ATLAS: Benchmarking and Adapting LLMs for Global Trade via Harmonized Tariff Code Classification
Abstract: Accurate classification of products under the Harmonized Tariff Schedule (HTS) is a critical bottleneck in global trade, yet it has received little attention from the machine learning community. Misclassification can halt shipments entirely, with major postal operators suspending deliveries to the U.S. due to incomplete customs documentation. We introduce the first benchmark for HTS code classification, derived from the U.S. Customs Rulings Online Search System (CROSS). Evaluating leading LLMs, we find that our fine-tuned Atlas model (LLaMA-3.3-70B) achieves 40 percent fully correct 10-digit classifications and 57.5 percent correct 6-digit classifications, improvements of 15 points over GPT-5-Thinking and 27.5 points over Gemini-2.5-Pro-Thinking. Beyond accuracy, Atlas is roughly five times cheaper than GPT-5-Thinking and eight times cheaper than Gemini-2.5-Pro-Thinking, and can be self-hosted to guarantee data privacy in high-stakes trade and compliance workflows. While Atlas sets a strong baseline, the benchmark remains highly challenging, with only 40 percent 10-digit accuracy. By releasing both dataset and model, we aim to position HTS classification as a new community benchmark task and invite future work in retrieval, reasoning, and alignment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching and testing AI LLMs to correctly assign special product codes used in global trade, called Harmonized Tariff Schedule (HTS) codes. These codes tell customs exactly what a product is so it can be taxed and allowed into a country. The authors built the first big test (a benchmark) for this task and created a specialized AI model named Atlas to do the job better, faster, and cheaper.
What problem are they trying to solve?
Every product shipped internationally needs an HTS code—like a product’s “passport number.” If the code is wrong or missing, shipments can be delayed or even stopped. The codes have 10 digits:
- The first 6 digits are the same across most countries (global part).
- The last 4 digits are country-specific (in this paper, the U.S. part).
Finding the right code is hard because the rules are long, detailed, and change over time. The paper asks: Can AI models learn to pick the correct HTS code from a product description, and can we measure how well they do it?
How did they approach the problem?
Think of it like training a smart assistant to classify products:
- They built a dataset from official U.S. Customs rulings (CROSS), which are real decisions about which HTS code a product should get. This makes the data reliable and grounded in law.
- These rulings are long and formal. The team used a smaller AI (GPT-4o-mini) to turn each ruling into a clear training example with:
- A simple product description
- The correct HTS code
- A step-by-step explanation (reasoning path) of why that code is correct
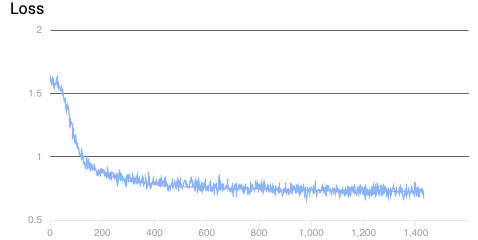
- They then fine-tuned a large open-source AI model (LLaMA-3.3-70B) using supervised fine-tuning. In everyday terms, supervised fine-tuning is like tutoring the model with many examples: show it the question (product description), the correct answer (HTS code), and the reasoning, and adjust the model so it learns to produce the right answer next time.
In short: collect trusted examples, clean and simplify them, then teach a big AI model with those examples so it becomes a specialist in tariff codes.
What did they find, and why does it matter?
They tested several top AI models and compared them to their specialized model, Atlas. They checked:
- Exact 10-digit matches (fully correct for U.S. customs)
- Correct first 6 digits (globally consistent part)
- Average number of correct digits (to see partial improvements)
Key results:
- Atlas got 40% fully correct 10-digit codes, better than GPT-5-Thinking (25%) and Gemini-2.5-Pro-Thinking (13.5%).
- Atlas got 57.5% correct at the 6-digit global level, slightly better than GPT-5-Thinking (55.5%).
- On average, Atlas got 6.3 out of 10 digits right, beating general models that got around 3–5 digits right.
- Atlas is cheaper to run and can be self-hosted, which helps companies keep sensitive data private.
Why it matters:
- More accurate codes mean fewer shipping delays and smoother customs clearance.
- Lower cost and on-premise options make it practical for businesses to use the model at scale.
- The benchmark gives the research community a clear, real-world test to improve on.
What could this change in the real world?
