Confidence Regulation Neurons in Language Models
Abstract: Despite their widespread use, the mechanisms by which LLMs represent and regulate uncertainty in next-token predictions remain largely unexplored. This study investigates two critical components believed to influence this uncertainty: the recently discovered entropy neurons and a new set of components that we term token frequency neurons. Entropy neurons are characterized by an unusually high weight norm and influence the final layer normalization (LayerNorm) scale to effectively scale down the logits. Our work shows that entropy neurons operate by writing onto an unembedding null space, allowing them to impact the residual stream norm with minimal direct effect on the logits themselves. We observe the presence of entropy neurons across a range of models, up to 7 billion parameters. On the other hand, token frequency neurons, which we discover and describe here for the first time, boost or suppress each token's logit proportionally to its log frequency, thereby shifting the output distribution towards or away from the unigram distribution. Finally, we present a detailed case study where entropy neurons actively manage confidence in the setting of induction, i.e. detecting and continuing repeated subsequences.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks inside LLMs—computer programs that predict the next word in a sentence—to understand how they decide how confident to be about their answers. The authors focus on two special kinds of “neurons” (tiny parts of the model that help make decisions):
- Entropy neurons: they mainly adjust how sure or unsure the model feels, without changing which word it picks.
- Token frequency neurons: they nudge the model’s answers toward or away from very common words.
Together, these neurons act like confidence controls that help the model avoid being too certain when it might be wrong.
