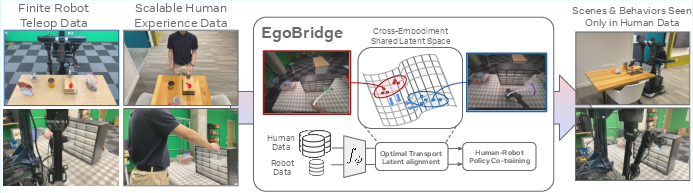
EgoBridge: Domain Adaptation for Generalizable Imitation from Egocentric Human Data
Abstract: Egocentric human experience data presents a vast resource for scaling up end-to-end imitation learning for robotic manipulation. However, significant domain gaps in visual appearance, sensor modalities, and kinematics between human and robot impede knowledge transfer. This paper presents EgoBridge, a unified co-training framework that explicitly aligns the policy latent spaces between human and robot data using domain adaptation. Through a measure of discrepancy on the joint policy latent features and actions based on Optimal Transport (OT), we learn observation representations that not only align between the human and robot domain but also preserve the action-relevant information critical for policy learning. EgoBridge achieves a significant absolute policy success rate improvement by 44% over human-augmented cross-embodiment baselines in three real-world single-arm and bimanual manipulation tasks. EgoBridge also generalizes to new objects, scenes, and tasks seen only in human data, where baselines fail entirely. Videos and additional information can be found at https://ego-bridge.github.io





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to do hands-on tasks (like scooping coffee, opening drawers, or folding laundry) by learning from videos and motion data recorded from a human’s point of view (for example, using smart glasses). The main idea is a new method called EgoBridge, which helps robots “understand” and use human demonstrations even though humans and robots look different, move differently, and have different cameras and sensors.
What problem are they trying to solve?
Collecting robot training data is slow and expensive. But collecting human data is easy—people can wear glasses and record how they do things in everyday life. The big challenge is that robots aren’t humans:
- They have different bodies (kinematics) and move differently.
- Their cameras and sensors may see the world differently.
- Even when doing the same task, humans and robots can be faster or slower.
So the question is: How can a robot learn directly from human data and still do the right actions?
Key questions in simple terms
- Can robots learn better if we combine robot data with lots of human demonstrations?
- How can we “translate” human actions into robot actions so they match in meaning, even if they look different?
- Can robots perform tasks and motion patterns that only appear in human data (and never in the robot’s own training data)?
- Can this learning approach work in both simulations and real, messy environments?
How they did it (methods explained simply)
Think of the robot’s brain as having a “latent space,” a kind of secret code where it represents what it sees and decides what to do. EgoBridge teaches the robot to make this secret code for human and robot data line up in meaningful ways, focusing on behaviors (actions) rather than just looks.
Here are the main ideas, explained with everyday analogies:
- Behavior Cloning (BC): This is “watch and copy.” The robot watches examples and tries to mimic the actions.
- Latent Space Alignment: Imagine human and robot data are two sets of puzzle pieces. EgoBridge learns a way to shape the pieces so they fit together based on what actions they represent, not just how they look.
- Optimal Transport (OT): Picture moving sand from one pile (human data) to another pile (robot data) so they match as closely as possible, but with the least effort. OT finds the best way to pair up human and robot examples to minimize mismatch.
- Dynamic Time Warping (DTW): Humans and robots can do the same task at different speeds. DTW is like stretching or shrinking timelines so the robot can align a faster human motion with a slower robot motion. It helps find “which human move is most similar to this robot move,” even if one happens quicker.
- Joint Alignment (actions + observations): Instead of aligning just the pictures or just the actions, EgoBridge aligns the combination of “what was seen + what was done.” This keeps action-relevant information intact, making the robot’s learning more accurate.
Putting it together:
- The robot is trained with both robot and human demos.
- EgoBridge uses DTW to find human demonstrations that match robot behaviors.
- It uses OT (with a “Sinkhorn” algorithm) as a loss during training to nudge human and robot latent codes closer when their actions are similar.
- The robot’s policy is a transformer-based model (a type of neural network) that takes in images and other sensor inputs and outputs action sequences.
What they found (results)
EgoBridge was tested in both simulation and real-world tasks and compared against several strong baselines. The key outcomes:
- Better success rates in tasks the robot has seen before: EgoBridge improved task success by up to an absolute 44% over methods that also use human data but don’t align it as well.