If models like Atlas keep improving:
- International shipping could be faster and more reliable.
- Companies could automate code assignment, reducing human workload on complex paperwork.
- Global trade systems could become more resilient, even when rules change.
The authors also share their dataset and the Atlas model so others can build on this work. They suggest future improvements like:
- Using retrieval (letting the AI look up specific rules during reasoning) to reduce mistakes on hard, niche products.
- Training smaller versions of Atlas for cheaper and easier deployment.
- Better training methods to improve reasoning and avoid near-miss errors.
Overall, this paper shows that AI can learn tough, real-world classification tasks that directly impact global trade, and it gives the community the tools to push performance even further.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Small, potentially underpowered evaluation: test set size is only n=200 with no confidence intervals or statistical significance tests; expand test size and report CIs/hypothesis tests.
- Random splits risk leakage: no temporal split or near-duplicate deduplication is described; implement time-based splits, dedup across similar rulings, and evaluate temporal generalization.
- Coverage bias of CROSS: dataset captures disputed/ambiguous cases, not routine or stable codes; quantify class imbalance, long-tail coverage, and add OOD/representative non-dispute samples.
- Label validity over time: CROSS includes modified/revoked rulings; clarify filtering and control for outdated labels; include metadata to exclude superseded rulings.
- HTS evolution and drift: no evaluation across HTS revisions (esp. Chapters 98–99); create time-sliced benchmarks and continual-learning/update strategies for post-revision robustness.
- Input realism mismatch: models are trained/evaluated on GPT-extracted product descriptions, not raw, noisy real-world inputs (e.g., short e-commerce titles, packing lists, spec sheets); benchmark on realistic inputs with varying attribute completeness.
- Synthetic preprocessing risk: GPT-4o-mini was used to extract product descriptions and reasoning, but the quality, hallucination rate, and consistency were not audited; conduct human validation with inter-annotator agreement and error typology.
- Single-label assumption: some products admit multiple valid codes conditional on context; evaluate multi-label/conditional classification and design follow-up question strategies to disambiguate.
- Missing hierarchical modeling: classification is treated as flat; explore hierarchical losses, path-consistency constraints, and hierarchical metrics beyond 6-digit match.
- Limited error metrics: all errors are treated equally; introduce cost-sensitive metrics weighted by duty-rate differences, penalty risk, and operational impact.
- Uncertainty and abstention: no calibration, confidence, or selective prediction is reported; evaluate calibration, abstain/triage policies, and human-in-the-loop thresholds for compliance-grade reliability.
- Reasoning faithfulness: chain-of-thought outputs are collected but not evaluated for factual correctness or faithfulness; design verifiability criteria, evidence-grounded scoring, and cite-to-HTS-notes requirements.
- Retrieval augmentation untested: no RAG over HTS chapters, Explanatory Notes, or Section/Chapter Notes; run controlled RAG baselines, measure gains on long-tail/rare headings, and assess citation quality.
- GRIs and legal grounding: model behavior is not evaluated against General Rules of Interpretation, Section/Chapter Notes, or Explanatory Notes; build tests that require and verify rule-grounded reasoning with explicit citations.
- Hard-case coverage: composite goods, kits, parts vs. accessories, essential character, and “use” provisions are not specifically stress-tested; create targeted challenge sets for these regimes.
- Cross-country generalization: only U.S. 10-digit is evaluated; extend to other national extensions (e.g., EU CN 8-digit, India/China national suffixes) and compare cross-jurisdiction transfer.
- Multilingual robustness: dataset is English-only legal text; evaluate multilingual inputs and domain-transfer from colloquial/non-legal descriptions across languages.
- Class imbalance and per-chapter analysis: no breakdown by section/chapter or head/subhead frequency; report macro-averaged metrics, per-chapter confusion, and long-tail performance.
- Baselines and ablations: no systematic ablations on model size (e.g., 3B/8B), training objectives (contrastive/DPO), or non-LLM baselines (retrieval+rules, linear/GBM on structured features); publish a comprehensive ablation suite.
- Prompting and decoding transparency: prompts, temperatures, and decoding settings for proprietary models are not fully specified; release prompts, seeds, and decoding configs for replicability.
- Top-k and near-miss utility: only top-1 and 6-digit matches reported; add top-k accuracy, edit-distance/path-distance metrics, and human adjudication of “closest valid” proposals.
