MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Abstract: Unified multimodal LLMs that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Manzano, an AI model that can both understand images (like answering questions about a photo or reading a chart) and create images from text (like drawing a picture from a prompt). The big idea is to make one simple, scalable system that does both jobs well without one hurting the other.
What questions were the researchers trying to answer?
The paper explores a few straightforward questions:
- Can one model be good at both seeing (understanding images) and drawing (generating images) at the same time?
- Is there a way to represent images so the model doesn’t get confused when switching between these two tasks?
- Will making the model bigger improve both skills consistently?
- Can a simple design and training process work better than complicated ones?
How does Manzano work?
Think of Manzano as a three-part system:
- A shared “camera” for images:
- It first looks at the picture using a visual encoder (like a high-powered camera that turns images into useful features).
- Then it splits into two pathways that speak the language of the model in slightly different ways:
- Continuous tokens for understanding: These are smooth, detailed signals (like a video stream) that help the model notice fine details—important for reading text in images or understanding charts.
- Discrete tokens for generation: These are like LEGO bricks (numbered pieces) the model can stack one by one to build a new image from a text prompt.
- A single LLM brain:
- The LLM predicts the “next piece” of meaning auto-regressively—like writing a story word by word. Here it predicts both text tokens (words) and image tokens (the LEGO-like pieces), all in one shared vocabulary.
- A diffusion image drawer:
- Once the LLM decides on the image tokens, a separate diffusion decoder turns those tokens into actual pixels.
- Diffusion is like starting with a fuzzy image and steadily “unblurring” it into a realistic picture, guided by the tokens the LLM produced.
To make this work well together, the model uses:
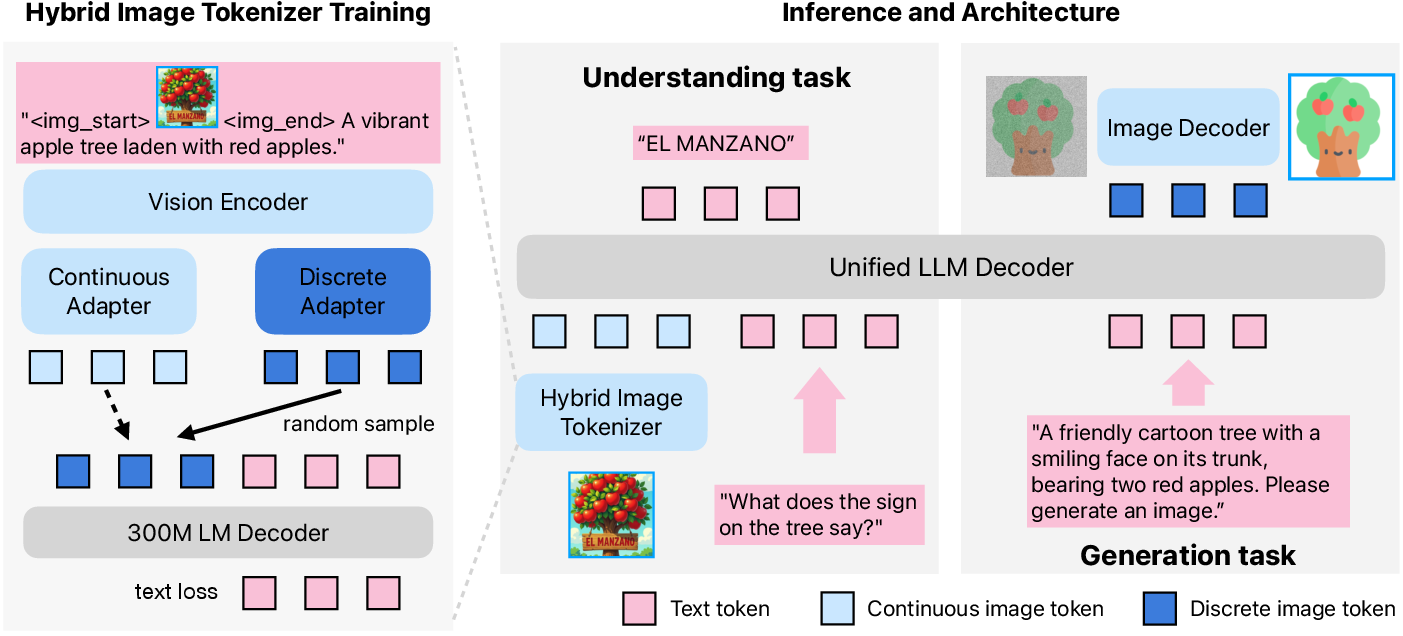
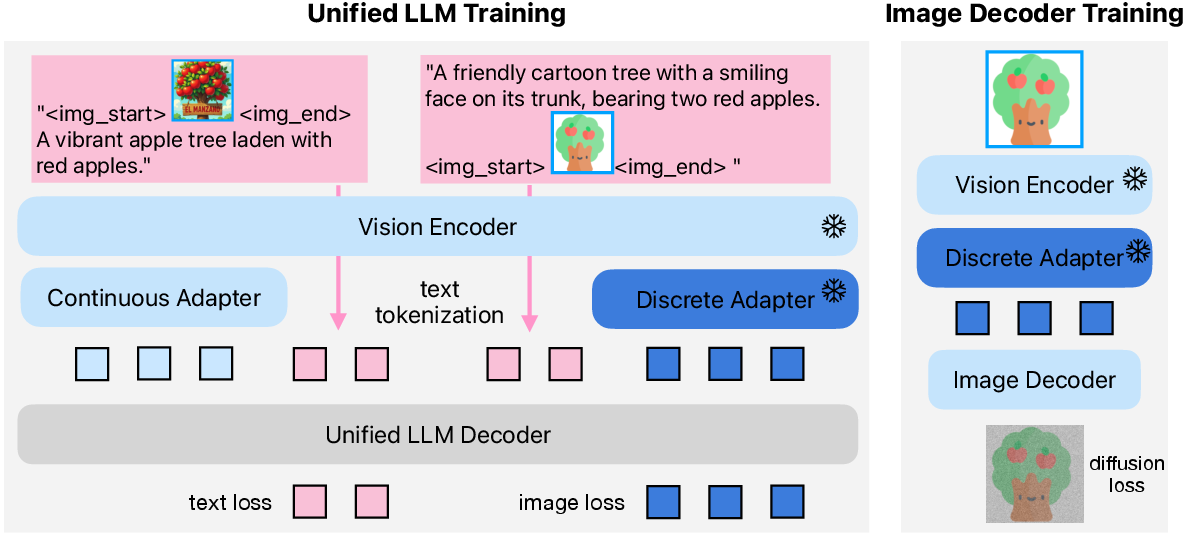
- A hybrid tokenizer: both continuous and discrete tokens come from the same visual encoder, so they live in the same “semantic space.” This reduces conflict inside the LLM because both types of tokens carry consistent meaning.
- Simple training steps:
- Pre-training on a mix of text-only, image understanding, and text-to-image data.
- Continued pre-training on higher-quality image tasks.
- Supervised fine-tuning on carefully chosen instruction-following data for both understanding and generation.
- A unified objective: the LLM uses the same “predict the next token” learning rule for text and image sequences, keeping things simple.
Everyday analogy:
- The shared encoder is a high-quality camera.
- Continuous tokens are like a smooth live feed for careful reading and understanding.
- Discrete tokens are like numbered LEGO bricks for building pictures piece by piece.
- The LLM is the planner that writes stories or blueprints (both words and image pieces).
- The diffusion decoder is the artist who paints the final image based on the blueprint.
What did they find, and why does it matter?
