- The paper introduces IFEval, a benchmark that uses 25 verifiable instruction types to objectively evaluate LLM instruction-following.
- It employs a synthesis of few-shot prompting and manual curation, utilizing strict and loose accuracy metrics to assess compliance.
- Evaluation results reveal that GPT-4 outperforms PaLM 2, highlighting both current challenges and future directions in LLM evaluation.
Instruction-Following Evaluation for LLMs
The paper "Instruction-Following Evaluation for LLMs" (2311.07911) introduces IFEval, a benchmark evaluating the instruction-following ability of LLMs. It utilizes a set of "verifiable instructions" designed to allow objective verification. This paper provides insights into the challenges of assessing how well LLMs adhere to given instructions and proposes a novel approach based on verifiable and reproducible metrics. Here, we explore the methodology, evaluation outcomes, and considerations for future developments.
Methodology and Implementation
Verifiable Instructions
The authors devised IFEval to evaluate models using objectively verifiable instructions. They created a list of 25 specific instruction types, such as "write at least 400 words" or "mention the keyword of AI at least three times." The evaluation process involves generating numerous prompts embedding these instructions and assessing whether a model's response complies with the given directives. This setup mitigates subjectivity in evaluating the performance of LLMs.

Figure 1: Instructions such as "write at least 25 sentences" can be automatically and objectively verified. We build a set of prompts with verifiable instructions, for evaluating the instruction-following ability of LLMs.
Prompt Synthesis and Verification
The authors employed a rigorous synthesis method, combining few-shot prompting and manual curation to ensure prompt logic and diversity. Verification of compliance used both strict-accuracy and loose-accuracy metrics to accommodate nuances and edge cases in instruction adherence.
IFEval Metrics
The evaluation metrics include:
- Prompt-level Accuracy: Accuracy based on whether all instructions in a prompt are followed.
- Instruction-level Accuracy: Measures adherence on a per-instruction basis.
- Strict vs. Loose Accuracy: Strict-accuracy requires exact compliance, while loose-accuracy allows for minor deviations to handle false negatives.
Evaluation Results
Benchmarking LLMs
The evaluation showcased the proficiency of GPT-4 and PaLM 2 in following instructions. The results indicated variability in instruction adherence across different categories, with GPT-4 generally outperforming PaLM 2.
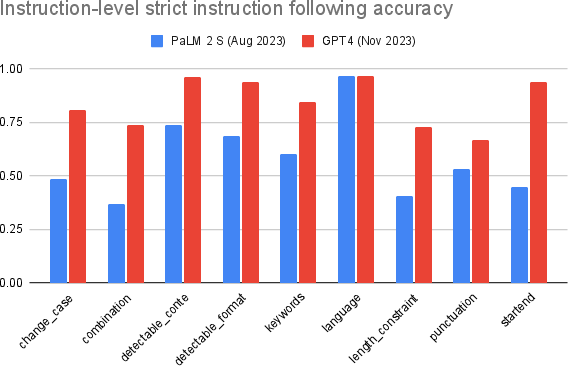
Figure 2: Instruction-level strict-accuracy of each model, separated by each instruction category.
