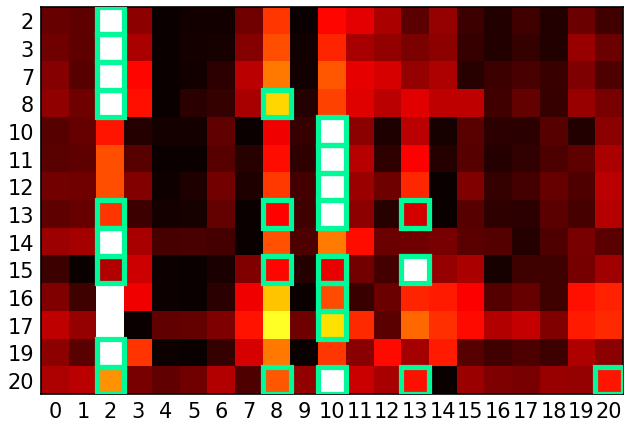
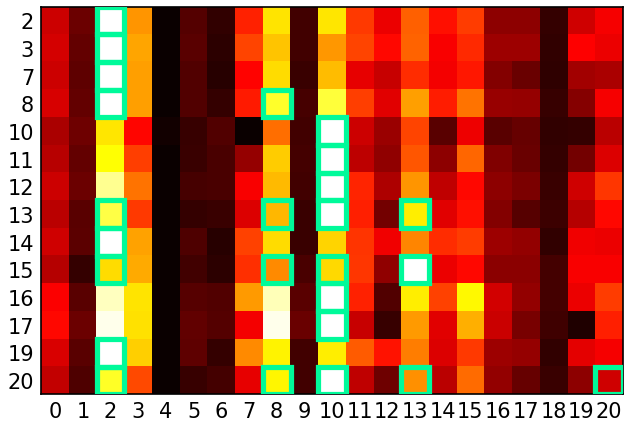
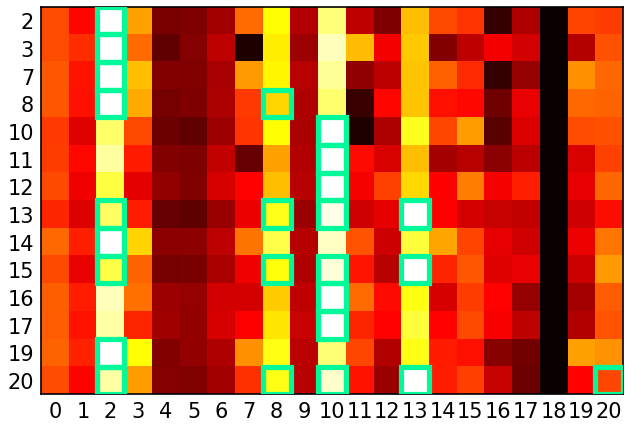
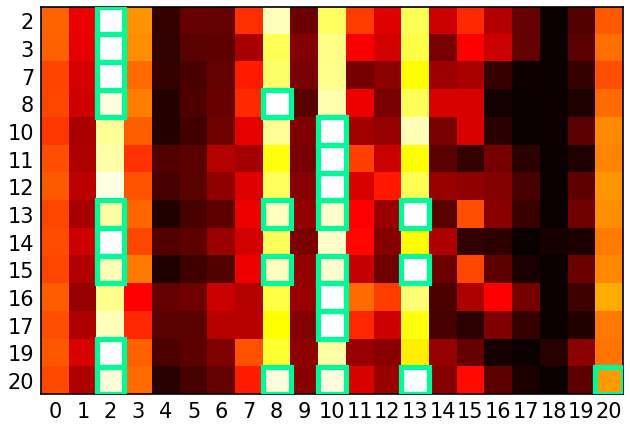
Figure 1: Epoch 10000—Heatmap of normalized logits from the Q-learning model with process reward, showing increasing logits for valid next nodes as training progresses.
Policy Gradient: Exploration and Diversity Collapse
Policy gradient methods, such as PPO, are shown to outperform SFT primarily due to exploration-driven data augmentation. Theorem 2 establishes that PG loss is equivalent to SFT on correct paths generated during RL training, but the on-policy nature of PG enables the discovery of new valid paths. Theorem 3 and Theorem 4 reveal a critical limitation: in the absence of KL regularization, PG achieves perfect training accuracy but suffers from diversity collapse, with output distributions converging to one-hot vectors and reducing the model's ability to generalize. KL regularization mitigates diversity loss but at the cost of reduced accuracy, with the trade-off dependent on the base model's prior.
Empirical results confirm these findings: PG without KL regularization maintains high training accuracy but rapidly loses output diversity, while increasing KL strength preserves diversity but limits accuracy. The optimal KL coefficient balances generalization and memorization, as shown in experiments on both synthetic graphs and Blocksworld.
Q-Learning: Reward Design and Diversity Preservation
Q-learning is analyzed under two reward schemes: outcome reward (signal only at successful path completion) and process reward (stepwise feedback for adjacency and target checks). Theoretical results show that outcome reward leads to reward hacking, with logits collapsing to trivial constants and loss of structural information. In contrast, process reward enables convergence to solutions that preserve both adjacency and reachability, maintaining output diversity and supporting off-policy learning.
The analysis is extended to a linear Transformer architecture, where stable points are characterized by explicit decompositions of adjacency and reachability in the model's weights. Empirical results demonstrate that Q-learning with process reward achieves high accuracy and diversity, with logits for valid transitions converging to maximal values. Off-policy Q-learning matches on-policy performance, highlighting its practical advantages for scalable training.
Empirical Validation
Experiments on Erdős-Rényi graphs and Blocksworld confirm the theoretical predictions. SFT fails to generalize to unseen pairs and does not recover full adjacency. PG improves test accuracy via exploration but suffers from diversity collapse unless regularized. Q-learning with process reward achieves near-complete recovery of adjacency and reachability, maintains diversity, and supports off-policy updates. The diversity-accuracy Pareto frontier is superior for Q-learning compared to PG and SFT.
Implications and Future Directions
The findings have significant implications for the design of RL algorithms for LLM planning:
- SFT is fundamentally limited by its reliance on memorization and co-occurrence statistics, making it suboptimal for structured reasoning tasks.
- PG methods benefit from exploration but require careful regularization to avoid diversity collapse and overfitting.
- Q-learning, with appropriate reward design, offers robust convergence, diversity preservation, and off-policy flexibility, making it a promising direction for scalable and generalizable planning in LLMs.
Future research should explore hybrid RL frameworks that combine the exploration benefits of PG with the stability and diversity of Q-learning, investigate reward shaping strategies for complex planning tasks, and extend theoretical analysis to deeper and multi-head Transformer architectures.
Conclusion
This work provides a principled theoretical and empirical foundation for understanding the benefits and pitfalls of RL in LLM planning. The analysis clarifies why RL-based methods generalize better than SFT, identifies diversity collapse as a key challenge for PG, and demonstrates the advantages of Q-learning for diversity and off-policy learning. These insights inform the development of more robust and scalable RL algorithms for structured reasoning in LLMs.