Key findings:
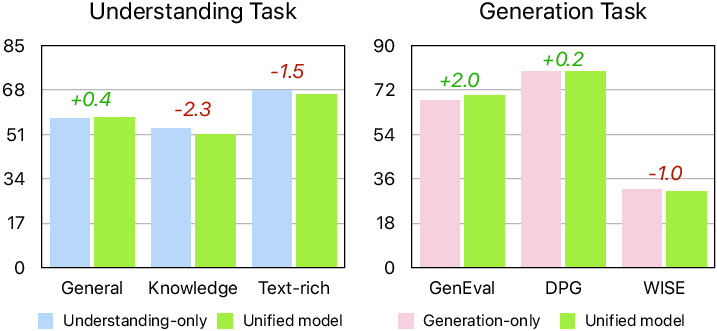
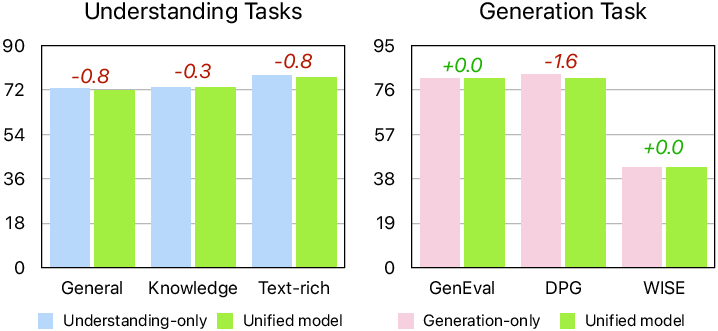
- The hybrid tokenizer reduces conflict: Using one shared encoder with two lightweight adapters worked better than using only discrete image tokens or two totally separate tokenizers. It improved understanding (especially text-heavy tasks) without hurting generation.
- Strong performance across the board:
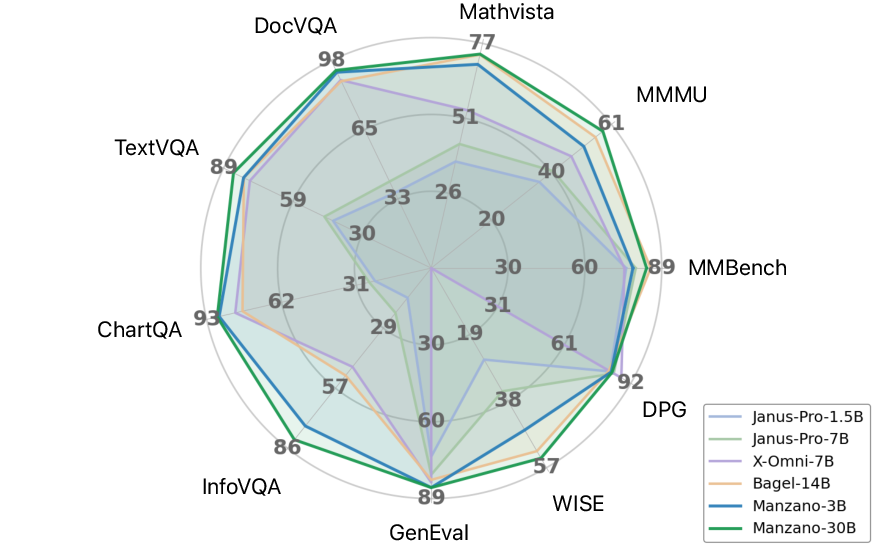
- On image understanding, Manzano is state-of-the-art among unified models and competitive with specialist models built only for understanding, especially on text-rich benchmarks like reading documents and charts.
- On image generation, Manzano follows prompts well and produces high-quality images, competitive with larger unified systems.
