One-Token Rollout: Guiding Supervised Fine-Tuning of LLMs with Policy Gradient
Published 30 Sep 2025 in cs.CL | (2509.26313v1)
Abstract: Supervised fine-tuning (SFT) is the predominant method for adapting LLMs, yet it often struggles with generalization compared to reinforcement learning (RL). In this work, we posit that this performance disparity stems not just from the loss function, but from a more fundamental difference: SFT learns from a fixed, pre-collected dataset, whereas RL utilizes on-policy data sampled from the current policy. Building on this hypothesis, we introduce one-token rollout (OTR), a novel fine-tuning algorithm that guides SFT with the policy gradient method. OTR reframes the autoregressive learning process by treating each token generation as a single-step reinforcement learning trajectory. At each step, it performs a Monte Carlo ``rollout'' by sampling multiple candidate tokens from the current policy's distribution. The ground-truth token from the supervised data is then used to provide a reward signal to these samples. Guided by policy gradient, our algorithm repurposes static, off-policy supervised data into a dynamic, on-policy signal at the token level, capturing the generalization benefits of on-policy learning while bypassing the costly overhead of full sentence generation. Through extensive experiments on a diverse suite of challenging benchmarks spanning mathematical reasoning, code generation, and general domain reasoning, we demonstrate that OTR consistently outperforms standard SFT. Our findings establish OTR as a powerful and practical alternative for fine-tuning LLMs and provide compelling evidence that the on-policy nature of data is a critical driver of generalization, offering a promising new direction for fine-tuning LLMs.
The paper introduces One-Token Rollout, a token-level policy gradient method that bridges supervised fine-tuning and reinforcement learning to enhance LLM generalization.
It employs token-level sampling with a negative reward for incorrect tokens, which stabilizes training and reduces perplexity compared to conventional SFT.
Empirical evaluations across math, code, and reasoning benchmarks demonstrate improved performance, reduced catastrophic forgetting, and effective knowledge retention.
One-Token Rollout: A Policy Gradient Approach to Token-Level On-Policy Fine-Tuning of LLMs
Motivation and Theoretical Foundations
The paper introduces One-Token Rollout (OTR), a fine-tuning algorithm for LLMs that leverages policy gradient methods at the token level to address the generalization gap between supervised fine-tuning (SFT) and reinforcement learning (RL). SFT, while efficient and widely adopted, is fundamentally off-policy, relying on static expert demonstrations. In contrast, RL methods utilize on-policy data, which has been shown to yield superior generalization and better preservation of pre-trained knowledge, particularly in low-probability regions of the model's output space.
OTR is motivated by the hypothesis that the generalization disparity between SFT and RL is primarily due to the nature of the training data—static versus dynamic—rather than the loss function itself. By reframing each token generation as a single-step RL trajectory, OTR simulates on-policy learning within the SFT framework, thereby capturing the generalization benefits of RL without incurring the computational cost of full sequence rollouts.
Algorithmic Design and Implementation
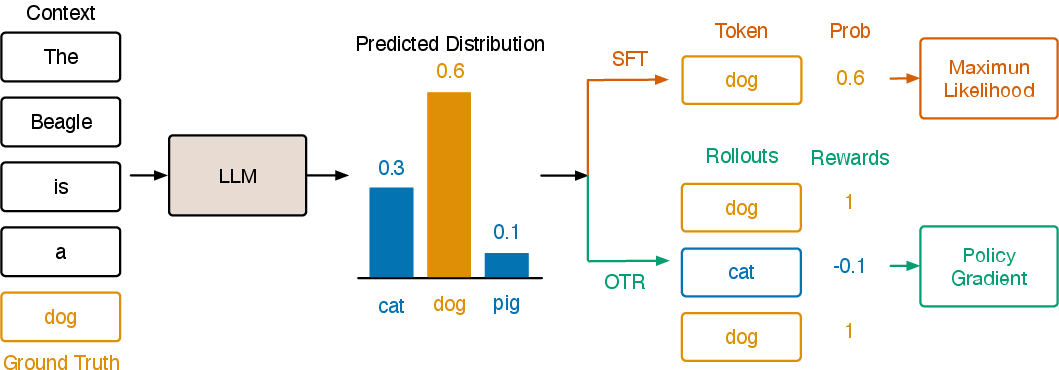
OTR operationalizes policy gradient at the token level. For each token position t in a training sequence, the algorithm samples K candidate tokens from the current policy πθ using a temperature-scaled softmax to encourage exploration. Each sampled token at,j′ is assigned a reward: $1$ if it matches the ground-truth token xt, and β (typically negative) otherwise. The per-token loss is then computed as:
where Ngt is the number of times the ground-truth token is sampled. This loss is averaged over all tokens in the sequence. The use of a negative β penalizes the model for assigning high probability to incorrect tokens, functioning as a regularizer that improves generalization and stability.
Figure 1: An illustration of the computational divergence between SFT and OTR, highlighting OTR's token-level on-policy sampling and reward assignment.
OTR is implemented efficiently: it requires only token-level sampling and reward computation, avoiding the need for full sequence generation or complex off-policy corrections. The algorithm is compatible with standard LLM training frameworks and can be integrated with minimal changes to the data pipeline.
