- The paper highlights the critical challenge of achieving consistent generalizability across diverse tasks and environments in LLM-based agents.
- The paper details diversified training strategies and structured inference techniques to improve agent performance and adaptability.
- The paper calls for standardized evaluation frameworks to measure agent robustness and bridge the gap between specialized and generalizable systems.
Generalizability of LLM-Based Agents: A Comprehensive Survey
LLM-based agents represent a burgeoning paradigm extending LLM capabilities beyond static text generation to dynamic environment interaction. Despite their promising applications across domains such as web navigation, robotics, and healthcare, a critical obstacle remains: enhancing their generalizability, defined as the capacity to maintain high performance across variable and previously unseen instructions, tasks, environments, and domains.
Introduction to LLM-based Agents
LLM-based agents effectively integrate LLMs with additional modules enabling perception, action, and memory, allowing them to perform real-world tasks autonomously, such as booking flights entirely online. The architecture typically includes a backbone LLM responsible for processing user instructions and coordinating actions, supported by component modules for perceiving data, storing and retrieving memory, and employing tools for interaction with external systems.
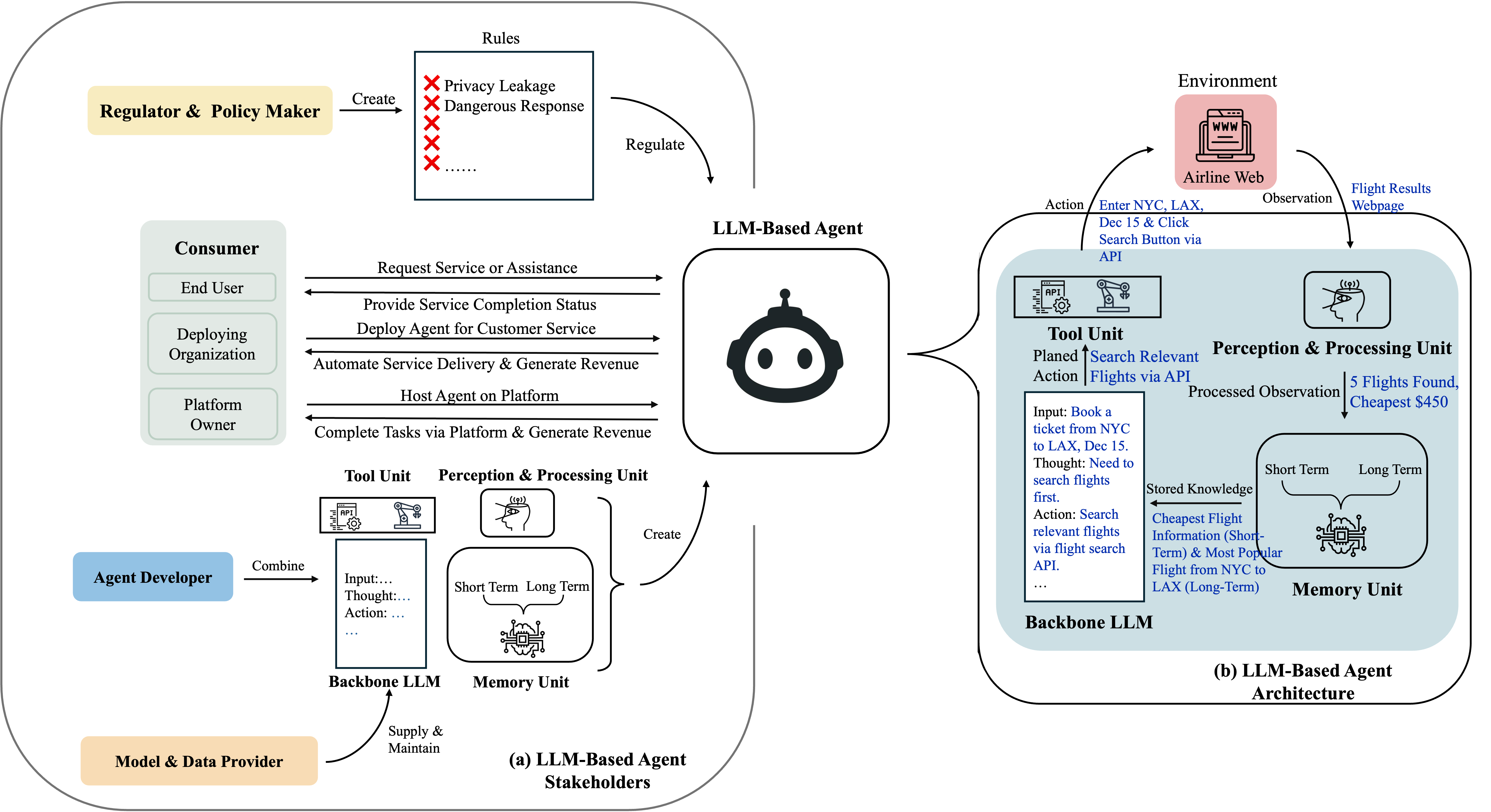
Figure 1: LLM-based agent ecosystem and architecture. (a) Shows different stakeholders and their interactions with the agent, including regulators and policy makers, consumers (end users, deploying organizations, platform owners), agent developers, and model and data providers. (b) Shows the agent architecture using an airline ticket booking example to concretely illustrate the workflow (concrete examples shown in dark blue as illustrations).
Challenges in Agent Generalizability
LLM-based agents face several challenges in generalizability, primarily due to the absence of a universally accepted framework for defining and evaluating it. Most current studies employ inconsistent definitions, causing ambiguity and hindering comparative evaluation. Another challenge is establishing quantitative measurement and theoretical guarantees of agent performance across unseen configurations. Moreover, existing systems often struggle with bridging the gap between generalizable frameworks — those that yield consistent performance when fine-tuned for specific scenarios — and fully generalizable agents, which inherently operate effectively across varied challenges without additional training.
Enhancing Generalizability
- Training Strategies: Improving LLM generalizability involves optimizing training data with diversified tasks across domains and refining objectives to cater to broad performance metrics rather than a few task-specific results. Approaches such as introducing multi-modal training data and curriculum learning are valuable for ensuring comprehensive model exposure to diverse scenarios.
- Inference Techniques: During inference, structured planning with domain-invariant representations allows reusing established logic across different environments, enhancing adaptability. In-context learning can further improve performance by leveraging memory and examples as contextual cues for dynamic planning.
Evaluations and Metrics for Generalizability
Effective evaluation hinges on comprehensive datasets and metrics that fully capture agent adaptability and robustness. Current benchmarks rely heavily on success rates and human-aligned evaluations, but these can mask performance disparities across task categories. Metrics such as performance variance and generalizability cost can offer finer-grained insights into an agent's true adaptability and efficiency in balancing generalization with specialization.
Bridging Frameworks to Agents
A distinction is necessary between generalizable frameworks — those facilitating consistent performance when specifically fine-tuned — and generalizable agents capable of adapting to a variety of unseen scenarios. Future work should focus on establishing benchmarks that measure both framework and agent-level generalizability to ensure advancements at the methodological level translate effectively into real-world robustness.
Conclusion
This survey highlighted the criticality of enhancing the generalizability of LLM-based agents across various domains, drawing attention to the need for standardized evaluation frameworks, effective component coordination, and refined training protocols. Future advancements hinge on integrating methodological innovations with practical applications to realize the full potential of these agents in diverse, dynamically changing environments.