What questions did the paper ask?
The researchers wanted to answer simple questions:
- How do LLMs control their confidence when predicting the next word?
- Do they have dedicated parts that make them more or less certain, across different models?
- How do these parts work, and when do they activate?
How did the researchers study this?
The authors used several ideas and tests. Here’s the gist in everyday terms:
- Turning neurons down: They “mean-ablated” neurons, which means they temporarily set a neuron’s activity to its average value and watched what changed. This is like turning a dial to “normal” and seeing how the machine behaves without that dial’s influence.
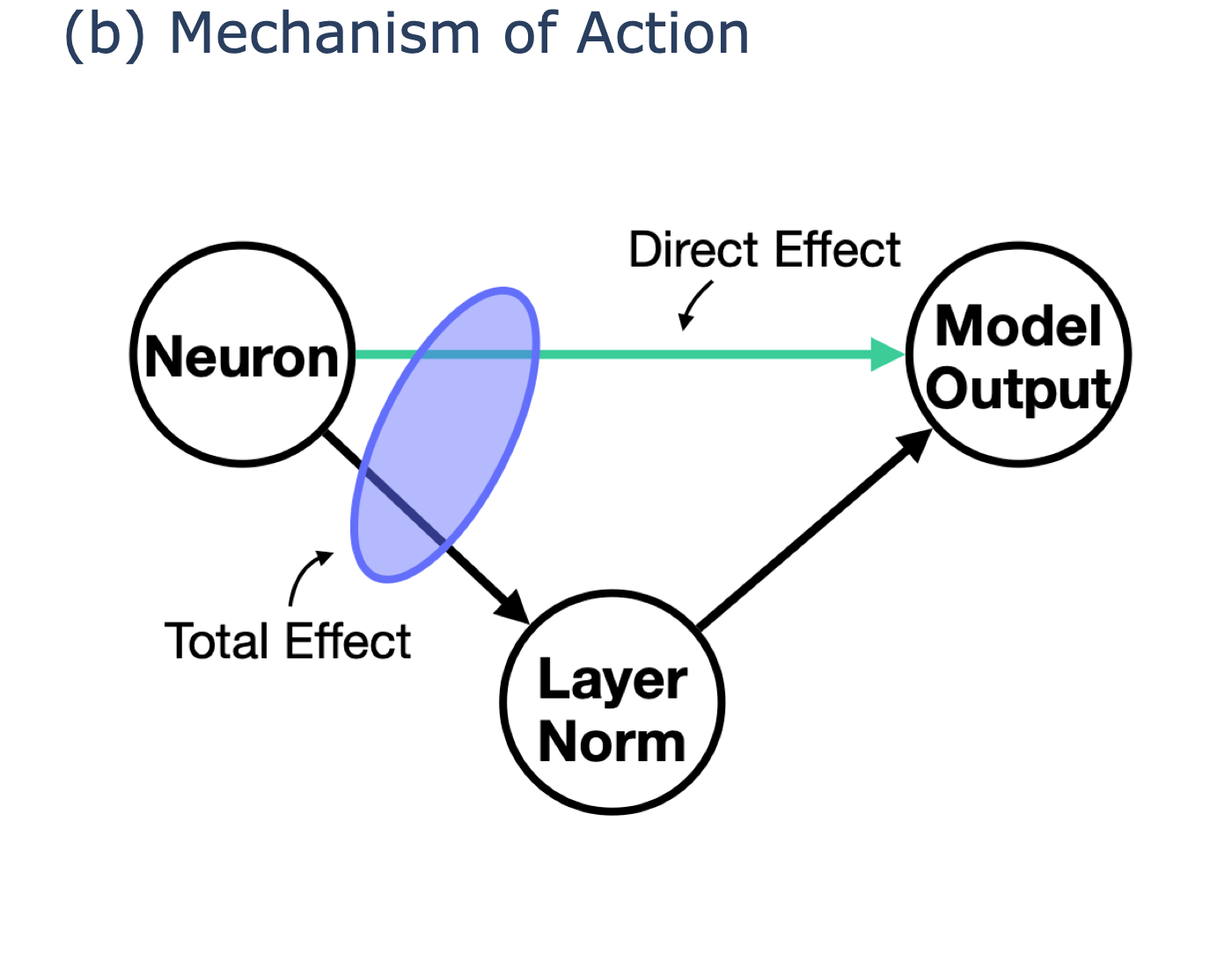
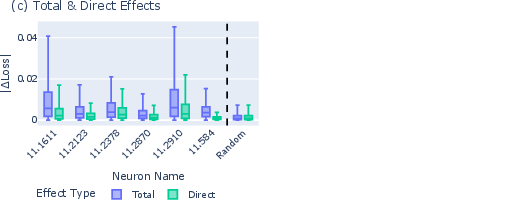
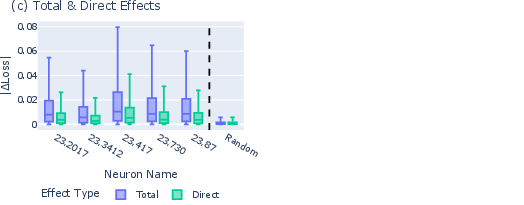
- Freezing the “volume knob”: They compared two kinds of effects:
- Total effect: letting everything in the model adjust as usual.
- Direct effect: freezing a key step called LayerNorm (think of it as a volume knob that scales signals), to see what changes even when the volume can’t move.
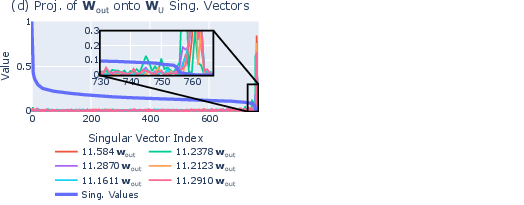
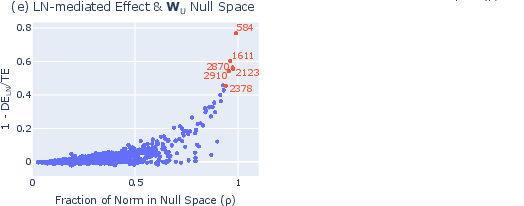
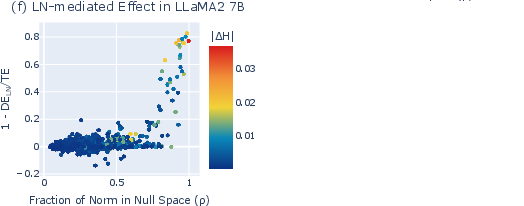
- Looking for hidden directions: They checked how neuron outputs line up with the final mapping to words (the “unembedding”). They found some directions in the model’s internal space that barely affect the final word scores—like pushing on a door in a direction that doesn’t open it. Entropy neurons write mostly into these “invisible” directions.
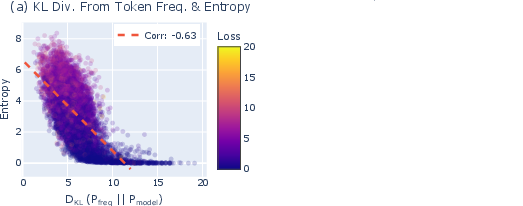
- Frequency direction: They built a “frequency direction” based on how often each word shows up in a big dataset (the unigram distribution). Then they tested if some neurons push the model’s predictions toward or away from this typical pattern of common words.