Empirical Evaluation
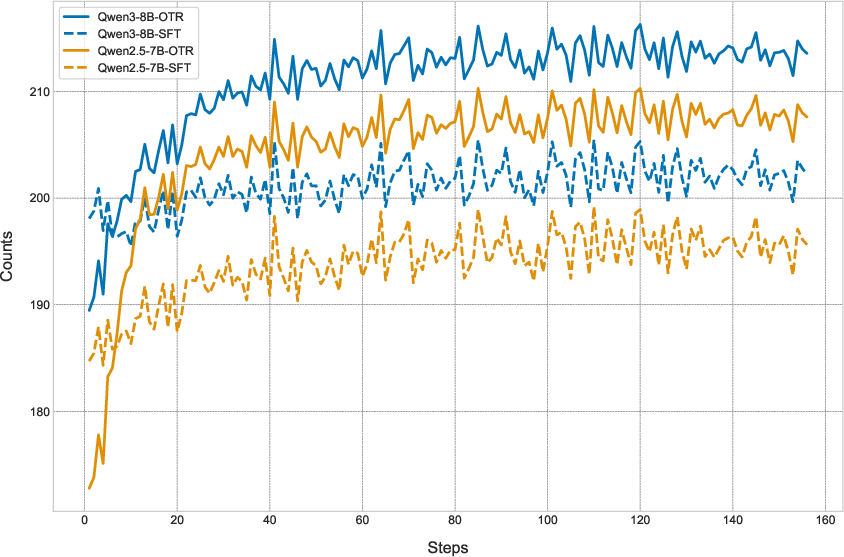
Experiments are conducted on mathematical reasoning (OpenR1-Math-220k, NuminaMath-1.5), code generation (HumanEval+, MBPP+), and general reasoning (MMLU-Pro, SuperGPQA, BBEH) benchmarks using Qwen2.5 and Qwen3 model families (3B–8B parameters). OTR consistently outperforms SFT across all domains and model sizes, both in-domain and out-of-domain.
Key findings include:
In mathematical reasoning, OTR yields higher average scores than SFT for all tested models. It also demonstrates reduced catastrophic forgetting, with fewer instances of performance degradation below the base model.
In code and general reasoning tasks, OTR achieves superior average performance, indicating improved transferability and generalization.
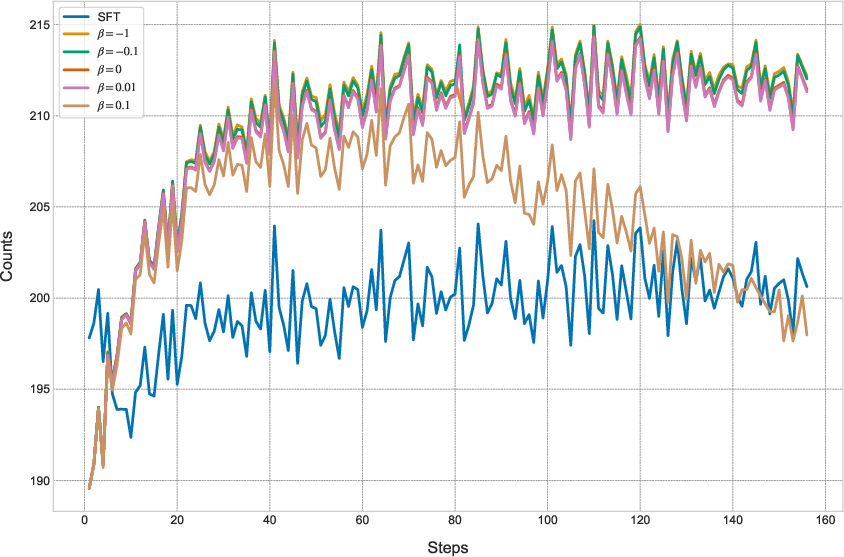
Ablation studies on the reward hyperparameter β show that negative values (e.g., β=−0.1) provide optimal stability and performance. Assigning positive rewards to incorrect tokens leads to training instability and degraded model distributions.
Figure 2: Effect of β on GT token counts, demonstrating the impact of reward regularization on training stability and generalization.
OTR also converges to higher ground-truth token sampling rates than SFT, indicating lower perplexity and more effective utilization of training data.
Comparison to Related Methods
OTR generalizes the dynamic fine-tuning (DFT) approach, which reweights the SFT loss for ground-truth tokens by their model probability. When β=0, OTR reduces to a Monte Carlo approximation of DFT. However, OTR's explicit penalization of incorrect tokens (β<0) yields superior empirical results, underscoring the importance of negative sampling in fine-tuning objectives.
OTR is distinct from prior RL-based fine-tuning methods (e.g., PPO, GRPO, DPO, GPG) in its computational efficiency and simplicity. It avoids the instability and complexity of full trajectory RL, while still capturing the essential benefits of on-policy learning.
Practical Implications and Future Directions
OTR provides a practical, scalable alternative to SFT for fine-tuning LLMs, with clear advantages in generalization, knowledge preservation, and computational efficiency. Its token-level design makes it suitable for large-scale training and easy integration into existing pipelines.
Potential future developments include:
Scaling OTR to larger models (e.g., 70B+ parameters) and broader datasets.
Extending the framework to multi-token rollouts and more sophisticated reward functions.
Adapting OTR to multimodal domains (e.g., vision-language tasks).
Investigating theoretical properties of token-level on-policy learning and its impact on model calibration and robustness.
Conclusion
One-Token Rollout bridges the gap between SFT and RL by simulating on-policy learning at the token level, yielding consistent improvements in generalization and knowledge retention across diverse LLM benchmarks. The approach demonstrates that dynamic, on-policy data is a critical driver of fine-tuning efficacy, and establishes OTR as a robust, efficient, and theoretically grounded alternative to standard SFT for LLM adaptation.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.