- Generalization to new objects and scenes the robot never saw: For example, in a “Scoop Coffee” task, human data included a new target (a grinder) and a new scene. While other methods failed or dropped sharply, EgoBridge kept working (about 27% success in the new scene with the new target).
- Learning new motions only shown in human data: In a drawer task, the robot had only practiced in 3 out of 4 drawer locations, but humans recorded all 4. EgoBridge could handle the unseen drawer quadrant with about 33% success, where most baselines failed. This shows it can transfer spatial behavior learned from humans.
- Across multiple real tasks (Scoop Coffee, Drawer, Laundry folding), EgoBridge consistently beat baselines on in-distribution tasks (things the robot trained on) and out-of-distribution tasks (new objects, scenes, or motions only in human data).
In short, EgoBridge makes the robot’s “secret code” for human and robot experiences overlap in meaningful, action-focused ways, which helps it learn better and generalize further.
Why this matters
- Scales learning: Human egocentric data is cheap and abundant. If robots can learn well from it, we can scale robot training without collecting tons of robot-specific demos.
- Real-world robustness: Aligning on actions (not just looks) means robots can handle new rooms, new lighting, and new objects more reliably.
- Unlocks new skills: Robots can pick up motions and strategies that only appear in human demonstrations, speeding up skill acquisition.
Limitations and future directions
- Multi-task settings: The current pairing method (DTW on action sequences) works best when the tasks are similar and well-labeled. For many diverse tasks, the matching might be less clear.
- Future improvements: The authors suggest using language (from vision-LLMs) and foundation model features to guide alignment across many tasks without relying only on motion matching. They also aim to extend the approach to more kinds of robots and to human videos without action labels.
Takeaway
EgoBridge is like a smart translator between human and robot experiences. By matching what humans see and do to what robots see and should do—especially focusing on behavior similarities—it helps robots learn more from human videos, perform better, and handle new situations they’ve never directly practiced.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Multi-task scaling is not addressed: the approach is evaluated with separate single-task policies; it remains unclear how EgoBridge behaves when trained on many tasks simultaneously, where DTW-based pairing must disambiguate task identities and subgoal sequences.
- Dependence on labeled human actions: EgoBridge requires egocentric human demonstrations with action trajectories in a shared SE(3) space; it is unknown how the method performs with unlabeled human videos or noisy pseudo-labels (e.g., from trackers or inverse dynamics), and how to robustly integrate such signals.
- Sensor/viewpoint alignment assumption: the robot is equipped with the same egocentric camera (Project Aria) to emulate human hand-eye; the method’s effectiveness with typical robot sensor suites (e.g., different viewpoints, no head-mounted camera, multi-view setups) is untested.
- Cross-embodiment breadth: results are limited to a single robot platform (Eve) and specific human data collection; generality across diverse robot embodiments (different arm geometries, mobile bases, multi-finger hands) and multiple human subjects remains unverified.
- Action-space compatibility beyond SE(3): the method assumes a common end-effector action space; it is unclear how EgoBridge transfers when action spaces differ (joint-space policies, finger-level actions, continuous gripper force/torque) or for non-manipulation behaviors.
- DTW formulation and trajectory lengths: the paper presents DTW assuming identical sequence lengths; handling variable-length, partial, or noisy trajectories and subtask reordering (e.g., different temporal decompositions of the same task) is not examined.
- Robustness to incorrect pseudo-pairs: the DTW-based soft supervision may form erroneous pairings; there is no mechanism for estimating pairing confidence or mitigating harmful couplings (e.g., via partial OT, thresholding, or robust weighting).
- Computational scalability: joint OT with DTW incurs O(B2) pairwise costs per minibatch; training-time compute/memory budgets, throughput limits, and approximations (e.g., low-rank OT, sliced OT, pruning) were not reported.
- Hyperparameter sensitivity is not analyzed: the method’s performance dependence on OT weight α, Sinkhorn regularization ε, DTW discount λ, batch size, and token design (M context tokens, L token counts) is unknown.
- Placement of the OT loss: OT is applied only to learnable context tokens from the encoder; comparisons with applying OT to all latent tokens, cross-modal tokens, or action-conditional latents are missing.
- Cross-modal alignment: wrist-camera inputs are robot-only and handled with separate stems; principled alignment across modalities (e.g., cross-modal contrastive learning, shared multimodal encoders) is not explored.
- Architecture dependence: real-world experiments use a transformer policy, while simulation uses a diffusion policy; the method’s robustness across other policy backbones (e.g., VLA architectures, CNN/LSTM baselines) is not systematically studied.
