- The paper identifies token merging and structural memorization as key mechanisms for effective graph reasoning in decoder-only Transformers.
- The circuit tracing methodology visualizes information flow through transformer layers, enhancing understanding of path reasoning and pattern extraction.
- Quantitative evaluations demonstrate that deeper layer processing boosts token merging accuracy in complex, high-density graph scenarios.
Introduction
The study aims to elucidate the internal mechanisms of decoder-only Transformers used in graph reasoning tasks through a novel approach called circuit tracing. This research identifies two pivotal processes—token merging and structural memorization—critical for graph reasoning tasks like path reasoning and pattern extraction. These concepts are systematically analyzed and visualized to present a unified interpretability framework, providing insights into how these models execute reasoning tasks over graph structures.
Circuit Tracing Methodology
Circuit tracing is employed as an interpretability framework to map how information propagates through transformer layers, revealing underlying reasoning mechanisms. The primary advantage of circuit tracing in this context is its ability to expose latent structures used by the model, which are pivotal for tasks requiring structural understanding, thereby offering a clearer comprehension of how models make predictions.
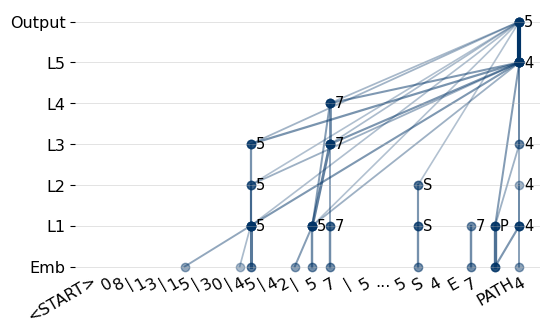
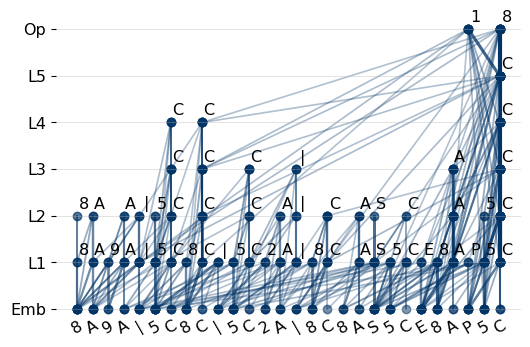
Figure 1: Circuit tracer in the path reasoning task. "L" denotes the layers. The predicted path is 4 → 5 → 7, with the model currently predicting token 5.
In applying circuit tracing to path reasoning tasks, as illustrated in Figure 1, the process involves predicting node sequences based on encoded patterns. It highlights how the model utilizes previous predictions to infer subsequent nodes through a structured path identification process.
