- The paper demonstrates that smaller learning rates in domain-specific SFT preserve general reasoning and task performance, even on challenging datasets.
- The study introduces TALR, a token-adaptive loss reweighting method that outperforms conventional mitigations by adaptively managing token-level gradients.
- Through an information-theoretic framework, the research quantifies how controlled SFT strategies reduce general capability degradation while maintaining domain-specific gains.
Revisiting the Impact of Domain-Specific SFT on LLM General Capabilities
Introduction and Context
Supervised Fine-Tuning (SFT) on domain-specific datasets is a prevalent strategy to adapt LLMs for specialized applications. Conventional wisdom—and prior empirical evidence—asserted a trade-off: fine-tuning for narrow domains often impairs the LLM's general reasoning, coding, and instruction-following abilities. This paper "SFT Doesn't Always Hurt General Capabilities: Revisiting Domain-Specific Fine-Tuning in LLMs" (2509.20758) presents a systematic reevaluation of this phenomenon, combining empirical experiments, theoretical analysis grounded in information theory, and the proposal of a principled mitigation method, Token-Adaptive Loss Reweighting (TALR).
Empirical Analysis: Learning Rate as a Critical Determinant
A central claim supported by strong quantitative evidence is that smaller learning rates during SFT can substantially mitigate general capability degradation, while still yielding robust performance improvements in the target domain. The authors demonstrate this effect across challenging medical (MedCalc) and e-commerce (ESCI) datasets, utilizing several open-source LLM families.
For instance, when fine-tuning with learning rates as low as 1×10−6, both domain accuracy and average general benchmark scores (e.g., GSM8K, HumanEval, IFEval) remain high.
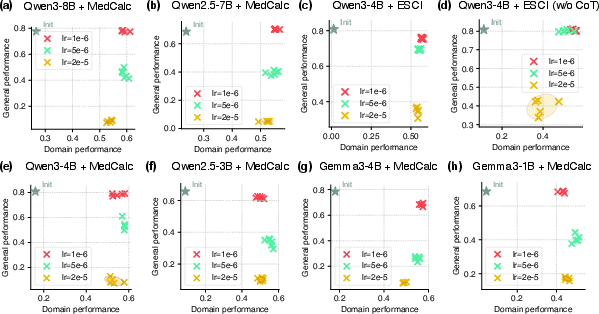
Figure 1: Smaller learning rates preserve general capabilities while attaining high domain-specific accuracy, with results illustrated for MedCalc and ESCI under different SFT variants.
Furthermore, label-only SFT broadens the Pareto-optimal learning rate range: when models are fine-tuned to generate only the final label (rather than detailed reasoning steps), they tolerate larger learning rates without substantially sacrificing general capabilities.
The authors anchor their observations in a formal information-theoretic analysis, leveraging the equivalence between language modeling and lossless data compression. They introduce the notion of expected code length as a proxy for LLM modeling quality, connecting shifts in code length under SFT to changes in KL divergence between datasets and model distributions.
The key theoretical result asserts: for a fixed target-domain performance gain, general capability degradation is upper-bounded by a function that decreases monotonically with smaller per-step updates (i.e., lower effective learning rates). The analysis further shows that the safe range of learning rates depends inversely on the concentration of "hard tokens"—those with low probability under the pretrained LLM; label-only supervision, by reducing the number of hard tokens per sample, expands this range.
Mitigation Strategies: TALR and Comparative Evaluation
Acknowledging that small learning rates do not universally eliminate general capability degradation—especially for harder domains or requirements for aggressive adaptation—the authors benchmark a suite of mitigation strategies: L2 regularization, LoRA, model averaging, FLOW, and the newly proposed TALR.
TALR dynamically reweights token-level losses in proportion to their predicted probability, adaptively suppressing the gradient contributions of tokens the model is uncertain about. This mechanism is formalized as a constrained entropy-regularized minimization yielding closed-form weights: wi∝pθ(xi)1/τ, with τ adapting per batch.
