- The paper presents the Avengers-Pro framework that ensembles heterogeneous LLMs to optimize the performance–efficiency trade-off via a tunable alpha parameter.
- It employs semantic query embedding and clustering to achieve 66.66% average accuracy and reduce costs by up to 63% compared to single-model systems.
- The approach establishes a Pareto frontier in cost–accuracy, offering scalable, practical insights for real-world LLM deployment.
Introduction
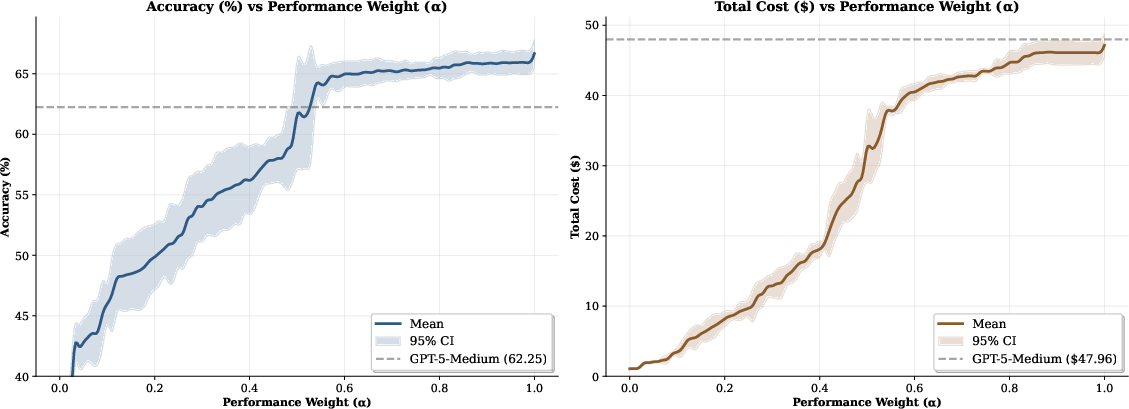
The paper "Beyond GPT-5: Making LLMs Cheaper and Better via Performance–Efficiency Optimized Routing" (2508.12631) presents Avengers-Pro, a test-time routing framework that ensembles heterogeneous LLMs to optimize the trade-off between performance (accuracy) and efficiency (cost). The framework generalizes the routing paradigm introduced in GPT-5, extending it to a broader set of models and enabling fine-grained control over the performance–efficiency balance via a tunable parameter α. Avengers-Pro demonstrates state-of-the-art results across six challenging benchmarks and eight leading LLMs, consistently achieving a Pareto frontier in the cost–accuracy space.
Avengers-Pro operates by embedding incoming queries, clustering them by semantic similarity, and routing each query to the most suitable model based on a performance–efficiency score. The routing process is formalized as follows:
- Query Embedding: Each query is encoded into a high-dimensional semantic vector using a text embedding model (Qwen3-embedding-8B, 4096 dimensions).
- Clustering: Queries are grouped into k clusters (k-means, k=60), each representing a semantically coherent query type.
- Model Profiling: For each model i and cluster cj, performance (pji) and efficiency (qji, measured as cost) are estimated using labeled data.
- Performance–Efficiency Scoring: The score for model i on cluster cj is computed as:
xji=αp~ji+(1−α)(1−q~ji)
where α∈[0,1] controls the trade-off, and p~ji, q~ji are normalized performance and cost.
- Routing Decision: At inference, the query is assigned to its top-p nearest clusters (p=4). The model with the highest aggregated score over these clusters is selected to generate the response.
This approach enables dynamic, query-specific model selection, leveraging the strengths of both high-capacity and efficient models.
Experimental Setup
Avengers-Pro is evaluated on six benchmarks: GPQA-Diamond, Human's Last Exam, HealthBench, ARC-AGI, SimpleQA, LiveCodeBench, and τ2-bench. The ensemble comprises eight models from four families: GPT-5-chat, GPT-5-medium, Claude-4.1-opus, Claude-4-sonnet, Gemini-2.5-pro, Gemini-2.5-flash, Qwen3, and Qwen3-thinking. All models are accessed via the OpenRouter API, ensuring standardized cost and interface.
Avengers-Pro consistently outperforms the strongest single model (GPT-5-medium) in both accuracy and cost efficiency. Key results include:
The trade-off parameter α enables fine-grained control: low α values favor efficient models (Qwen3, Qwen3-thinking), while high α values route more queries to high-capacity models (GPT-5-medium, Gemini-2.5-pro).
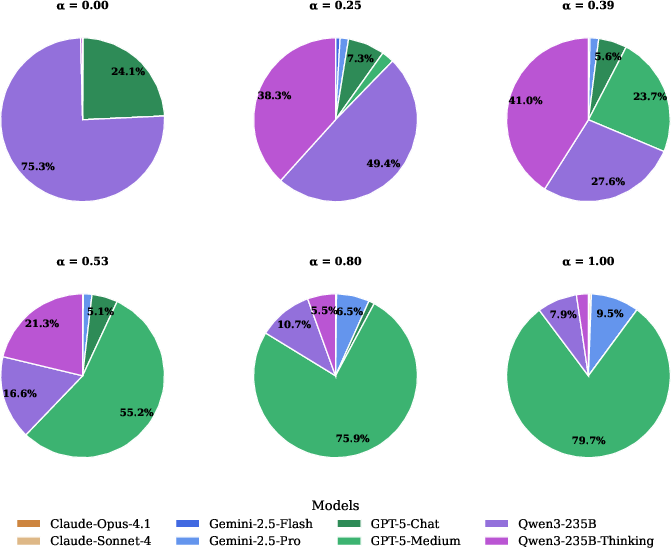
Figure 2: Proportion of model usage as a function of α; low α routes to Qwen3/Qwen3-thinking, high α increases usage of GPT-5-medium and other high-capacity models.
Analysis and Implications
The empirical results demonstrate that test-time routing with performance–efficiency optimization is a robust strategy for deploying LLMs in production environments where both cost and accuracy are critical. The framework's ability to achieve a Pareto frontier is particularly notable, as it guarantees optimality in the cost–accuracy space relative to any single model.
The methodology is generalizable and can be extended to larger ensembles, more granular clustering, or alternative scoring functions. The use of semantic clustering and per-cluster profiling allows for nuanced routing decisions that adapt to query complexity and model specialization.
From a practical perspective, Avengers-Pro enables organizations to deploy LLMs with predictable cost–performance characteristics, dynamically adjusting to workload requirements and budget constraints. The framework is compatible with existing model APIs and can be integrated into inference pipelines with minimal overhead.
Future Directions
Potential avenues for future research include:
- Adaptive Clustering: Dynamic adjustment of cluster granularity based on query distribution.
- Multi-model Routing: Extending routing to allow multi-model ensembles per query (e.g., voting or fusion).
- Latency Optimization: Incorporating latency as an additional efficiency metric.
- Online Learning: Updating model profiles and cluster assignments in real-time as new data arrives.
- Generalization to Other Modalities: Applying the routing framework to multi-modal LLMs and agentic systems.
Conclusion
Avengers-Pro establishes a principled framework for optimizing the performance–efficiency trade-off in LLM inference via test-time routing. By leveraging semantic clustering and per-cluster model profiling, it consistently outperforms single-model baselines, achieving superior accuracy and cost efficiency. The approach is scalable, adaptable, and directly applicable to real-world LLM deployment scenarios, with significant implications for both research and industry.