- The paper introduces head attribution to systematically measure each attention head's contribution in transferring image information to text.
- It reveals that information flow is distributed across layers with mid-to-late heads having greater impact regardless of high attention weights.
- Experiments on COCO images demonstrate token-level analysis, highlighting the roles of specific tokens in effective image-to-text communication.
Interpreting Attention Heads for Image-to-Text Information Flow in Large Vision-LLMs
Introduction
This paper explores the internal mechanisms of Large Vision-LLMs (LVLMs), specifically focusing on the role of attention heads in enabling image-to-text information flow. This flow is pivotal for tasks such as visual question answering, where understanding the transfer of information from visual inputs to textual outputs is crucial. The paper introduces a novel technique called head attribution, which identifies the attention heads responsible for this information transfer.
Head Attribution Method
Head attribution is inspired by component attribution methods and is designed to quantify each attention head's contribution to the final model output. Traditional methods, such as single head ablation, are inadequate for LVLMs due to their reliance on multiple attention heads to distribute the information flow. The paper proposes a linear regression model that estimates the impact of each head on the output logit by systematically ablating heads and evaluating their contributions.
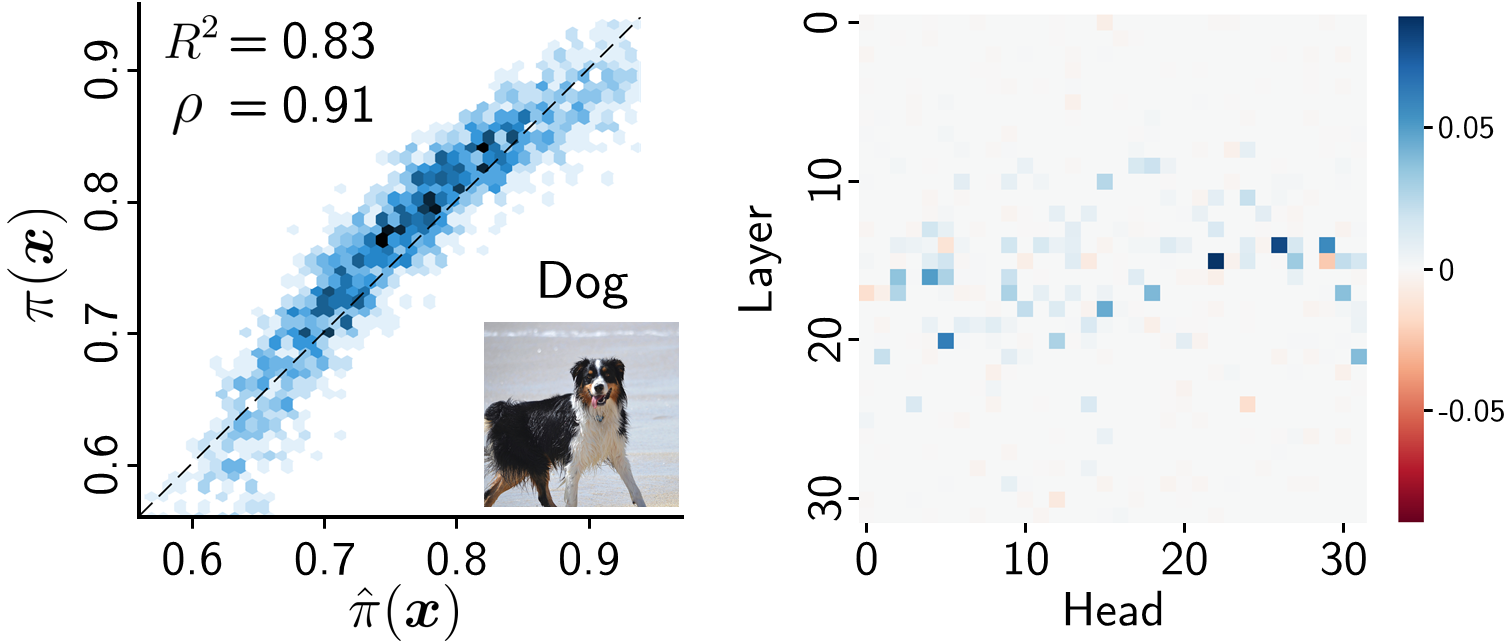
Figure 1: Example result of head attribution for LLaVA-1.5-7B.