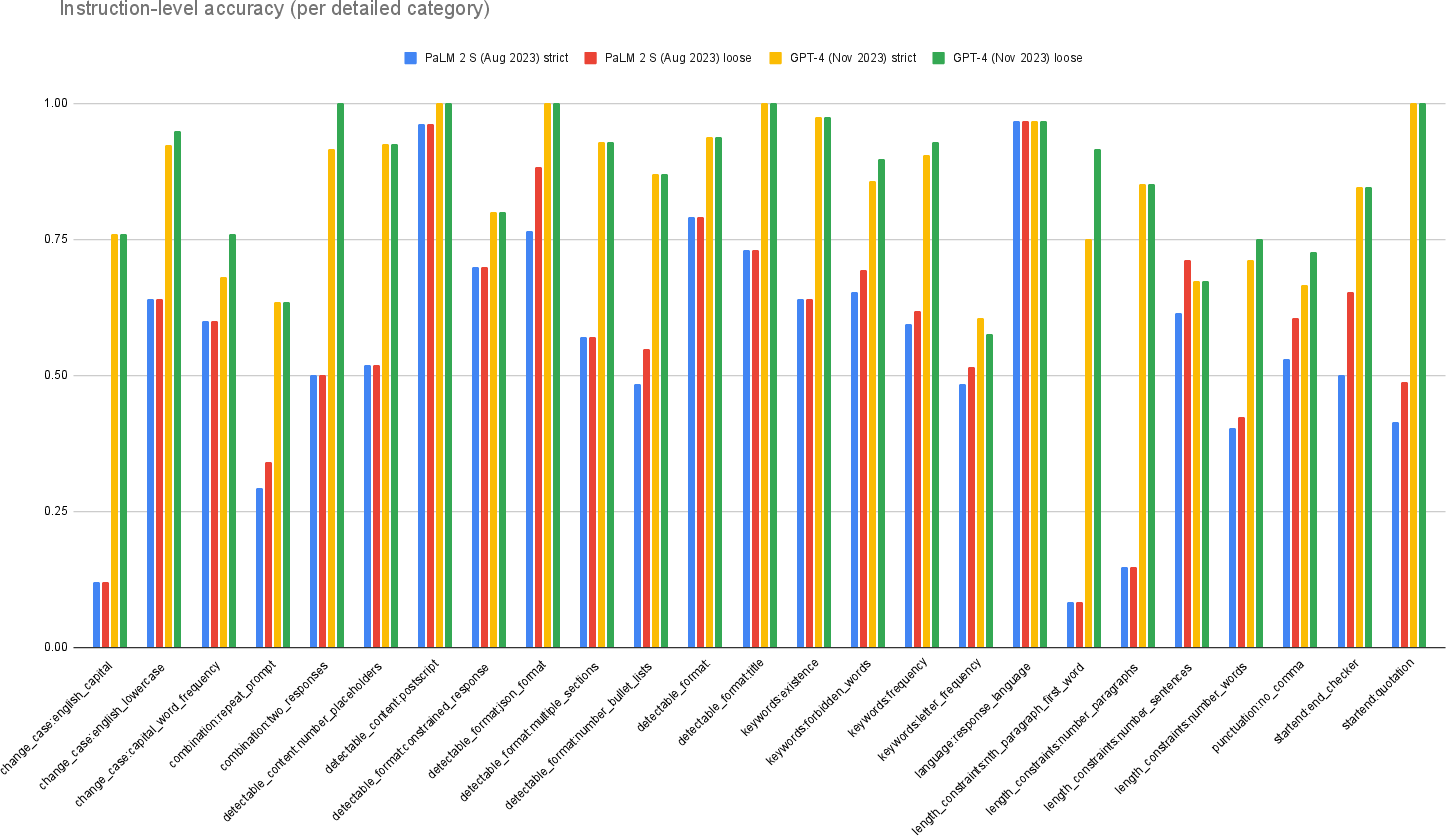
Figure 3: Instruction following accuracy per detailed category.
The results, summarized in Table \ref{tab:accuracy-summarization}, reflect the current state of LLM capabilities and highlight areas for potential improvement in understanding and following complex instructions.
Discussion and Future Directions
Challenges and Limitations
While IFEval offers a robust framework, it primarily focuses on instructions that are easily verifiable. The authors acknowledge that real-world applications often involve more complex, less objectively verifiable instructions. Extending IFEval to include such nuances poses a future challenge.
Expanding the Framework
Suggested future work involves:
- Diversity Enhancement: Expanding the range of verifiable instructions and incorporating complex real-world scenarios.
- Multi-modal Extensions: Incorporating multi-modal evaluation capabilities, like generating captions for images or video.
By evolving the benchmark, IFEval can provide a comprehensive tool for future LLM development and evaluation.
Conclusion
The introduction of IFEval marks an important step toward standardized evaluation of instruction following by LLMs. Through its verifiable methodology, the benchmark addresses key challenges and offers a foundation for more comprehensive, automatic, and objective evaluation processes. The paper’s contributions pave the way for enhancing LLM instruction-following capabilities, crucial for their deployment in sensitive domains where precision and reliability are paramount.