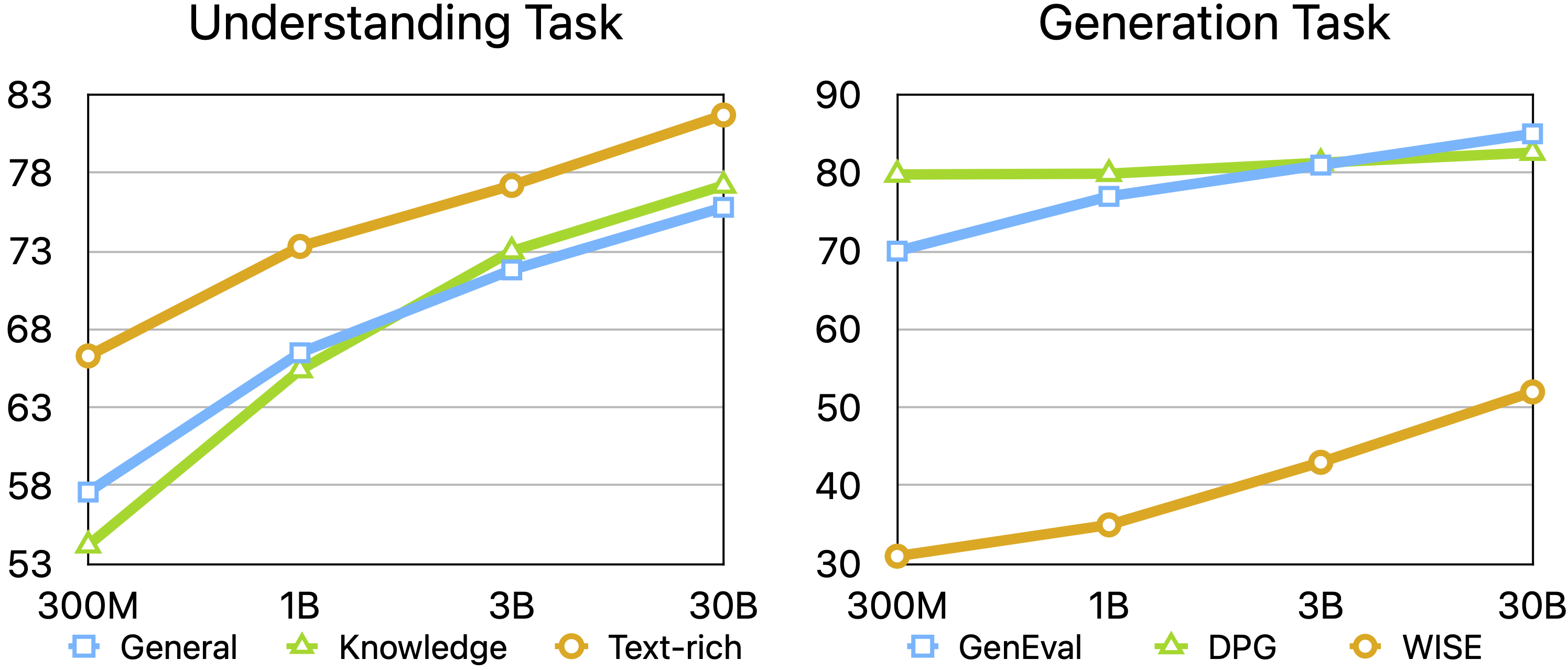
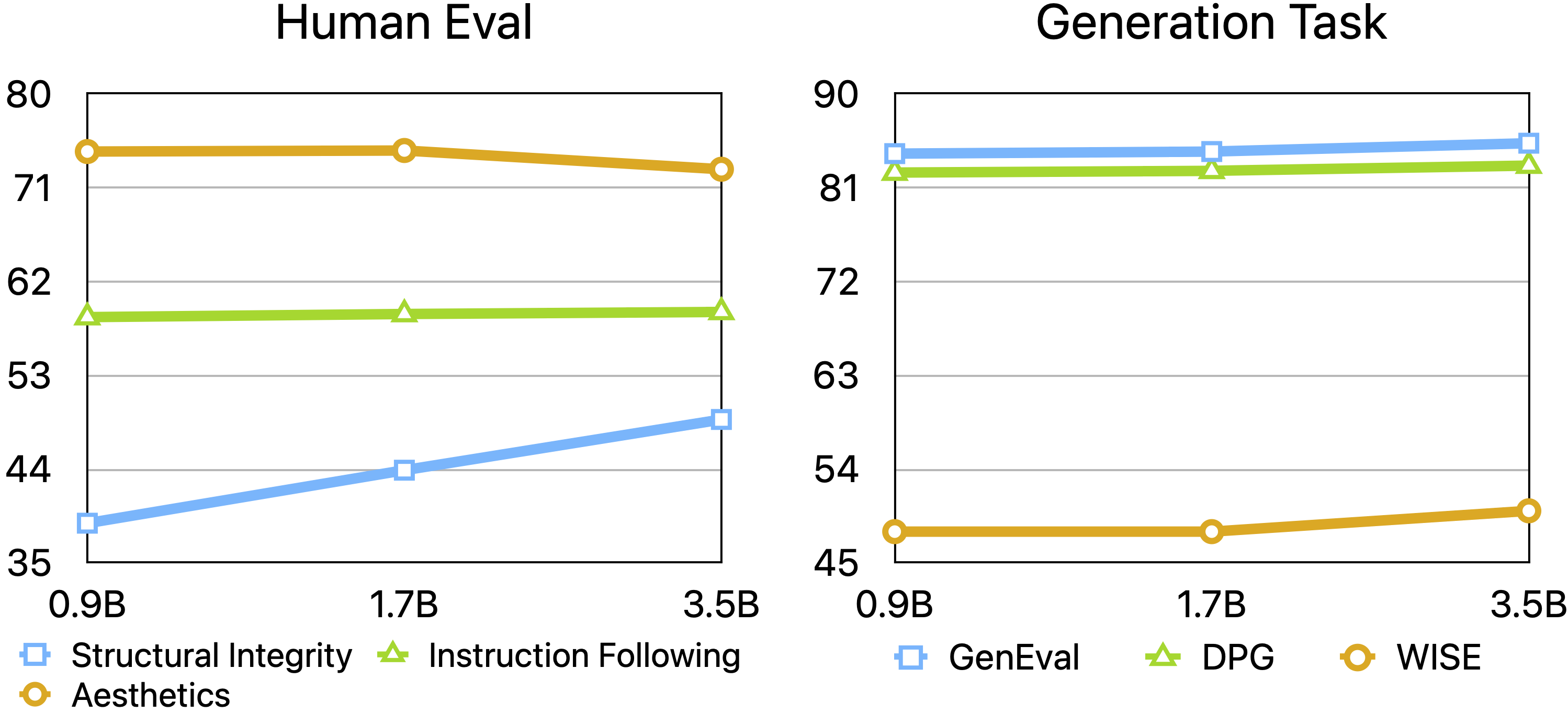
- Scaling helps both tasks: Making the LLM bigger (from 300M to 30B parameters) consistently improves understanding and generation. Making the diffusion decoder bigger improves how well images hold their structure, too.
- Minimal trade-offs: Joint training on both tasks didn’t cause major conflicts. The model stayed good at both.
Why it matters:
- Unified models usually suffer when they try to do both understanding and generation. Manzano shows a simple way to avoid that by keeping image meanings consistent across tasks.
- This opens the door to AI systems that can read complex visuals (like homework diagrams or forms), discuss them, and also create accurate and detailed images from instructions—all in one model.
What could this change in the future?
Manzano’s approach could:
- Make AI assistants better at practical tasks: reading documents, answering questions about charts, doing math with diagrams, and creating illustrations that match detailed instructions.
- Improve creativity tools: more reliable text inside images, better layout and structure, and stronger world-knowledge grounding in generated pictures.
- Simplify building large AI systems: its clean design helps scale both the “brain” (LLM) and the “artist” (diffusion decoder) independently.
- Encourage better benchmarks: some current tests may be too easy to “game,” so the community might develop new ways to measure real-world visual reasoning and creation.
In short, Manzano shows that a single, simple, scalable model can both understand and create visual content without sacrificing either skill—by using a clever hybrid way of turning images into tokens the AI can reason about.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point highlights what is missing or uncertain and suggests a concrete direction for future work.
- Data transparency and reproducibility:
- The paper relies heavily on in-house licensed/synthetic data (e.g., 1B T2I pairs, re-captioned corpora, internal human eval set), but does not release datasets, prompts, or detailed sampling/filters, hindering reproducibility and fair comparison.
- Potential train–test contamination is not audited (especially for widely used VQA and GenEval-style prompts); no data deduplication or leakage analysis is reported.
- Exact distributions for pretraining/continued pretraining mixtures, captioner models, and prompt sources (beyond named datasets) are under-specified; re-captioning quality controls and failure modes are not documented.
- Safety, robustness, and fairness:
- No assessments of harmful content generation, bias/fairness across demographics, or safety policy adherence (refusal behavior, jailbreak robustness) are provided.
- Multilingual robustness is largely untested beyond mentioning multilingual OCR in training; generation and understanding benchmarks are predominantly English.