Experimental Setup and Analysis
The experiments utilize synthetic graph datasets to train transformers tasked with three graph reasoning tasks: path reasoning, attributed graph reasoning, and pattern extraction. A detailed visualization-based analysis demonstrates how Transformer architectures systematically exhibit token merging and structural memorization.
Token Merging
Token merging is identified as a foundational process across graph tasks. It involves coalescing nodes into relevant substructures that contribute prominently to the prediction task.
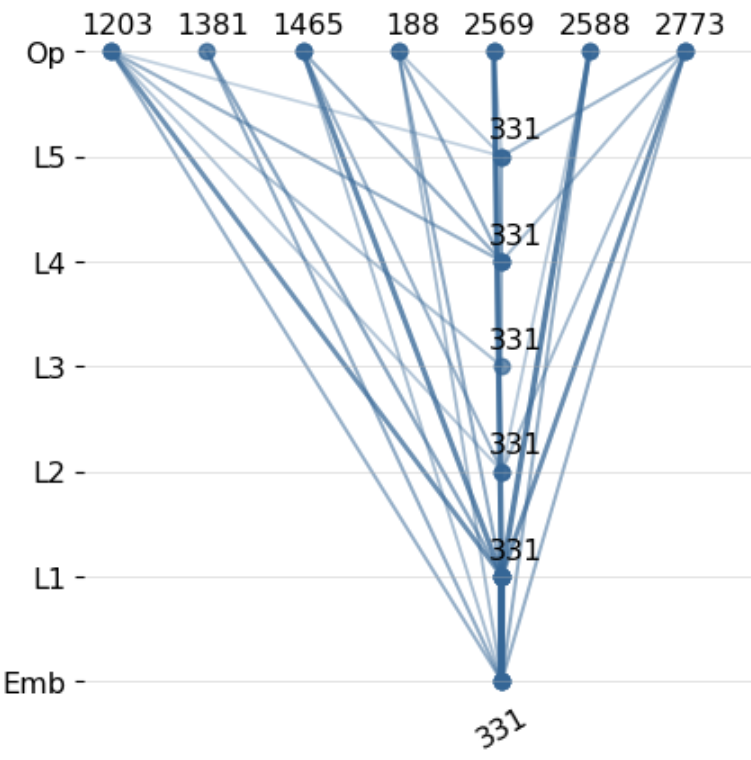
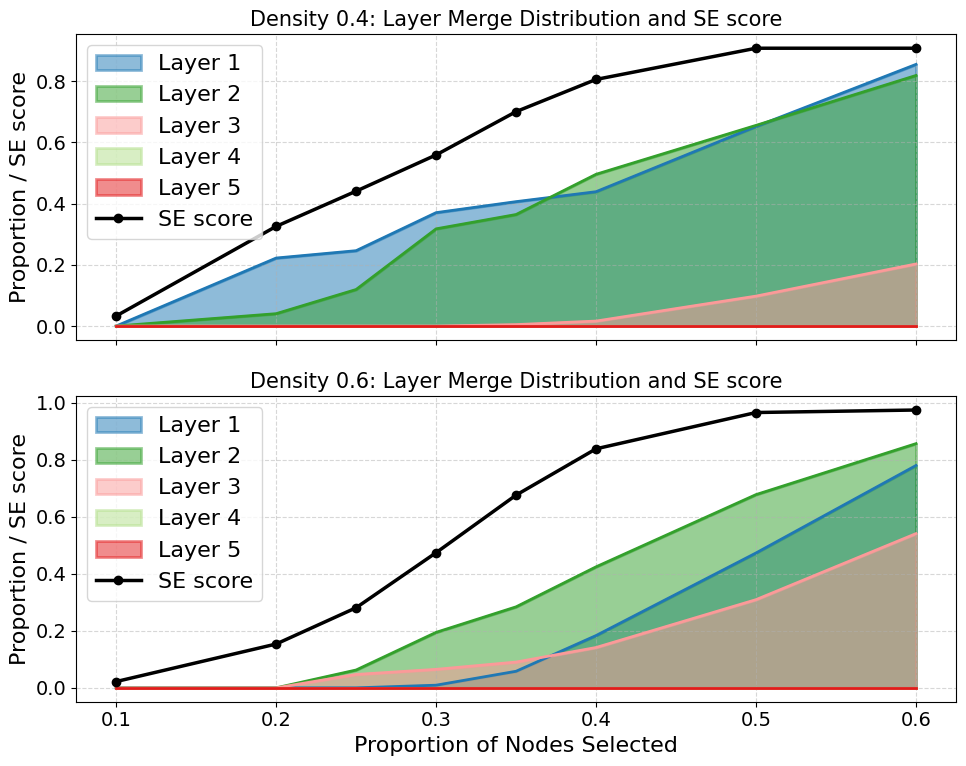
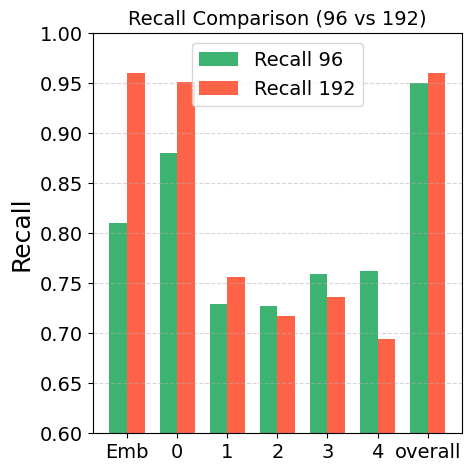
Figure 2: Circuit tracer reveals structural memorization: different layers store information about the 1-hop neighbors of node 331.
For instance, path reasoning visualizations show merged tokens across different transformer layers. Figure 2 demonstrates how specific nodes are merged coherently, providing evidence of structural memorization, where the model retains information on neighbors across 1-hop connections.
Structural Memorization
This refers to the capability of models to recall and utilize structural patterns derived from training data during inference. Analysis indicates diverse memorization dynamics through layers, with different layers contributing variably to retaining structural details, as observed in structural tasks and path predictions.
Quantitative Evaluation
Extensive quantitative analysis was conducted, evaluating the prevalence of token merging and structural memorization across differing graph densities and model sizes. It was found that higher graph densities necessitate deeper layer processing for accurate token merging, emphasizing the model’s adaptability to task complexity.
