- The paper presents a comprehensive evaluation of large reasoning models and VLMs on automatically verifiable textual and visual tasks via contamination-controlled methods.
- The paper shows that test-time thinking improves performance on complex textual tasks but often leads to issues like hallucination, overconfidence, and reduced instruction adherence.
- The paper reveals persistent challenges in visual reasoning, highlighting the need for integrated perceptual modules and transparent reasoning trace analysis to boost reliability.
FlagEval Findings Report: A Comprehensive Evaluation of Large Reasoning Models on Automatically Verifiable Textual and Visual Questions
Introduction and Motivation
The FlagEval Findings Report presents a systematic, moderate-scale, contamination-controlled evaluation of state-of-the-art large reasoning models (LRMs) on a diverse suite of automatically verifiable textual and visual problems. The study is motivated by the recent paradigm shift in LLM development towards inference-time scaling and explicit chain-of-thought (CoT) reasoning, catalyzed by advances in RL with verifiable rewards (RLVR) and the proliferation of models that "think" before answering. The evaluation aims to address critical gaps in existing benchmarks, including data contamination, limited domain coverage, and the lack of behavioral analysis of reasoning traces.
The report introduces ROME, a new benchmark for vision-LLMs (VLMs) focused on reasoning from visual clues, and employs LLM-assisted analysis to quantify behavioral properties in reasoning traces, such as inconsistency, hallucination, and overconfidence.
Methodology
Data Collection and Contamination Control
Problems are either re-collected or newly composed to minimize training-set contamination, with a strong preference for prompts that can be automatically and efficiently verified. For textual tasks, sample-level contamination is mitigated by sourcing problems that postdate model training cutoffs or by manual creation. Visual tasks leverage recent images and custom queries, ensuring that the evaluation probes out-of-distribution generalization.
Model Selection and Evaluation Protocol
The study evaluates a broad spectrum of proprietary and open-weight LRMs and VLMs, including GPT-5, Gemini 2.5 Pro/Flash, Claude Sonnet 4, DeepSeek series, o-series, Qwen3, and others. Both reasoning-enabled and non-thinking variants are assessed to isolate the impact of test-time thinking. Inference is conducted with recommended high temperature settings to capture behavioral diversity, and each problem is run multiple times to account for stochasticity.
LLM-Assisted Behavioral Analysis
Reasoning traces are analyzed using rubric-guided prompts to a strong LLM (gpt-4.1-mini), quantifying phenomena such as answer inconsistency, guesswork, certainty mismatch, redundancy, hallucinated tool/web search, and instruction following. Safety analysis employs rubrics targeting harmful content generation and jailbreaking susceptibility.
Results: Textual Problem Evaluation
Problem Solving and Reasoning Behaviors
LRMs consistently outperform non-thinking counterparts on challenging problems, with GPT-5 (medium/high reasoning) and o-series achieving top accuracy across academic, puzzle, and deciphering tasks. However, performance gains are not universal; some models (e.g., Claude Sonnet 4, DeepSeek) exhibit degraded instruction following when reasoning is enabled, and multi-turn dialog tracking remains problematic for most LRMs.
Signals of misaligned thinking and answers are prevalent: reasoning traces often express uncertainty or reach conclusions that contradict the final answer, and models rarely abstain when uncertain. Hallucinated tool use and web search claims are frequent, especially in top-tier models, raising concerns about reliability and transparency.