- Baseline comparability and tuning: details on baseline hyperparameters, training budgets, and tuning strategy are insufficient to assess fairness; significance testing for success rate differences is not provided.
- Breadth of generalization: object/scene generalization is evaluated primarily on a new grinder and scene; a broader stress-test across many objects, backgrounds, lighting conditions, and occlusions is missing.
- Behavior generalization remains modest: success on robot-unseen drawers is 33%; failure mode analyses (which stages fail and why) and targeted remedies (e.g., subgoal conditioning, curriculum) are absent.
- Theoretical guarantees: there is no analysis linking joint OT alignment to improved conditional action distributions or bounds on negative transfer; a formal treatment of when joint OT improves versus harms policy learning is open.
- Training stability and convergence: learning curves, variance across seeds, and signs of instability or collapse when alignment and BC losses compete have not been reported.
- Semi-/unsupervised DA settings: the approach assumes labeled source and target; performance under semi-supervised or unsupervised target conditions (limited robot labels) is unknown.
- Language and semantics: while suggested as future work, the paper does not integrate language/task embeddings to guide alignment; it is unclear how language-conditioned costs or task prompts would improve multi-task transfer.
- Multi-embodiment extension: alignment across more than two domains (e.g., multiple robot types and multiple human datasets) is not demonstrated; weighting and conflict resolution across domains are open design questions.
- Continual/online adaptation: EgoBridge is trained offline; adapting on-robot to new human data, handling non-stationarity, and avoiding catastrophic forgetting in continual settings remain unexplored.
- Inference-time performance: real-time constraints, latency, and resource usage during deployment (with transformer decoders and multi-modal inputs) are not quantified.
- Data imbalance: the impact of human–robot dataset size imbalance and sampling strategies (e.g., curriculum schedules, domain-specific sampling) on alignment and performance is not studied.
- Contact-rich tasks and force sensing: beyond laundry folding and drawering, transfer to fine-contact tasks (peg-in-hole, deformable manipulation with precise force control) and tactile sensing integration are not evaluated.
- Metric learning for latent geometry: OT cost uses Euclidean distances in latent space; learned metrics (e.g., Mahalanobis, contrastive losses) or structure-aware costs (e.g., Gromov–Wasserstein for kinematic/topological differences) are not compared.
- Partial OT and unmatched mass: the Sinkhorn formulation couples all batch samples with uniform masses; scenarios with unmatched or spurious samples (needing partial OT or unbalanced OT) are not considered.
- Retargeting quality and calibration: the method relies on egocentric frame construction and motion retargeting from human to robot; quantitative analyses of retargeting errors and their impact on pairing and policy outcomes are missing.
- Trajectory chunking and horizon: the choice of action chunk length, its effect on temporal consistency, and how horizon interacts with OT alignment are not ablated.
- Latent alignment metrics: TSNE visualizations and Wasserstein distances are suggestive but limited; stronger, task-relevant alignment diagnostics (e.g., CKA, CMI between latent and action, retrieval accuracy under known correspondences) would make claims more rigorous.
Practical Applications
Practical Applications of EgoBridge
EgoBridge aligns human and robot experiences by co-training on egocentric human demonstrations and limited robot data, using Optimal Transport with DTW-guided pseudo-pairing to preserve action-relevant information. This enables robots to leverage cheap, scalable wearable data for manipulation, generalize to new objects/scenes, and transfer motions only demonstrated by humans.
Below are actionable applications grouped by time horizon. Each item includes sector links, what to do, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
These can be piloted or deployed now with modest engineering, using existing wearables, robot stacks, and training infrastructure.
- Generalizable robot skill learning from worker-worn cameras
- Sectors: manufacturing, logistics/warehousing, retail operations
- What to do: Capture egocentric video and hand pose (or SE(3) end-effector proxy) from employees doing target tasks (e.g., opening/closing drawers, restocking, bin sorting). Co-train with a small set of teleoperated robot demos to deploy policies that generalize across layouts and objects seen only in human data.
- Tools/workflows: Smart glasses data pipeline (e.g., Project Aria-like capture), action-space retargeting to robot EE pose, EgoBridge training module (OT+DTW), safety validation harness (e.g., stage-by-stage success metrics, watchdogs).
- Assumptions/dependencies: Consent and privacy handling for egocentric data; availability of human action labels or proxy signals; roughly aligned egocentric viewpoint on the robot (head/wrist camera placement); modest robot data for co-training.