- Robustness to missing attributes: many classifications require composition percentages, material, use, or dimensions; evaluate performance under systematically missing or uncertain attributes and active-query strategies.
- Real-world deployment metrics: latency, throughput, and energy/cost trade-offs are not measured; provide end-to-end benchmarks including batching, SLAs, and carbon estimates.
- Cost estimation assumptions: API/self-hosted cost figures lack token accounting sensitivity and variance; report token counts, truncation rates, hardware utilization, and sensitivity analyses.
- Pretraining contamination: potential exposure of CROSS/HTS text in pretraining corpora is not assessed; perform decontamination checks and evaluate on freshly held-out sources.
- OOD generalization: no tests on newly added chapters/headings or unseen product categories; include OOD splits and revision-era additions to measure robustness.
- Human factors and workflow: no study of broker interaction, acceptance rates, productivity, or oversight UX; conduct user studies and measure assisted accuracy/time-to-clearance.
- Security and misuse: no evaluation of adversarial prompts, prompt injection via product descriptions, or privacy leakage; add robustness and security testing suites.
- Data provenance and reproducibility: scraping/versioning details and code are not fully documented; release scraper, snapshots, and data lineage to ensure exact reproducibility.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that leverage the released Atlas model and HTS CROSS dataset today. Each item notes sectors, likely tools/workflows, and key dependencies/assumptions.
- Human-in-the-loop HTS code assistant for customs brokers and 3PLs
- Sectors: logistics, customs brokerage, e-commerce fulfillment
- Tools/workflows: Atlas API or self-hosted service embedded in SAP GTS, Oracle GTM, Descartes, WiseTech; confidence scoring; auto-suggest top-k 10-digit codes with 6-digit fallback; one-click escalation to licensed broker
- Dependencies/assumptions: 40% 10-digit accuracy requires broker review; frequent HTS updates need retrieval or scheduled refresh; audit logging for liability
- Shipment triage for postal operators and carriers to prevent documentation holds
- Sectors: postal networks (UPU members), couriers (DHL, FedEx, UPS)
- Tools/workflows: pre-advice scanning of CN22/CN23 forms; queue prioritization by confidence/risk; flag incomplete descriptions; bulk inference at intake hubs
- Dependencies/assumptions: integration with EAD/ICS2 data; language normalization; throughput/latency SLAs at hub scale
- 6-digit harmonized prefill for cross-border marketplaces and SMB sellers
- Sectors: marketplaces (Amazon, eBay), storefronts (Shopify, WooCommerce), SMB exporters
- Tools/workflows: checkout widgets to prefill HS-6; seller dashboard prompts for missing attributes (material, function, processing)
- Dependencies/assumptions: product description quality; multilingual support for seller inputs; clear disclaimers and human override
- Landed cost/duty calculators with improved pre-classification
- Sectors: finance for e-commerce, ERP/CPQ, tax engines
- Tools/workflows: plug Atlas into landed cost APIs; compute duty/VAT ranges using predicted HS-6/HS-10; show confidence bands
- Dependencies/assumptions: accurate duty tables by code/country; handling of preferential rates and origin rules; legal disclaimers
- Compliance QA and training copilot for classification teams
- Sectors: professional services, large importers
- Tools/workflows: side-by-side human vs. Atlas recommendations; reasoning trace review; sampling audits; mistake taxonomy dashboards
- Dependencies/assumptions: mapping to internal SOPs; governance for when to accept AI rationale; secure storage of case data
- Product onboarding classification for PIM/PLM and NPI workflows
- Sectors: manufacturing (automotive, industrials, semiconductors), retail
- Tools/workflows: classify SKUs as they enter PIM/PLM; prompt engineers for missing attributes that disambiguate codes; enforce attribute checklists derived from rulings
- Dependencies/assumptions: structured product data access; BOM/spec ingestion; organizational change management
- Privacy-preserving, self-hosted classification for regulated enterprises
- Sectors: automotive, aerospace, semiconductors, industrials
- Tools/workflows: deploy Atlas on-prem/private cloud; VPC inference endpoints; role-based access and audit trails
- Dependencies/assumptions: GPU availability and MLOps; periodic model updates; internal security reviews
- Documentation drafting assistant with citations
- Sectors: logistics, legal/compliance
- Tools/workflows: generate customs-ready product descriptions and justification snippets; link to HTS headings/notes/CROSS rulings to support decisions
- Dependencies/assumptions: retrieval over HTS/CROSS to ground outputs; legal review; avoid exposing raw chain-of-thought to external parties
- Academic benchmark for hierarchical reasoning and legal-domain NLP
- Sectors: academia, ML R&D labs
- Tools/workflows: course labs; public leaderboards; ablation studies (RAG, DPO, contrastive objectives) using the released dataset
- Dependencies/assumptions: compute access for fine-tuning; dataset licensing terms; reproducible evaluation splits
Long-Term Applications
The following applications are plausible with further accuracy gains, retrieval integration, multimodality, or regulatory adoption. They outline potential product directions and policy impact.