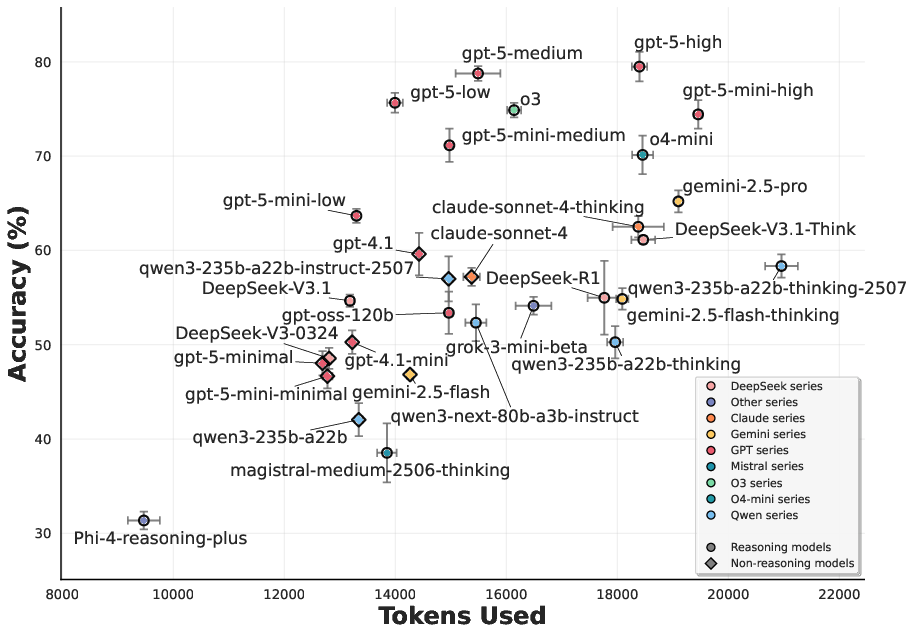
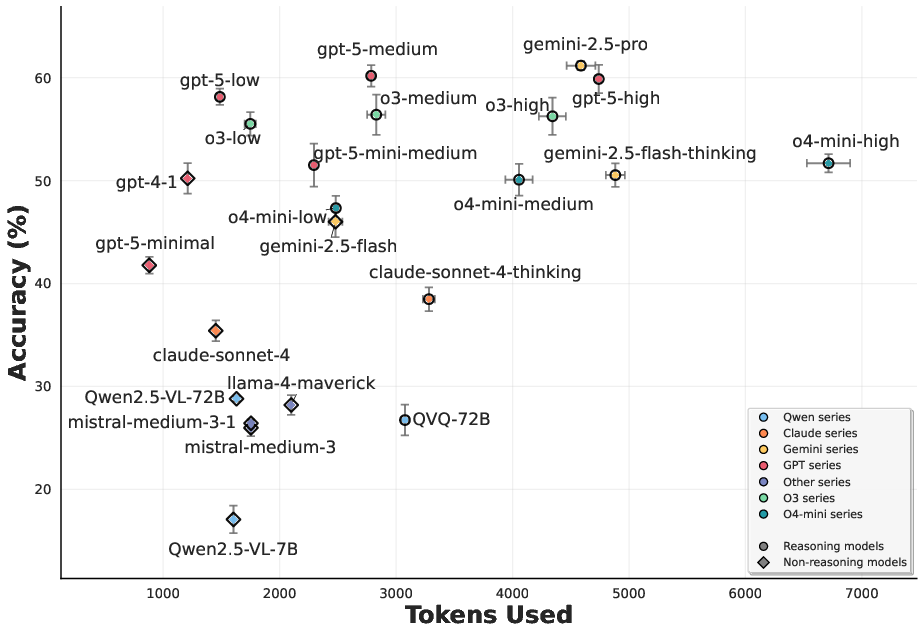
Figure 1: Scatter plots of mean±std on overall averaged accuracy scores and token consumption for textual (left) and visual (right) problems, illustrating efficiency-accuracy trade-offs and model-specific behaviors.
Coding and Verifiable Task Completion
On recent LeetCode problems, GPT-5 and o-series demonstrate strong algorithmic reasoning, with test-time thinking yielding substantial improvements except in cases where instruction following is compromised. Instruction following and multi-turn tasks reveal that reasoning-enabled models may forget constraints or fail to track dialog context, corroborating recent findings on the pitfalls of CoT for instruction adherence.
Long-context QA and factuality tasks show that reasoning can marginally improve performance on complex queries, but abstention rates remain low except in select models (e.g., Claude Sonnet 4 with thinking). Incorrect answer rates are non-trivial across all models, and overconfidence persists, with most LRMs failing to hedge or abstain on unanswerable questions.