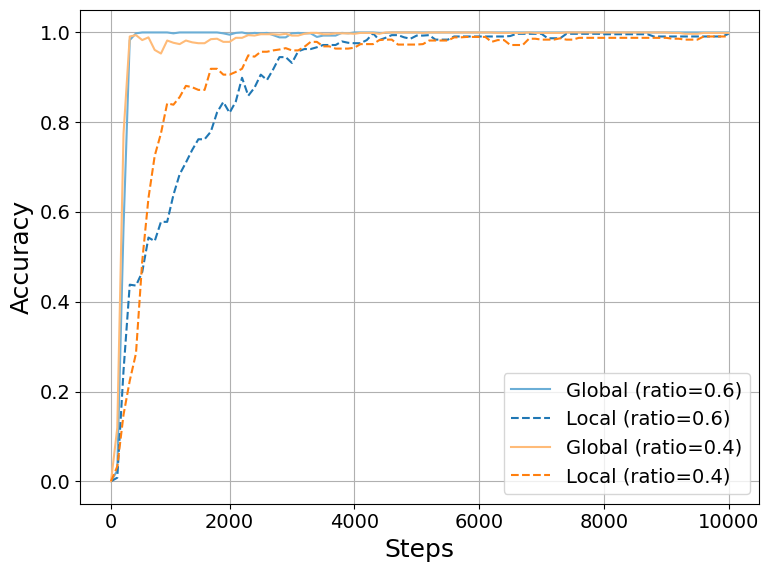
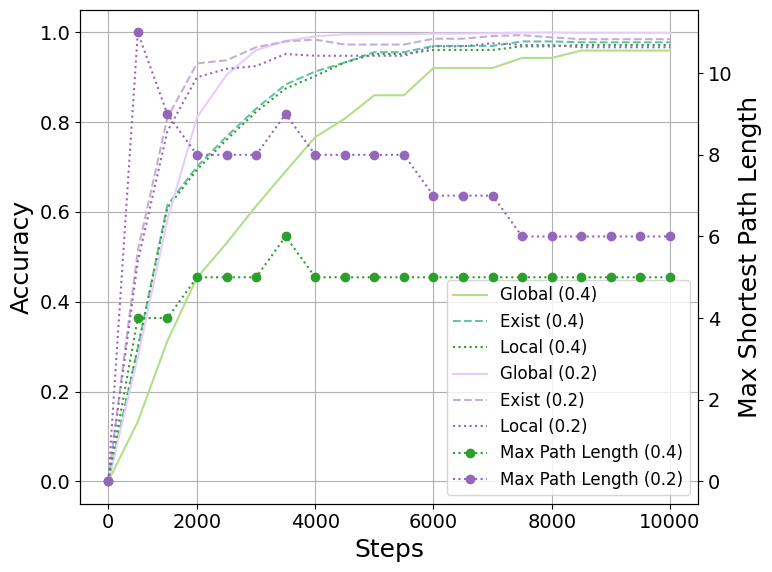
Figure 3: Local Acc and Global Acc change with training steps
Figure 3 presents the training dynamics, showcasing how local and global accuracy fluctuates throughout the training process, indicative of the model’s progressive learning abilities focused on structural context assimilation.
Implications and Future Directions
The study's frameworks and methodologies extend the understanding of how decoder-only Transformers can be refined for graph reasoning tasks. The identified mechanisms—token merging and structural memorization—present pathways for enhancing model interpretability, potentially influencing advancements in structured prediction tasks and enhanced interpretability across varied AI applications.
Future work can explore extending these tracer methods to larger, real-world LLMs and integrating these findings with more complex tasks beyond current graph reasoning paradigms.
Conclusion
This paper offers a unified interpretability framework focusing on circuit tracing to unravel decoder-only Transformers' internal mechanisms for graph reasoning tasks. Through visualization and quantitative assessments, it identifies and elaborates on the core processes of token merging and structural memorization, providing foundational insights into model interpretability, which are valuable in refining AI models for structured data understanding.
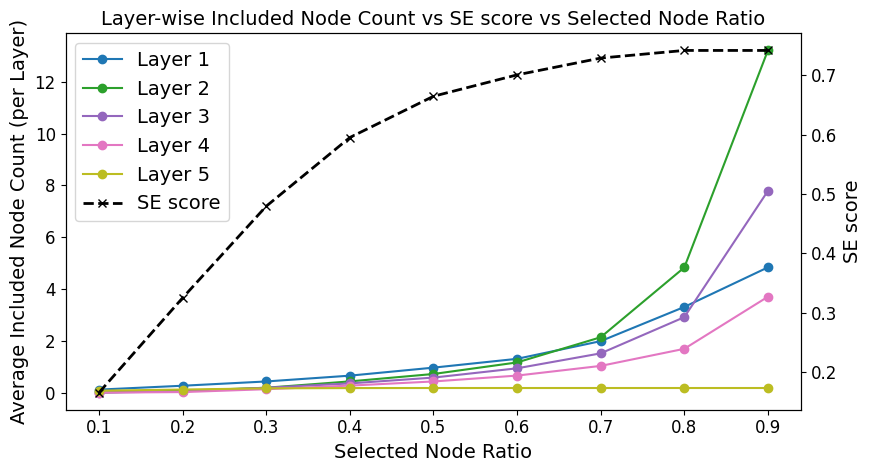
Figure 4: Pattern learned across layers. The counting demonstrates the number of tokens merged across the layers. The token merging never shows in layer 4 and layer Output.
Overall, this research significantly contributes to understandings of transformer internal dynamics and paves the way for future innovations in model interpretation and enhancement strategies.