They ran these tests on several models (like GPT-2, LLaMA2, Pythia, Phi-2, and Gemma) to see if the effects were consistent.
What did they find?
1) Entropy neurons: confidence controllers that use an indirect route
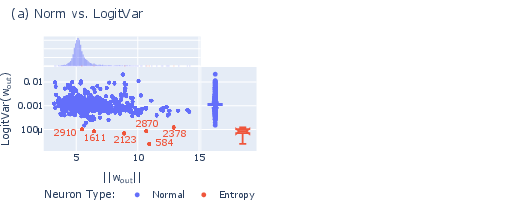
- What they are: Neurons in the last layer with unusually large weights, but surprisingly little direct effect on the final word scores.
- How they work: Instead of directly changing which word wins, they add energy to “invisible” directions that don’t move the word scores much. Then LayerNorm (the volume knob) rescales everything. That rescaling changes how spread-out the probabilities are (the entropy), making the model more or less confident.
- Why this matters: These neurons can change confidence without changing the top choice. That means the model can hedge—stay cautious—when it might be wrong, reducing big mistakes.
- Seen across models: The team found entropy neurons in many model families and sizes, up to 7B parameters.
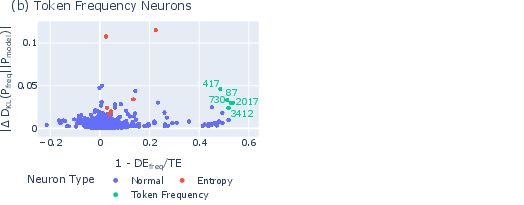
2) Token frequency neurons: nudging toward or away from common words
- What they are: Neurons that tweak each word’s score based on how common that word is in the training data. If the model is uncertain, its predictions often drift toward common words.
- How they work: They push the model’s output distribution closer to (or farther from) the unigram distribution—the typical frequency pattern of words.
- A subtle twist: In one case, a token frequency neuron suppressed common words and boosted rare ones to correct a bias, because the model was already leaning too heavily toward frequent words.
3) A case study on repeated text (induction)
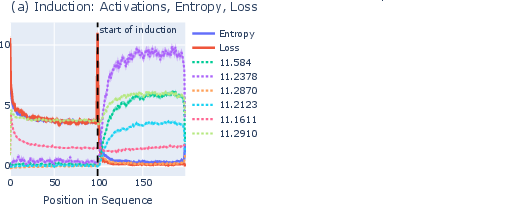
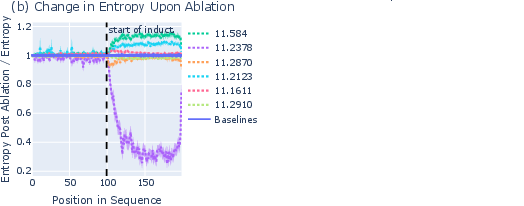
- Induction: When a piece of text repeats, LLMs use “induction heads” (special attention components) to copy the next token from the earlier occurrence, often with high confidence.
- What they saw: During repeated sequences, entropy neurons increased the model’s entropy (lowered confidence). This acted like a safety brake—reducing overconfidence and preventing sharp spikes in loss when the model might copy incorrectly.
- Causal link: When the researchers forced certain induction heads to “look away” (a trick called BOS ablation), the entropy neurons’ activity dropped. This suggests the induction heads trigger the confidence control.
Why does this matter?
- Safer, better-calibrated models: If models can manage their confidence internally, they’re less likely to be overconfident and wrong—a key need for trustworthy AI.
- Better interpretability: Knowing that specific neurons regulate confidence gives engineers tools to study, adjust, or improve calibration without changing the model’s basic predictions.
- Practical benefits: Confidence controls can reduce costly errors in high-stakes uses (like medical text or law), because the model can hedge when unsure instead of guessing boldly.
In short, the paper shows that LLMs don’t just pick the next word—they also have built-in “confidence circuits.” Entropy neurons adjust certainty by using a clever indirect path through LayerNorm and “invisible” directions, and token frequency neurons shift predictions toward or away from common words. These mechanisms help models be cautious when needed, which can make them safer and more reliable.
Collections
Sign up for free to add this paper to one or more collections.