- Near-autonomous end-to-end HTS classification and auto-clearance
- Sectors: customs agencies, postal/courier networks
- Tools/workflows: retrieval-augmented Atlas with verifier models; calibrated uncertainty; automatic filing when confidence > threshold; human fallback
- Dependencies/assumptions: >90% 10-digit accuracy on diverse goods; regulatory acceptance and liability frameworks; independent certification
- Multimodal classification from images/spec sheets/BOM/CAD
- Sectors: manufacturing, electronics, fashion, online retail
- Tools/workflows: MLLMs that fuse text, images, and CAD/BOM to infer composition and processing steps critical to code selection
- Dependencies/assumptions: labeled multimodal datasets; secure handling of proprietary designs; robust OCR/CAD parsers
- Global code translation and synchronization (HS-6 → national 8/10-digit) with dynamic rate computation
- Sectors: global trade compliance, tax engines, ERPs
- Tools/workflows: country-specific “tariff maps” and crosswalks; daily updates to tariff schedules; API services for duty and non-tariff measures
- Dependencies/assumptions: licensed access to national tariff data; automation of schedule updates; versioning and provenance tracking
- Integrated export controls and sanctions classification (ECCN/Schedule B)
- Sectors: dual-use/defense, semiconductors, chemicals
- Tools/workflows: unified pipeline that proposes HTS, Schedule B, and ECCN; red-flag screening; evidence-backed justifications
- Dependencies/assumptions: new datasets and labeling; high-stakes human oversight; evolving regulatory regimes
- Continuous regulation monitoring, change detection, and auto-reclassification
- Sectors: compliance, policy tech
- Tools/workflows: watch HTS updates, WCO amendments, rulings; identify impacted SKUs; propose reclassification/duty impact scenarios
- Dependencies/assumptions: robust retrieval over 17,000+ pages; diff tooling; integration with product catalogs
- Fraud/misclassification risk scoring and audit analytics
- Sectors: customs authorities, marketplaces, insurers
- Tools/workflows: anomaly detection on filed codes vs. peer products; tension with pricing/weight; targeted inspections
- Dependencies/assumptions: access to filings and outcomes; privacy-preserving analytics; false-positive cost controls
- Duty optimization and tariff engineering advisory (scenario simulation)
- Sectors: manufacturing, apparel, consumer electronics
- Tools/workflows: “what-if” simulations for design/material/process changes; country-of-origin strategies; special programs (FTA, drawback)
- Dependencies/assumptions: ethical and legal boundaries; accurate rules-of-origin modeling; cross-functional buy-in
- Digital Single Window integration and standards-based APIs
- Sectors: government trade platforms, port community systems
- Tools/workflows: interoperable APIs for declaration pre-validation; ICS2/EAD alignment; event-driven clearance pipelines
- Dependencies/assumptions: public procurement cycles; security certification; standards alignment (WCO data model)
- Edge-deployable distilled models for ports, hubs, and field inspections
- Sectors: logistics, customs inspection, postal counters
- Tools/workflows: 3B–8B distilled “Atlas-lite” running on CPU/edge GPU; offline batch inference; kiosk-style assistants
- Dependencies/assumptions: effective distillation without major accuracy loss; device management; local caching of tariff data
- Open evaluation ecosystem and community challenges
- Sectors: academia, startups, vendors
- Tools/workflows: hosted leaderboard with anti-leak evaluation; task variants (few-shot, RAG, multilingual); prize-backed benchmarks
- Dependencies/assumptions: curated, non-contaminated test sets; standardized metrics (10-digit, 6-digit, calibrated confidence)
- Consumer-grade mobile app for guided customs declarations
- Sectors: daily life, SMB exporters, gig sellers (Etsy)
- Tools/workflows: scan product/photo, answer guided questions, receive HS-6 suggestion and documentation prompts; “share to carrier” export
- Dependencies/assumptions: intuitive UX and disclaimers; multilingual UI; responsible handling of uncertainty and advice
Notes on Feasibility and Risk
- Accuracy and liability: With 40% 10-digit accuracy, immediate deployments should be assistive (not autonomous) and gated by confidence with human sign-off.