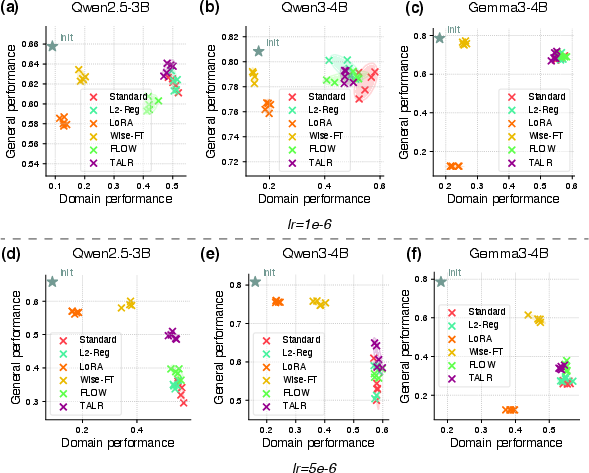
Figure 2: TALR achieves the most favorable trade-off, especially under larger learning rates, maintaining domain performance and minimizing general capability loss compared to baseline mitigations.
With larger learning rates, TALR distinctly outperforms alternatives, consistently pushing the Pareto frontier upward in both domain and general capabilities. However, no method—including TALR—fully eliminates degradation under highly aggressive fine-tuning, highlighting the limitations and open challenges of current approaches.
Token-Level Analysis and Curriculum Dynamics
A fine-grained inspection of token probabilities during SFT reveals that most supervised tokens are easy for pretrained LLMs; hard tokens are sparse and correspond to genuine domain knowledge or stylistic idiosyncrasies. TALR induces an implicit curriculum: early training emphasizes easy tokens, gradually increasing attention to harder tokens as their predicted probabilities improve.
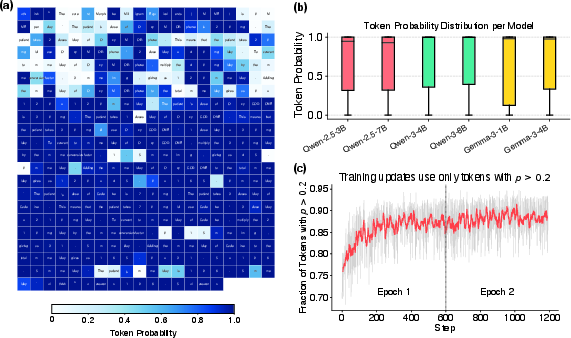
Figure 3: Visualization of token-level probabilities in MedCalc; hard tokens are infrequent and domain-specific, and the curriculum phenomenon in TALR increases model focus on hard tokens as training progresses.
Practical Guidelines and Broader Implications
From both empirical and theoretical perspectives, the following recommendations for practitioners emerge:
- Prefer small learning rates for domain-specific SFT to maximize general capability preservation.
- Utilize TALR when additional balance between adaptation and generalization is needed, especially for domains where standard SFT remains disruptive.
- Recognize that methods like KL regularization or LoRA provide limited improvements relative to careful learning rate selection and token-level adaptive strategies.
Practically, these insights are particularly relevant for high-stakes domains such as healthcare, where excessive domain adaptation can erase valuable general reasoning skills, and for RL-based training setups where pre-SFT diversity aids exploration.
Conclusion
This study overturns the presumption that domain-specific SFT inevitably harms LLM generalization, showing that aggressive learning rates—not SFT itself—drive capability loss. The theoretical framework offers quantitative bounds and mechanistic understanding, while TALR emerges as an effective mitigation, though not a complete solution. The identification of token-level curriculum and the centrality of hard tokens point to promising directions for more sophisticated continual learning algorithms.
Future work is warranted to equip LLMs with even greater robustness, clarity on learning rate selection, and scalability to larger architectures and mixture-of-experts models. The framework and findings herein set a foundation for more principled, context-sensitive adaptation of LLMs across diverse domains.