Experimental Setup
Experiments are conducted across ten LVLMs, focusing on a visual object identification task, which requires models to identify the main object in given images. This task is chosen for its simplicity and ability to highlight the mechanisms of image-to-text information flow. The experiments utilize images from the COCO dataset and involve multiple models, including variations of LLaVA and InternVL.
Key Findings
- Distributed Information Flow: The study demonstrates that the image-to-text information flow is distributed across multiple attention heads. Single head ablation does not significantly impact the output logits, highlighting the need for a comprehensive head attribution approach.
- Head Contribution Variation: The contribution of attention heads varies across layers, with mid-to-late layer heads playing a more significant role in transferring image information. The analysis reveals that head importance does not necessarily correlate with high image attention weights, contradicting common assumptions.
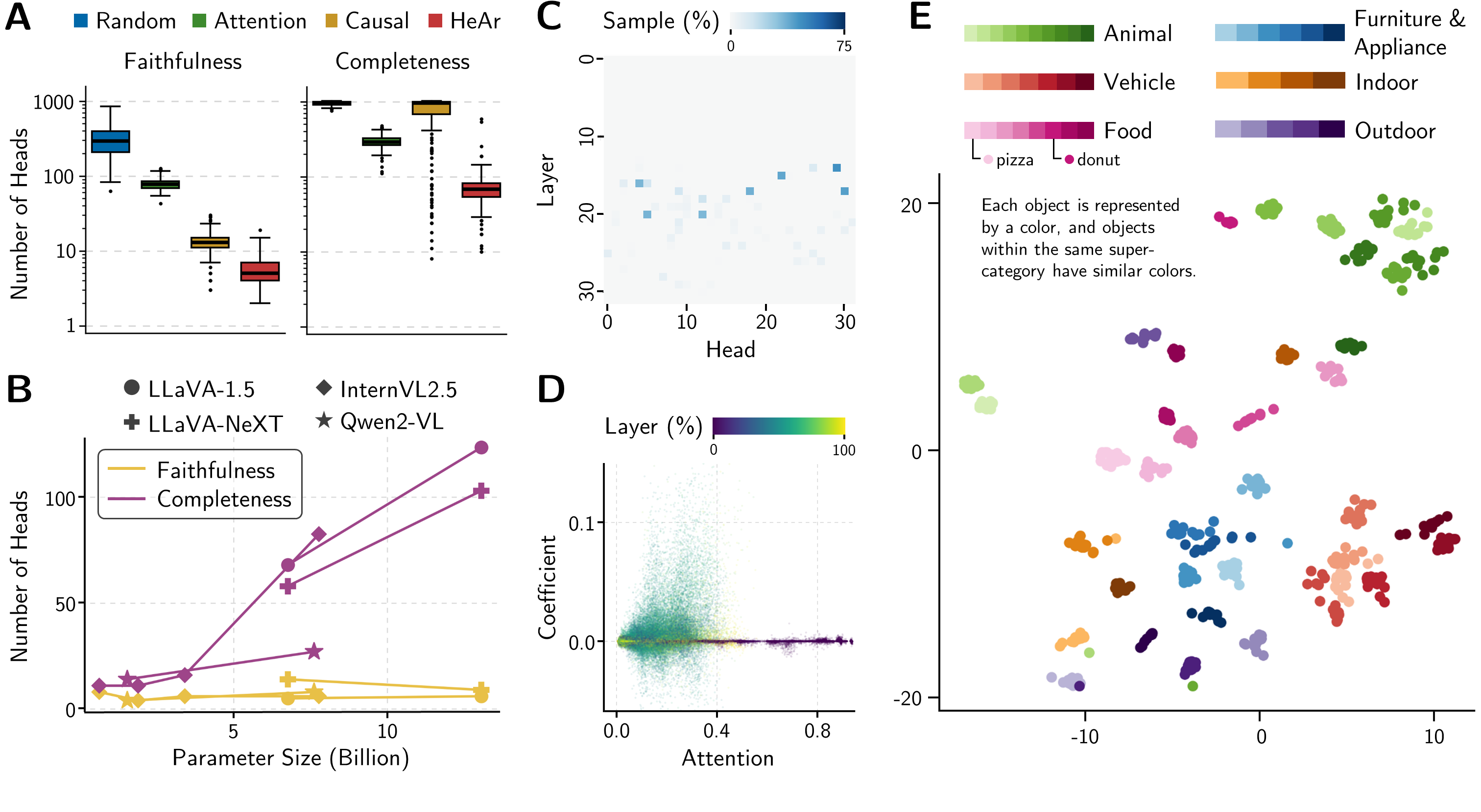
Figure 2: Minimum number of heads required for faithfulness and completeness across models.