- Data drift and updates: Tariff schedules, rulings, and special provisions change; workflows need scheduled refresh, retrieval grounding, and versioned provenance.
- Input quality: Model performance depends on product descriptions capturing key attributes (material, function, processing, origin); attribute-elicitation UIs materially improve outcomes.
- Privacy and governance: Sensitive SKU/BOM data necessitates self-hosting, role-based access, encryption, and auditable logs.
- Internationalization: HS-6 generalizes globally, but national extensions differ; localization and access to national tariff data are required for country-specific accuracy.
- Compliance culture: Adoption hinges on alignment with licensed broker workflows, auditability, and clear responsibility boundaries between AI suggestions and human decisions.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to assess their impact on performance. "several ablation studies could provide deeper insights and further guide the community"
- AdamW optimizer: An Adam variant with decoupled weight decay that improves generalization. "using the AdamW optimizer"
- bf16 precision: A 16-bit floating-point format (bfloat16) that preserves dynamic range while reducing memory. "we employed bf16 precision"
- Chain-of-thought reasoning: Prompting models to generate intermediate reasoning steps to improve problem solving. "aligning with recent work on chain-of-thought reasoning"
- Cosine learning-rate schedule: A learning-rate schedule that follows a cosine curve to gradually reduce the rate. "a cosine learning-rate schedule"
- Customs and Border Protection (CBP): The U.S. agency that issues customs rulings and enforces import regulations. "U.S. Customs and Border Protection (CBP)"
- de minimis exemption: A trade rule allowing duty-free entry of goods below a specified value threshold. "the modifications to the de minimis exemption"
- Dense architecture: A neural network design where all parameters are active, as opposed to sparsely activated MoE models. "LLaMA-3.3-70B is a dense architecture"
- Direct Preference Optimization (DPO): A training method that optimizes model outputs directly against preference signals. "Direct Preference Optimization (DPO)"
- Fully sharded data parallelism: A distributed training technique that shards model parameters, gradients, and optimizer states across devices. "using fully sharded data parallelism"
- Gradient accumulation: A technique to simulate larger batch sizes by accumulating gradients over multiple steps before an update. "gradient accumulation to simulate a batch size of 64 sequences"
- Gradient norms: Measures of the magnitude of gradients, used to monitor training stability. "We observed stable gradient norms"
- Harmonized Tariff Schedule (HTS): The standardized system of tariff codes used for classifying traded products, with a 6-digit global base and country-specific extensions. "Harmonized Tariff Schedule (HTS)"
- LLaMA-3.3-70B: A 70-billion-parameter LLM used as the base for fine-tuning in this study. "LLaMA-3.3-70B"
- Mixture-of-Experts (MoE): A model architecture that routes inputs to specialized expert subnetworks, enabling sparse activation. "Mixture-of-Experts (MoE) architectures"
- Negative log-likelihood (NLL): A loss function that penalizes the log probability of the correct target, minimized in supervised training. "which corresponds to the standard negative log-likelihood objective"
- Retrieval augmentation: Enhancing model inputs with relevant external documents fetched at inference or training time. "Retrieval augmentation: Integrating retrieval over the 17,000-page HTS documents"
- Self-hosting: Deploying models on one’s own infrastructure to maintain control over data privacy and cost. "can be self-hosted to guarantee data privacy"
- Supervised fine-tuning (SFT): Adapting a pretrained model using labeled input–output pairs to specialize it for a target task. "supervised fine-tuning (SFT)"
- Tariff classification: Assigning products to the correct tariff codes for customs compliance and duties. "We introduce the first benchmark for HTS code classification"
- U.S. Customs Rulings Online Search System (CROSS): The official database of binding customs rulings used to construct the dataset. "U.S. Customs Rulings Online Search System (CROSS)"
- World Customs Organization (WCO): The international body that maintains global customs standards, including the harmonized code system. "standardized by the World Customs Organization (WCO)"
Collections
Sign up for free to add this paper to one or more collections.