- Cross-site and cross-scene adaptation without robot recollection
- Sectors: retail (new stores), quick-service restaurants, 3PL warehouses
- What to do: When expanding to a new site, collect only human egocentric demos on-site; fine-tune a pre-trained robot policy with EgoBridge instead of recollecting extensive teleop robot data.
- Tools/workflows: Site-specific human-only data ingestion; DTW-guided pseudo-pairing; periodic evaluation on a validation rig or digital twin; simple robot domain calibration (e.g., camera mount check).
- Assumptions/dependencies: Sufficient overlap in task semantics; consistent action space; environmental safety review for new site.
- Lowering teleoperation costs in robotics startups and labs
- Sectors: robotics startups, academic labs, RaaS integrators
- What to do: Replace a large fraction of robot teleop demonstrations with egocentric human data and small amounts of robot data; adopt EgoBridge as an add-on alignment loss to existing behavior cloning or diffusion policies.
- Tools/workflows: Plug-in OT-Sinkhorn + DTW alignment layer for PyTorch; integration with Diffusion Policy or VLA-based policies; metrics dashboards (success rate, Wasserstein-2 latent overlap).
- Assumptions/dependencies: Stable training infrastructure (GPU/TPU); curated human data with action trajectories; defined evaluation tasks and safety boundaries.
- Hospital service and facilities robots trained from staff headcams
- Sectors: healthcare operations (non-critical tasks), facilities management
- What to do: Use nurse/tech egocentric demos for tasks like fetching supplies from drawers/cabinets, transporting items, linen handling; co-train with a small number of robot demos on the target robot.
- Tools/workflows: Privacy-first collection (face blurring, redaction), action sequence extraction, EgoBridge co-training, validation in controlled zones before ward deployment.
- Assumptions/dependencies: Strict privacy and compliance (HIPAA/GDPR); limit to non-clinical, low-risk manipulation; alignment of camera viewpoint and action space.
- Home/service robot personalization from owner-worn smart glasses (pilot programs)
- Sectors: consumer robotics, home services
- What to do: Teach robots household routines (e.g., laundry folding variants, organizing drawers, scooping/transfer tasks) by recording human executions; co-train with limited robot data captured in the home.
- Tools/workflows: Mobile app for AR/smart-glasses capture; on-device redaction; cloud training with EgoBridge; rollback/sandboxed deployment for new skills; user-in-the-loop correction.
- Assumptions/dependencies: Early adopter users; privacy-by-design; home robot with egocentric camera mount or equivalent sensing; safety checks for confined spaces.
- Data curation and alignment QA for cross-embodiment datasets
- Sectors: robotics data platforms, MLOps
- What to do: Use DTW distances to pseudo-pair human–robot trajectories and flag outliers; monitor latent alignment (e.g., W2 distance, KNN semantic checks) to assess whether human data is helping.
- Tools/workflows: Curation scripts, latent visualization (t-SNE/UMAP), automated reports correlating alignment metrics with task success.
- Assumptions/dependencies: Synchronized or chunked action trajectories; consistent preprocessing and normalization across embodiments.
- Methodological baselines and teaching material for academia
- Sectors: academia, education
- What to do: Adopt EgoBridge as a strong baseline for cross-embodiment imitation learning; replicate on standard tasks; extend to new simulators and camera/kinematics gaps for coursework and research.
- Tools/workflows: Open-source OT-Sinkhorn and DTW modules; reproducible benchmarks (Push-T and real tasks); ablation protocols (marginal OT vs joint OT, MSE vs DTW cost).
- Assumptions/dependencies: Availability of datasets; compute resources; clear task metrics.
Long-Term Applications
These require further research, scaling, or ecosystem development (e.g., larger datasets, new supervision signals, standardized privacy frameworks).
- Foundation-scale cross-embodiment robotics models trained from massive egocentric corpora
- Sectors: general robotics, platform AI providers
- What to do: Train multi-task VLA+policy models primarily on egocentric human data at scale (millions of hours), aligned with small but diverse robot datasets via joint OT; enable broad generalization to new scenes/objects/motions.
- Tools/workflows: Web-scale data ingestion; automated action labeling (e.g., pose estimation, point tracking, inverse dynamics); scalable OT computation; distributed training; continuous evaluation.
- Assumptions/dependencies: Scalable, privacy-safe data pipelines; robust retargeting across embodiments; compute-efficient OT/DTW approximations; multi-task alignment beyond DTW (e.g., language-conditioned costs).
