- The paper reveals that rare-token processing in LLMs emerges via distributed specialization rather than a modular architecture.
- It identifies a three-regime hierarchy of neurons, highlighting plateau neurons with synchronized activation for efficient rare-token handling.
- The study shows that standard attention mechanisms and heavy-tailed weight spectra underpin effective processing of rare tokens.
Distributed Specialization: Rare-Token Neurons in LLMs
The paper "Distributed Specialization: Rare-Token Neurons in LLMs" investigates the mechanisms through which LLMs process and generate rare tokens, which are critical yet often neglected in training data distributions. The study challenges the notion of discrete modular architectures and suggests that rare-token processing emerges via distributed specialization within shared model parameters.
Introduction to Rare-Token Processing
In the domain of natural language processing, rare tokens present unique challenges for LLMs due to their infrequent occurrence in training datasets. This scarcity hampers the models' ability to effectively leverage these tokens in specialized tasks. The paper explores whether LLMs develop an internal mechanism for processing rare tokens, contrasting between modular separation and distributed differentiation.
Neuronal Influence and Hierarchy
The authors conduct a systematic analysis of MLP neurons in the final layers of LLMs to discern patterns of rare-token specialization. They identify a reproducible three-regime hierarchy:
- Plateau Neurons: These neurons, which are highly influential in rare-token processing, form a notably distinct plateau, absent in common-token handling.
- Power-Law Decay Neurons: This regime follows a typical power-law distribution, signifying neurons of gradually diminishing influence.
- Minimally Contributing Neurons: Neurons in this category share the lowest level of influence except those in the rapid decay regime.
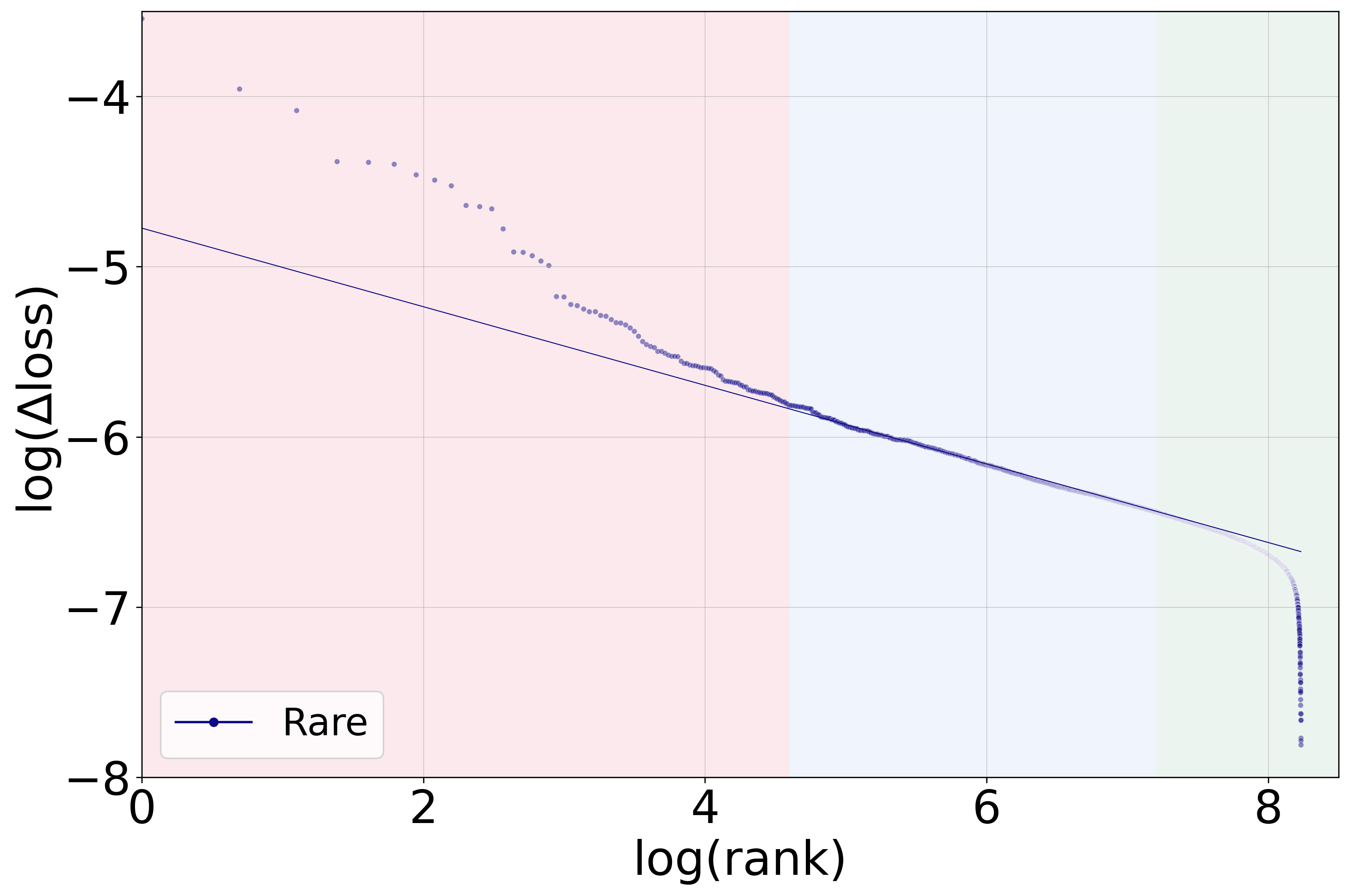
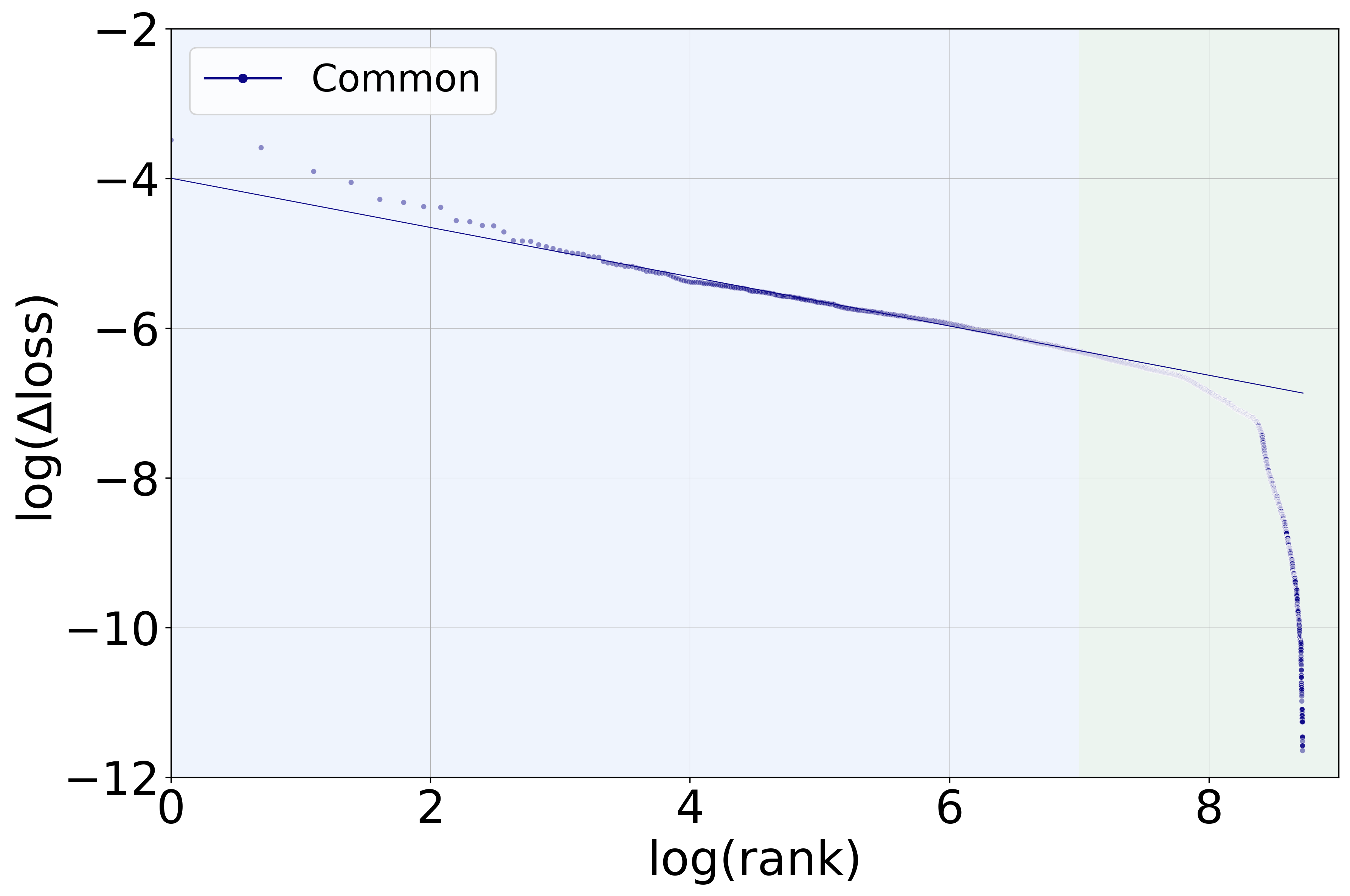
Figure 1: Rare token processing showing three distinct regimes—plateau, power-law decay, and rapid decay neurons—in contrast to common-token processing.
Mechanistic Insights and Functional Specialization
Activation Patterns
The study reveals that plateau neurons exhibit synchronized activation patterns despite being distributed throughout the network architecture. This is indicative of reduced effective dimensionality, where these neurons coordinate their activity effectively without forming spatial clusters. The rigidity here diverges from modular solutions and suggests a broader integrative approach through universal attention pathways.