- No adversarial robustness, input corruption robustness, or long-tail/OOD generalization studies for either understanding or generation.
- Evaluation coverage and methodology:
- Human evaluation uses an internal 800-prompt set with 3 raters but lacks inter-rater agreement statistics, public release of prompts/annotations, or calibration protocols; generalizability is unclear.
- Important unified-model abilities (multi-turn mixed image–text generation, iterative/image editing, layout-controllable generation, negative prompts, compositional negation) are not benchmarked.
- The paper itself notes saturation on GenEval/DPG; stronger, discriminative benchmarks for compositional reasoning, spatial logic, and instruction following at scale are not proposed or implemented.
- No quantitative text-in-image accuracy (OCR of generated text) or typography fidelity metrics, despite claims of improved text rendering.
- Architectural and training ablations left unexplored:
- Vision encoder scale is fixed; effects of scaling or updating the encoder during unified training (vs freezing) are not studied.
- The hybrid tokenizer design space is under-ablated: STC compression factor, codebook size (64K), FSQ vs alternative quantizers, discrete/continuous token lengths, and adapter architectures are not systematically evaluated.
- The weighting between text and image losses (1:0.5) and mixture ratios (e.g., 40/40/20; 41/45/14) are not ablated for sensitivity; optimality and robustness to data shifts remain unknown.
- The tokenizer pre-alignment uses a small 300M LLM and random adapter sampling; the sampling strategy, adapter selection probabilities, and the transferability of the learned alignment to larger LLMs (3B/30B) are not validated.
- Freezing the vision encoder and discrete adapter to keep a fixed codebook may limit adaptability; the trade-off between fixed vocabulary stability and potential gains from joint end-to-end finetuning is untested.
- Diffusion image decoder uncertainties:
- Aesthetic degradation observed when scaling the diffusion decoder is acknowledged but not diagnosed; no analysis of conditioning strength, objective (flow-matching variants), guidance, or architecture choices that trade off structure vs aesthetics.
- The decoder is trained on ground-truth tokens but used with LLM-predicted tokens at inference; exposure bias and train–test mismatch are not quantified or mitigated (e.g., scheduled sampling, noisy-token training).
- Resolution scaling behavior is not specified: how the number of LLM image tokens scales with output resolution (256–2048), and the impact on latency and token budgets, remains unclear.
- Scaling laws and compute efficiency:
- The 30B LLM is trained on fewer tokens than smaller models; scaling claims may be confounded by unequal compute/token budgets. No controlled scaling-law analysis (equalized FLOPs/tokens) is provided.
- End-to-end latency, memory footprint, and throughput for unified inference (LLM + diffusion) across resolutions and model sizes are not reported; deployment feasibility on resource-constrained devices is unknown.
- The interplay between LLM scale, tokenizer granularity, and decoder capacity is not modeled; guidelines for jointly scaling components to maximize quality per FLOP are missing.
- Generalization and transfer:
- Cross-domain generalization (e.g., medical, remote sensing, engineering drawings, scientific figures beyond charts) and extreme text-rich cases (dense small fonts, noisy scans) are not separately assessed.
- Transfer to additional modalities (audio, video) or tasks (video generation/editing, temporal reasoning) is not explored, despite the purported simplicity/scalability of the framework.
- Few-shot/zero-shot adaptation abilities (e.g., new styles, rare concepts, new languages/scripts) and continual learning behavior with evolving codebooks are untested.
- Interpretability and controllability:
- The semantic interpretability of discrete image tokens (e.g., token–concept alignment, compositionality) is not examined; no diagnostics link token sequences to generated attributes/layouts.
- Controllability beyond prompt text (spatial/layout constraints, color palettes, typography specs, safety constraints) is not addressed; no APIs or conditioning mechanisms are presented.
- The model’s capability for image-conditioned generation (e.g., reference-based styling, visual inpainting/outpainting) using the same hybrid tokenizer is not evaluated.
- Comparative baselines and fairness:
- Several baselines are internal reproductions (e.g., MagViT-2) or reported with caveats (daggered numbers), which may bias comparisons; standardized, reproducible baselines with released configs are needed.