- Skill marketplaces and cloud “train-from-your-day” services
- Sectors: consumer and enterprise robotics
- What to do: Allow users or organizations to contribute egocentric logs to teach robots new skills or variants; distribute validated skills across fleets with domain adaptation to each site/robot.
- Tools/workflows: Cloud training service with EgoBridge core; federated/secure aggregation; validation sandboxes; versioned skill catalogs; rollback and A/B testing.
- Assumptions/dependencies: Consent, licensing, and data governance; strong QA and safety certification; robust generalization guarantees; liability frameworks.
- Personalized assistive robots for eldercare and rehabilitation
- Sectors: healthcare, home care
- What to do: Learn routines from caregivers’ egocentric data (e.g., object fetching, organizing, dressing assistance steps) and adapt to diverse homes with minimal robot demos.
- Tools/workflows: Privacy-preserving capture; human-in-the-loop supervision; contextual constraints (fall-risk safeguards, force limits); adaptive user modeling.
- Assumptions/dependencies: Strict safety and regulatory approvals; fail-safe designs; interpretability and override mechanisms; bias and fairness evaluations.
- Cross-robot and multi-embodiment transfer at scale
- Sectors: robotics OEMs, integrators
- What to do: Transfer skills between different robot arms and mobile manipulators via shared latent spaces, minimizing per-platform data; enable mixed-fleet operations across vendors.
- Tools/workflows: Unified action spaces or robust retargeting; multi-embodiment OT objectives; calibration toolkits for camera/kinematics alignment; cross-platform simulators.
- Assumptions/dependencies: Standardized interfaces; reliable embodiment-agnostic representations; strong sim-to-real bridging.
- Language- and vision-guided alignment beyond DTW
- Sectors: AI research, applied ML
- What to do: Replace or augment DTW with semantic costs (e.g., language embeddings, foundation-model visual features) to align multi-task human data with robot policies, enabling instruction following and task composition.
- Tools/workflows: VLM integration; semantic trajectory descriptors; hybrid OT costs combining geometry and semantics; curriculum learning.
- Assumptions/dependencies: High-quality language annotations or automatic grounding; robustness across long-horizon tasks; mitigation of semantic drift.
- Privacy, compliance, and safety policy frameworks for egocentric-to-robot learning
- Sectors: policy/regulation, enterprise governance
- What to do: Establish standards for collection, minimization, retention, and sharing of egocentric data used to train robots; certification pipelines for cross-embodiment models; worker consent and transparency requirements.
- Tools/workflows: Data governance playbooks; on-device redaction and anonymization; audit trails; model cards documenting domain adaptation and limits; incident reporting processes.
- Assumptions/dependencies: Cross-jurisdictional legal clarity; industry consortia; third-party certification bodies.
- Edge/on-robot online adaptation
- Sectors: mobile and field robotics
- What to do: Incrementally adapt policies in new environments using small amounts of human egocentric data and a few robot rollouts, with on-robot or near-edge computation.
- Tools/workflows: Lightweight OT/DTW approximations; partial fine-tuning modules; safety monitors for online learning; resource-aware training schedulers.
- Assumptions/dependencies: Hardware acceleration; robust fallback policies; bounded-drift guarantees; careful risk management.
- Education and workforce training
- Sectors: education, vocational training
- What to do: Use egocentric recordings of expert procedures to train student-facing robots for practice tasks (e.g., lab prep, shop tasks) and to produce feedback on procedural adherence.
- Tools/workflows: Classroom-safe capture kits; simulated assessment; curriculum-aligned task libraries; explainable policy components for pedagogy.
- Assumptions/dependencies: Age-appropriate privacy practices; non-hazardous tasks; institution approvals.
Notes on Feasibility and Dependencies Across Applications
- Human action labels: The strongest gains come when human data includes action trajectories in a shared or retargetable action space; where unavailable, proxy estimation (pose, point tracking, inverse dynamics) is needed.
- Embodiment alignment: Egocentric camera placement and a shared SE(3) end-effector representation (or robust retargeting) are important to close the observation and kinematic gaps.
- Compute: Sinkhorn OT and DTW add training overhead; scalable implementations or approximations may be needed at scale or on edge.
- Multi-task scope: Current DTW-based pairing is best for single or narrow task sets; broad multi-task settings may need semantic costs (language or foundation-model features).
- Safety and compliance: Egocentric data is sensitive. Privacy-preserving capture, consent, redaction, and governance are prerequisites for most deployments.