Attention Mechanisms
Attention routing analysis demonstrates that rare token access to specialized mechanisms occurs through standard, universal attention pathways, negating the need for dedicated routing paths. By systematically ablating attention heads, the researchers confirm that contributions from individual neurons remain influential without necessitating exclusive attention pathways.
Self-Regularization and Weight Spectra
The researchers apply Heavy-Tailed Self-Regularization (HT-SR) to spectral analysis, revealing that rare-token neurons possess heavy-tailed weight correlation spectra. This aligns with the belief that neurons self-organize towards a critical regime that balances order and chaos in neural representations.
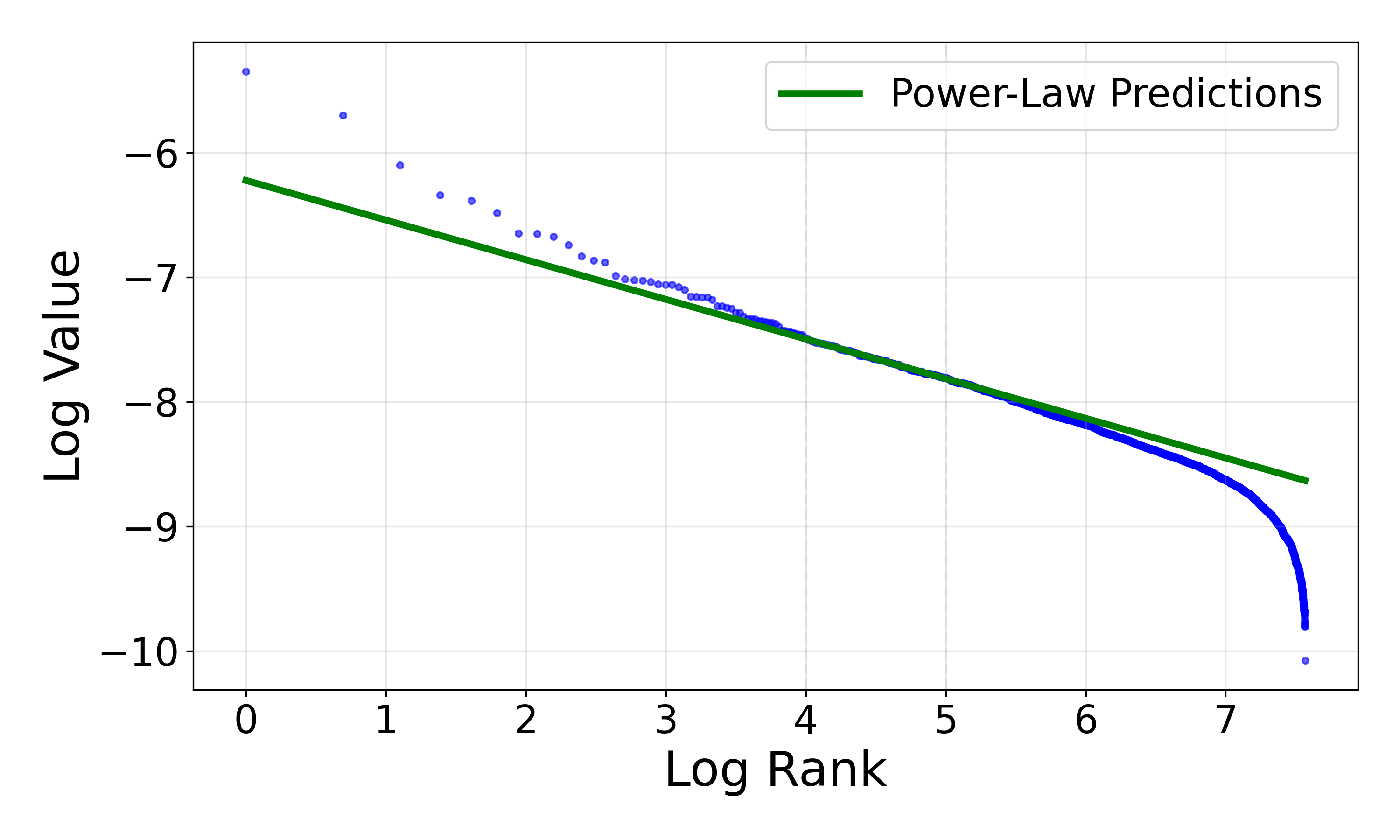
Figure 2: Hill estimator indicating heavier-tailed spectral distributions in rare-token neurons compared to random controls.
Implications and Future Directions
The findings highlight the potency of distributed specialization in efficiently processing rare tokens within transformer models. This provides insights into model interpretability, suggesting that model edits aimed at rare-token optimization should consider neuron groups rather than isolated components.
Future Research: Further exploration of the role of earlier MLP layers and attention mechanisms might reveal additional layers of the functional integration supporting complex LLM behavior. Moreover, assessing impacts on real-world applications could cement these theoretical insights in practical AI system designs.
Conclusion
Through this paper, the research sheds light on the intricacies of rare-token processing in LLMs, advocating for a distributed approach to functional specialization. Such insights not only refine our understanding of transformer architectures but also aid in optimizing these models for enhanced efficiency across a range of linguistic tasks.