- Unified vs specialist comparisons exclude latency/quality trade-offs or cost-normalized quality; practical advantages of unification at equal compute are unquantified.
- Ethical and governance aspects:
- No discussion of copyright/attribution for training images, watermarking or provenance for generated content, or compliance mechanisms for responsible deployment.
- The impact of large-scale synthetic captioning on factuality and cultural bias is not audited; how re-captioning influences WISE/world-knowledge grounding is unclear.
- Open technical questions:
- How does the hybrid tokenizer’s shared semantic space mediate conflicts when tasks diverge (e.g., photorealism vs diagram parsing), and can dynamic adapter routing or MoE adapters further reduce conflict without bloating parameters?
- Can jointly finetuning the vision encoder and adapters after initial freezing improve alignment without destabilizing the codebook, perhaps via soft codebook updates or learned token remapping?
- What is the optimal balance between semantic token predictability (for AR LLMs) and pixel-level flexibility (for diffusion) to maximize both instruction following and aesthetics?
- Can curriculum strategies or multi-stage targets (layout→semantics→appearance) reduce GenEval/DPG saturation and improve compositional reasoning beyond data scaling?
These gaps suggest concrete next steps: release reproducible assets and safety audits, extend and standardize evaluations (especially for editing, layouts, multilingual generation, and OCR-of-generated-text), perform thorough ablations on tokenizer and training mixtures, quantify compute/latency trade-offs, and investigate end-to-end finetuning and decoder conditioning strategies to recover aesthetics while preserving structure.
Glossary
- autoencoder-style tokenizer: An image tokenizer based on an autoencoder architecture that compresses images into discrete codes. "an autoencoder-style tokenizer."
- auto-regressive (AR) approach: A modeling paradigm that predicts the next token in a sequence conditioned on previous tokens. "Manzano is a multimodal LLM (MLLM) that unifies understanding and generation tasks using the auto-regressive (AR) approach."
- autoregressive decoding: Generating outputs token-by-token, each conditioned on previously generated tokens. "using autoregressive decoding for text and an embedded diffusion process for images."
- autoregressive LLM: A LLM that generates outputs sequentially by predicting the next token. "A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels."
- chain-of-thought (CoT): An approach where models explicitly generate intermediate reasoning steps. "vision chain-of-thought (CoT)"
- CLIP: A vision-LLM that learns joint image-text representations via contrastive learning. "Typical vision encoders include CLIP"
- codebook: The set of discrete codes used by a quantizer to represent continuous features. "codebooks (64K in our experiments)"
- code indices: Discrete identifiers that reference entries in a quantization codebook. "Representing images as discrete code indices lets the LLM use the same AR next-token learning strategy as text"
- conditional flow matching: A training objective that guides a model to transform noise into data conditioned on inputs. "with a conditional flow matching objective."
- continuous embeddings: Vector representations with continuous values used as inputs to neural networks. "produce continuous embeddings for image-to-text understanding"
- cross-entropy loss: A standard loss function for classification and next-token prediction tasks. "The LLM then computes a cross-entropy loss on these image tokens only."
- decoupled LLM-diffusion approach: A design that separates language understanding in an LLM from image synthesis in a diffusion model. "the decoupled LLM-diffusion approach"
- diffusion decoder: A module that generates images by denoising, conditioned on semantic tokens or embeddings. "with an auxiliary diffusion decoder subsequently translating the image tokens into pixels."