- Evaluation: Use stage-wise success metrics, latent alignment diagnostics (e.g., Wasserstein-2), and sandboxed validation before field rollout.
Glossary
- Action tokens: Learnable transformer tokens representing future actions to be generated. "utilizing learnable action tokens and injecting context through alternating self and cross-attention blocks."
- Adversarial training: A technique that aligns distributions via a discriminator–generator objective during domain adaptation. "Standard domain adaptation approaches often rely on global distribution alignment techniques such as adversarial training~\cite{tzeng2017adversarialdiscriminativedomainadaptation}..."
- Any-Point Trajectory Modeling (ATM): A hierarchical policy using 2D point tracks for high-level planning, followed by a robot-only fine-tuned action decoder. "Any-Point Trajectory Modeling (ATM):~\cite{wen2023anypoint} A hierarchical policy where the high-level planner is initially co-trained on 2D point tracks derived from both robot and human video data."
- Behavior Cloning (BC): Supervised imitation learning that maps observations to actions from expert demonstrations. "Supervised Imitation Learning (SIL), notably Behavior Cloning, leverages expert demonstrations for policy learning..."
- Bimanual manipulation: Robotic manipulation involving two arms/end-effectors acting together. "EgoBridge achieves a significant absolute policy success rate improvement by 44\% over human-augmented cross-embodiment baselines in three real-world single-arm and bimanual manipulation tasks."
- Co-training: Jointly training a single model on multiple datasets or domains to improve transfer. "More broadly, simply co-training from cross-domain data does not automatically yield effective knowledge transfer..."
- Covariate shift: A change in the input distribution between source and target domains that can hinder transfer. "will exhibit a significant covariate shift ()."
- Cross-attention: An attention mechanism where query tokens attend to a separate set of key/value tokens. "A single multi-head cross-attention block ( heads, per-head width $d_{\text{attn}$) employs learnable query tokens..."
- Cross-embodiment: Learning across different physical embodiments (e.g., human vs. robot). "We formalize the human-robot cross-embodiment learning problem as a domain adaptation problem..."
- DETR-style architectures: Transformer-based designs inspired by DETR for end-to-end processing and decoding. "Inspired by recent cross-embodiment policy learning~\cite{wang2024hpt} and DETR-style architectures~\cite{carion2020endtoendobjectdetectiontransformers}..."
- Diffusion Policy: A policy class that uses diffusion models to generate action trajectories. "we choose a standard ResNet-UNet Diffusion Policy~\cite{chi2024diffusionpolicy}..."
- Domain Adaptation (DA): Methods that bridge distribution gaps to transfer performance from source to target domains. "Domain Adaptation (DA) aims to reduce reliance on target-specific data..."
- Domain gap: Differences (appearance, sensors, kinematics) between domains that impede transfer. "significant domain gaps in visual appearance, sensor modalities, and kinematics between human and robot impede knowledge transfer."
- Dynamic Time Warping (DTW): A technique to align and compare time series with different speeds or temporal misalignments. "we use the dynamic time warping (DTW) distance among human and robot motion trajectories to shape the OT ground cost."
- Egocentric: First-person viewpoint aligned with the agent’s perspective. "Egocentric human experience data presents a vast resource for scaling up end-to-end imitation learning for robotic manipulation."
- Egocentric coordinate frame: A coordinate system centered on the agent’s viewpoint for aligning actions and observations. "hand-eye alignment through an egocentric coordinate frame (Sec.~\ref{ssec:detail})..."
- End-effector: The robot’s tool or gripper at the end of its manipulator. "even within a shared SE(3) end-effector action space..."
- Entropic regularization: Adding an entropy term to the OT objective to make the solution convex and differentiable. "The Sinkhorn algorithm~\cite{cuturi2013sinkhorndistanceslightspeedcomputation} introduces an entropic regularization term to the OT objective..."
- Exteroceptive: Sensing external stimuli (e.g., vision) as opposed to internal states. "exteroceptive, egocentric first person POV RGB images ()..."
- Gaussian normalization: Per-dimension normalization to zero mean and unit variance. "We perform embodiment-specific gaussian normalization to the proprioception and actions."
- Ground cost: The base pairwise cost used in OT to measure dissimilarity between samples. "we use the dynamic time warping (DTW) distance ... to shape the OT ground cost."
- Hand-eye configuration: The spatial relationship between camera and manipulator for aligned perception and action. "mount it in a way that emulates the hand-eye configuration of a human adult ()."