- Token-Level Analysis: The research further explores the token-level information flow, identifying that image information is transferred primarily to role-related tokens and the final token, rather than the question tokens directly.
Implications
The findings have far-reaching implications for both interpretability and efficiency in LVLMs. By understanding the image-token interactions and attention head contributions, it becomes feasible to develop more transparent models and potentially reduce computational costs by focusing only on essential heads and tokens.
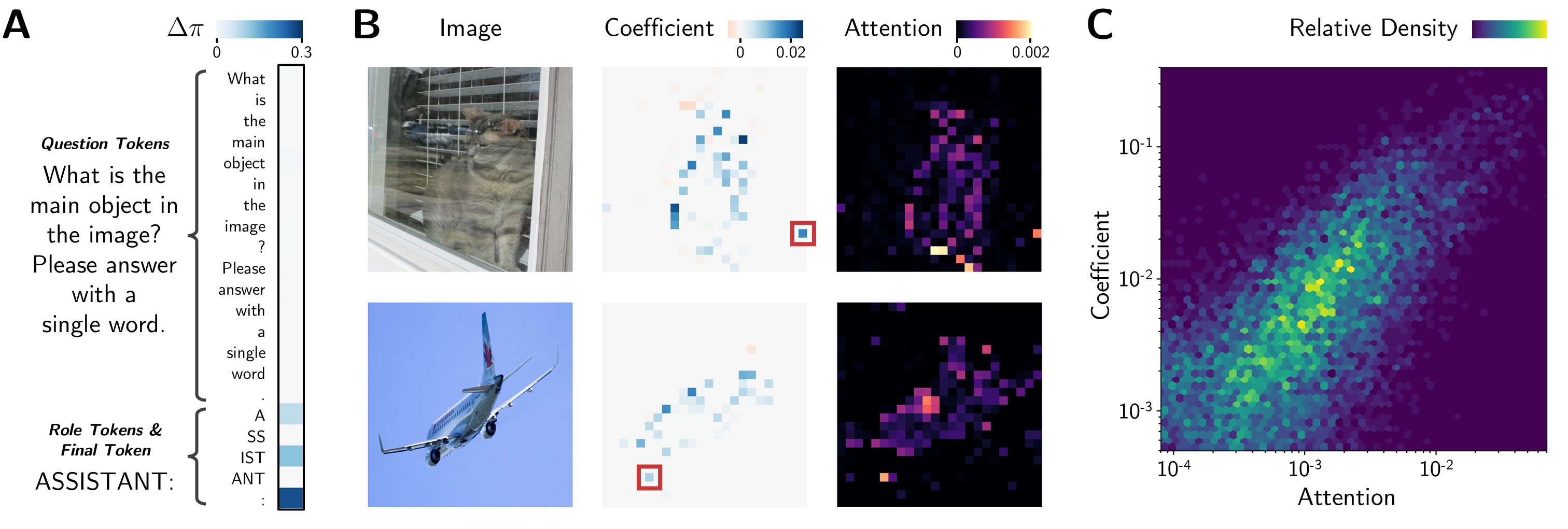
Figure 3: Logit differences relative to critical tokens across models.
Conclusion
The paper presents a robust framework for analyzing attention heads in LVLMs, providing insights into how image-to-text information is transferred. Head attribution emerges as a valuable tool for interpreting LVLMs' internal mechanisms, paving the way for more efficient and transparent AI systems. Future work could explore extending these findings to more complex tasks and refining the attribution methods to enhance scalability and practicality.