- diffusion image decoder: A diffusion-based image generator conditioned on tokens or embeddings. "we leverage a diffusion image decoder"
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion-based generative modeling. "Diffusion Transformers (DiTs)"
- DiT-Air architecture: A DiT variant with layer-wise parameter sharing to reduce parameters while maintaining performance. "DiT-Air architecture"
- discrete adapter: A module that quantizes visual features into discrete tokens suitable for autoregressive modeling. "a discrete adapter, which also starts with the STC compression step but further quantizes the features"
- discrete image tokens: Quantized tokens representing images for autoregressive generation. "Auto-regressive generation usually prefers discrete image tokens"
- dual-encoder: A setup using separate encoders/tokenizers for understanding and generation tasks. "uses a dual-encoder strategy"
- embedding table: A lookup table mapping token IDs to continuous vector embeddings. "We extend the LLM embedding table with 64K Image tokens"
- finite scalar quantization (FSQ): A simple, scalable quantization method that maps continuous values to a finite set of discrete levels. "finite scalar quantization (FSQ)"
- flow-matching pipeline: A method that learns a transformation from noise to data via flow matching. "a flow-matching pipeline"
- gated cross-attention: A mechanism where attention across modalities is modulated by learnable gates. "gated cross-attention layers"
- hybrid AR-diffusion approach: A system combining autoregressive text modeling with diffusion-based image generation. "the hybrid AR-diffusion approach"
- hybrid image tokenizer: A tokenizer producing both continuous embeddings (for understanding) and discrete tokens (for generation) from a shared encoder. "hybrid image tokenizer"
- image splitting: A data processing technique that segments images into parts for training or evaluation. "with image splitting ... enabled."
- interleaved image-text data: Datasets where images and text appear in mixed sequences within documents. "interleaved image-text data"
- InternViT: A vision transformer variant used as a backbone for visual encoding. "InternViT"
- latent diffusion methods: Diffusion models that operate in a compressed latent space rather than pixel space. "Latent diffusion methods"
- latent domain: The feature space produced by an encoder where generation or processing occurs. "in the latent domain"
- latent space: A compressed representation space learned by an autoencoder or similar model. "in the latent space of a pre-trained variational autoencoder (VAE)"
- layer-wise parameter-sharing: A technique where layers share parameters to reduce model size. "layer-wise parameter-sharing strategy"
- Mixture-of-Experts (MoE): An architecture where multiple expert sub-networks are selectively activated per input. "Mixture-of-Experts (MoE)"
- Mixture-of-Transformers (MoT): A design that allocates different transformer pathways to different tasks or modalities. "Mixture-of-Transformers (MoT)"
- MMDiT: A diffusion transformer variant used for image generation tasks. "MMDiT model"
- Multi-Layer Perceptron (MLP): A feedforward neural network used for projections or connectors. "Multi-Layer Perceptron (MLP) projection"
- Multimodal LLM (MLLM): A LLM that processes and generates across multiple modalities, such as text and images. "Multimodal LLMs (MLLMs)"
- Optical Character Recognition (OCR): Technology that converts text in images into machine-readable text. "multilingual OCR"
- Q-Former: A transformer-based module used to align visual features with LLMs. "introduces the Q-Former"
- quantized tokenizer: A tokenizer that maps continuous features to discrete codes for autoregressive modeling. "a quantized tokenizer like VQ-VAE"
- SigLIP: A model similar to CLIP that aligns images and text using a sigmoid loss. "SigLIP"
- Spatial-to-Channel (STC) layer: A layer that reduces spatial tokens by folding spatial dimensions into channels. "Spatial-to-Channel (STC) layer"
- spatial compression ratio: The factor by which spatial dimensions are reduced during tokenization. "a spatial compression ratio of 8"
- supervised fine-tuning (SFT): Training on labeled instruction data to refine model behavior. "supervised fine-tuning (SFT) stage"
- unified AR objective: A single autoregressive loss applied across tasks and modalities. "Unified AR objective."
- unified multimodal LLM: A single model that jointly performs both image understanding and image generation. "a single, unified multimodal LLM"
- unified semantic tokenizer: A tokenizer that produces both continuous and discrete representations within a common semantic space. "we introduce a unified semantic tokenizer"
- variational autoencoder (VAE): A generative model that learns a latent distribution for reconstructing inputs. "variational autoencoder (VAE)"
- Vision Transformer (ViT): A transformer architecture adapted for image encoding. "vision transformer (ViT)"
- visual tokenization: The process of converting images into sequences of tokens for modeling. "visual tokenization."
- VQ-VAE: A vector-quantized variational autoencoder used to discretize latent features. "VQ-VAE"
- World Knowledge-Informed generation: Image synthesis guided by attributes grounded in real-world knowledge. "WISE for World Knowledge-Informed generation."
Collections
Sign up for free to add this paper to one or more collections.