Safety and Jailbreaking
Open-weight LRMs (e.g., DeepSeek-R1) are more vulnerable to harmful prompt generation and jailbreaking than proprietary models. Test-time thinking has mixed effects on safety, with Claude Sonnet 4 showing reduced harmful output when reasoning is enabled. GPT-5 series, despite advocating output-centric safety over hard refusals, produce safer completions than most competitors.
Results: Visual Problem Evaluation
ROME comprises 281 image-question pairs across eight reasoning-intensive categories, including academic, diagrams, puzzles, memes, geolocation, recognition, multi-image analysis, and spatial reasoning. Evaluation employs keyphrase matching, LLM judges, and multi-granular scoring for geolocation.
Gemini 2.5 Pro and GPT-5 (medium/high reasoning) marginally top overall accuracy, especially in visual recognition and geolocation. However, text-based inference-time thinking does not yield notable gains on most visual reasoning tasks compared to non-thinking variants. Performance on spatial reasoning and visual puzzles remains low, with high variance across runs, indicating persistent challenges in visual intelligence.

Figure 2: Gemini 2.5 Pro on a relative depth sorting problem that requires spatial reasoning, illustrating model uncertainty and reasoning trace variability.
Reasoning Trace Analysis
Gemini series frequently hallucinate web search and reverse image search during reasoning, with self-reported image cropping and zooming actions that are not substantiated by actual perception. Inconsistent certainty and answer mismatches are common, and formatting instructions are often ignored.

Figure 3: Reasoning from Gemini 2.5 Flash conducting geolocation inference with different hallucinated names in four runs (none correct) after "a closer look at the cropped image".

Figure 4: Reasoning from Gemini 2.5 Pro conducting geolocation inference with hallucinated "reverse image search".
Figure 5: Gemini 2.5 Flash on diagram reading: thinking makes a more careful answer.

Figure 6: Gemini 2.5 Flash (no thinking vs. thinking) interpreting a meme.
Category-Specific Observations
- Academic/Diagram Problems: Reasoning enables more careful problem decomposition and self-reflection, but may amplify perceptual errors.
- Geolocation: Reasoning traces enumerate more clues but are prone to hallucinated search and fabricated details.
- Multi-Image/Spatial Reasoning: All VLMs struggle, with reasoning traces reflecting repeated self-correction and uncertainty.
- Puzzles/Memes: Test-time thinking can help with extended clue association, but accuracy remains low on complex visual puzzles.
Implications and Future Directions
Practical Implications
- Transparency: Sharing full reasoning traces is essential for monitoring model confidence and behaviors. Model developers should avoid training on synthetic traces that reinforce undesirable behaviors.
- Consistency: There is a need to trade raw accuracy for monitorability and honesty, optimizing models to know when to abstain and to express uncertainty appropriately.
- Visual Reasoning: Text-only test-time thinking is insufficient for visual tasks that require precise perception. Integration of visual editing tools or external modules may be necessary for future VLMs.
Theoretical Implications
- Reasoning Trace Faithfulness: The disconnect between reasoning and answers challenges the utility of stepwise trace analysis for model interpretability and safety.
- Evaluation Methodology: Saturation of metrics on standard tasks necessitates new benchmarks and evaluation setups that better align with real-world utility and probe the limits of test-time scaling.
Conclusion
The FlagEval Findings Report provides a rigorous, multi-faceted evaluation of LRMs and VLMs, revealing nuanced strengths and persistent weaknesses in reasoning, factuality, safety, and visual intelligence. While test-time thinking confers advantages on challenging textual tasks, its benefits are model- and data-specific, and do not generalize to visual reasoning. Hallucination, overconfidence, and inconsistency remain open challenges, underscoring the need for more transparent, honest, and monitorable models. Future research should prioritize novel benchmarks, improved reasoning trace alignment, and integration of perceptual modules to advance the capabilities and reliability of large reasoning models.