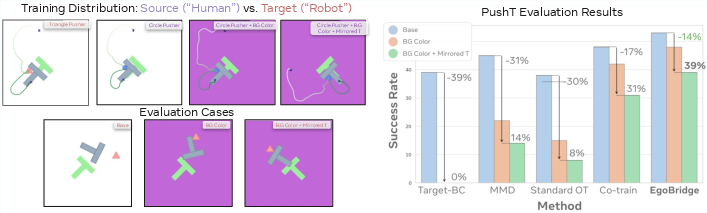
- Intersection over Union (IoU): A metric for set overlap, often used to evaluate spatial alignment. "report the mean reward (max IoU with goal) and the success rate (reward 0.9)."
- Inverse dynamics models: Models that infer actions from observed state transitions, used for pseudo-labeling in videos. "require pseudo-labeling of actions via inverse dynamics models~\cite{ye2024latentactionpretrainingvideos}..."
- Joint distribution alignment: Aligning the joint distribution of features and actions across domains. "align the joint distributions of latent policy features and corresponding actions across the human and robot domains."
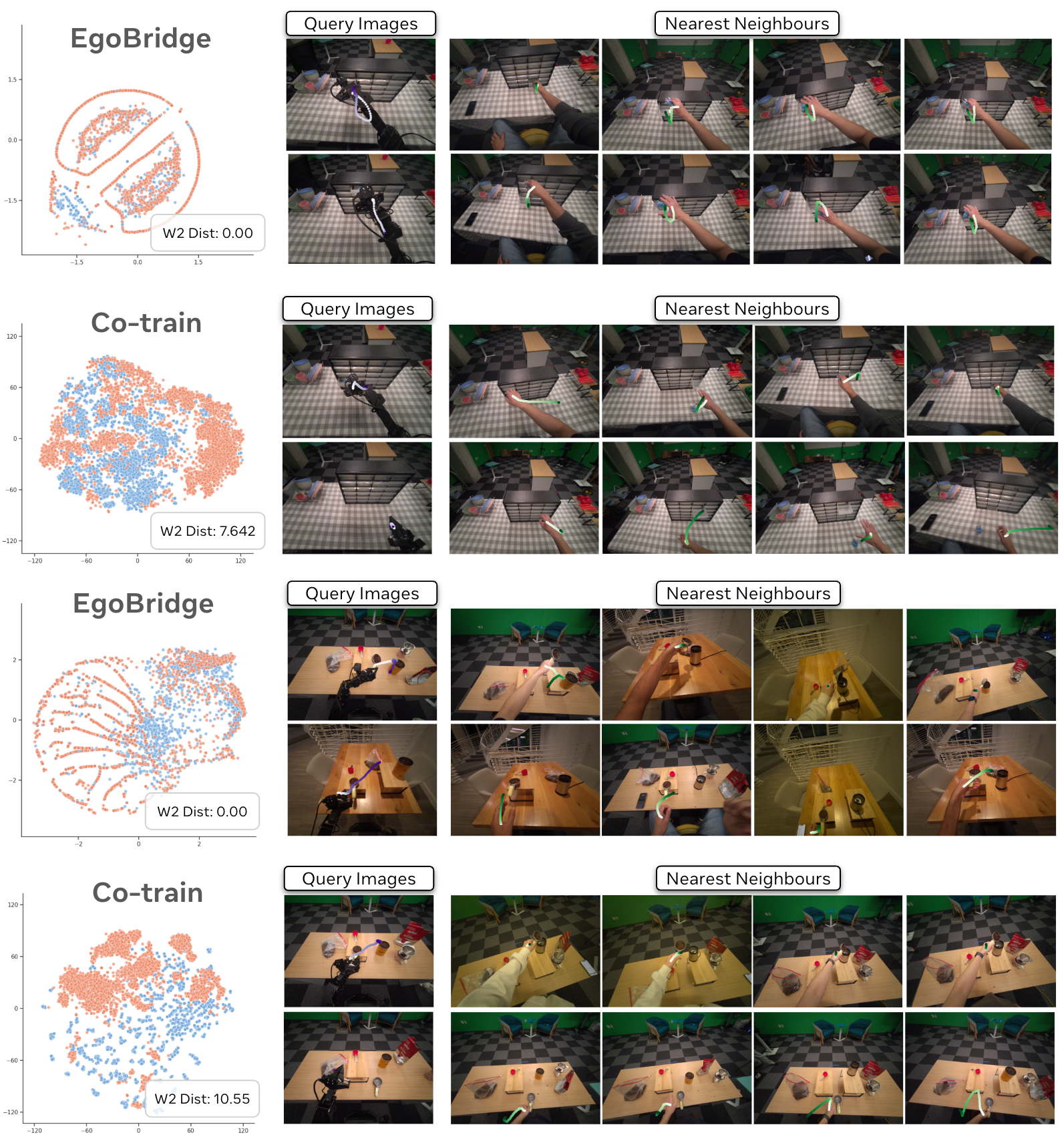
- K-nearest neighbors (KNN): A method to find closest samples in feature space for analysis or pairing. "Visualization of TSNE plots on encoded features for EgoBridge and baselines, with the mean Wasserstein-2 distance and KNN pairs of aligned human-robot data visualized."
- Kinematic differences: Differences in motion constraints or articulation between embodiments. "kinematic differences can lead to behavior distribution shifts."
- KL-divergence (KL-div): A measure of divergence between probability distributions. "in baselines like MimicPlay that aligns marginals with KL-div, the semantic similarity is lacking."
- Latent space: An embedded feature space where observations are represented for policy learning. "explicitly aligns the policy latent spaces between human and robot data using domain adaptation."
- Marginal alignment: Aligning feature distributions without conditioning on associated actions. "Standard OT, which performs marginal alignment instead of joint alignment."
- Maximum Mean Discrepancy (MMD): A kernel-based statistical distance for comparing distributions. "We choose Maximum Mean Discrepancy (MMD) ~\cite{gretton2008kernelmethodtwosampleproblem} as an alternative domain adaptation loss..."
- Observation generalization: Robust performance across changes in visual appearance or sensor modalities. "the system must achieve observation generalization."
- Optimal Transport (OT): A framework for comparing distributions by moving probability mass with minimal cost. "Optimal Transport (OT) offers a principled framework for comparing probability distributions..."
- Point tracks: Tracked 2D points across video frames used as supervision for planners. "These point tracks% are obtained via Co-tracker~\cite{karaev2023cotracker}."
- Proprioceptive: Internal sensing of body states (e.g., joint angles, poses). "proprioceptive data (), cartesian pose for both arms ."
- Pseudo-pairs: Heuristic pairings across domains used to guide alignment when true pairs are unavailable. "to form pseudo-pairs as supervision for the adaptation process."
- ResNet-UNet: A neural architecture combining a ResNet encoder with a UNet decoder. "we choose a standard ResNet-UNet Diffusion Policy~\cite{chi2024diffusionpolicy}..."
- SE(3): The group of 3D rigid transformations (rotation and translation). "cartesian pose for both arms ."
- Self-attention: Attention mechanism where tokens attend to one another within the same sequence. "injecting context through alternating self and cross-attention blocks."
- Sinkhorn algorithm: An iterative method to compute entropy-regularized OT efficiently. "The Sinkhorn algorithm~\cite{cuturi2013sinkhorndistanceslightspeedcomputation} introduces an entropic regularization term..."
- Sinkhorn distance: The differentiable OT cost obtained via the Sinkhorn algorithm. "aligns policy representations across domains via a differentiable OT loss (Sinkhorn distance),..."
- Teleoperation: Human remote control of a robot to collect demonstrations. "comprises robot experiences, typically from teleoperation..."
- Transformer decoder: The decoding component of a transformer that generates outputs conditioned on encoded features. "the policy consists of a shared multi-block transformer decoder."
- TSNE: A dimensionality reduction technique for visualizing high-dimensional embeddings. "we create a TSNE visualization of the action tokens from our transformer backbone."
- Vision-Language-Action (VLA) models: Models combining vision and language understanding with action generation. "State-of-the-art Vision-Language-Action (VLA) models~\cite{black2410pi0, rt22023arxiv, nvidia2025gr00tn1openfoundation, intelligence2025pi05visionlanguageactionmodelopenworld} integrate Vision-LLMs (VLMs) with action decoders..."
- Vision-LLMs (VLMs): Models that process and relate visual inputs with language. "integrate Vision-LLMs (VLMs) with action decoders..."
- Wasserstein-2 distance: An OT-based metric for measuring distances between probability distributions. "with the mean Wasserstein-2 distance and KNN pairs of aligned human-robot data visualized."
- Wrist cameras: Cameras mounted on or near robot wrists providing close-up visual inputs. "The robot additionally provides RGB streams from its two RealSense D405 wrist cameras, ."
Collections
Sign up for free to add this paper to one or more collections.

