- The paper introduces Tar, a unified multimodal framework that uses a novel Text-Aligned Tokenizer to align image tokens with LLM embeddings.
- It demonstrates strong performance in both visual understanding and high-fidelity image generation, outperforming models at the 1.5B/7B scale.
- Ablation studies confirm that initializing the visual codebook with LLM embeddings significantly boosts multimodal learning efficiency.
Tar: Unifying Vision and Language through Text-Aligned Representations
This paper introduces Tar, a multimodal LLM framework designed to unify visual understanding and generation through a shared discrete semantic representation. The core innovation is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a LLM's vocabulary. This approach aims to provide a unified interface for cross-modal input and output, eliminating the need for modality-specific designs and facilitating advanced multimodal reasoning.
Text-Aligned Tokenizer (TA-Tok)
TA-Tok is central to aligning visual representations with the LLM's latent space. The process involves encoding an input image I into a continuous vector zI=E(I) using a visual encoder E. This vector is then mapped to the closest vector in a codebook C through a quantization process:
zq=argminc∈C∥zI−c∥2
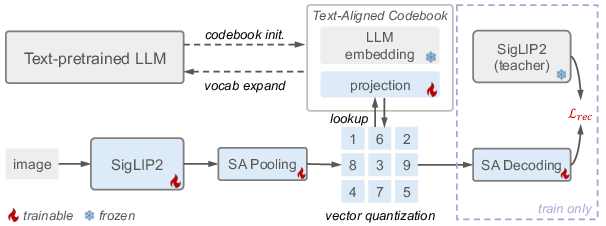
Figure 1: An input image is first encoded into continuous tokens using a SigLIP2 vision model.
Traditional VQ codebooks are randomly initialized; however, TA-Tok initializes the VQ codebook using token embeddings from a pre-trained LLM, denoted as E∈RK×D, and a projection matrix W∈RD×D. The codebook C∈RK×D is defined as:
C=EW={Ew1,Ew2,…,EwD}
This ensures that each codebook entry is a projected version of a corresponding LLM token embedding, thereby grounding the visual codebook in the LLM's latent space. The paper also introduces Scale-Adaptive Pooling (SAP) and Decoding (SAD) to accommodate varying needs for visual details across different tasks. TA-Tok is trained with a combination of feature reconstruction loss Lrec and codebook losses zI=E(I)0. The reconstruction loss encourages semantic alignment, defined as:
zI=E(I)1
where zI=E(I)2 and zI=E(I)3 are features from SAD and a SigLIP2 teacher, respectively.
Generative De-Tokenizer
To generate high-quality images from the quantized outputs of TA-Tok, the paper introduces a Generative De-Tokenizer with two variants: an autoregressive de-tokenizer (AR-DTok) and a diffusion de-tokenizer (Dif-DTok). AR-DTok formulates image decoding as an autoregressive generation task. Given image tokens zI=E(I)4 from a VQVAE encoder and the parameters zI=E(I)5 of AR-DTok, the loss function is:
zI=E(I)6
Dif-DTok uses quantized tokens zI=E(I)7 as conditioning input to a diffusion model zI=E(I)8 parameterized by zI=E(I)9. The training objective is:
E0

Figure 2: Qualitative comparison of different representations (left) and de-tokenizers (right).
Unified Multimodal Modeling
Built on TA-Tok and Generative De-Tokenizers, Tar unifies visual understanding and generation using a simple autoregressive objective. The LLM's text embedding matrix E1 is expanded with a visual token set E2, using the Text-Aligned Codebook E3 as visual embeddings. Tar is trained with the standard Cross-Entropy loss over a mixed sequence of text and visual tokens. Given a target sequence E4 and model parameter E5, the loss is:
E6
Experimental Results
The Tar model demonstrates strong visual understanding performance across a range of benchmarks. Notably, the 1.5B model surpasses most understanding-only models and unified models at the 1.5B/7B scale. The 7B model matches the performance of Janus-Pro-7B, a state-of-the-art model with continuous visual tokens. In visual generation, Tar achieves strong performance on both GenEval [Ghosh et al., 2023] and DPG Bench.

Figure 3: Text-to-Image Generation Results, using Tar-7B and a 1024 pixel de-tokenizer.
Ablation Studies
Ablation studies validate the effectiveness of TA-Tok. Initializing LLM embeddings with the TA Codebook leads to better performance compared to random initialization. The generative de-tokenizer design also proves effective, with AR-DTok performing well across resolutions and scales, and Dif-DTok quickly adapting to generate high-fidelity images due to its pre-trained diffusion backbone. The design of SAP allows the model to produce multi-granularity visual tokens where visual understanding tasks benefit from more tokens to capture image details, but longer visual sequences do not significantly improve image generation performance. The unified pretraining tasks, including image-to-image (IE7I) and text-image-to-image (TIE8I), further improve generation performance, narrowing the gap between understanding and generation.
Conclusion
This paper presents Tar, a unified model that uses a shared, discrete, text-aligned representation to bridge visual understanding and generation. The alignment of image tokens with LLM embeddings via TA-Tok, along with scale-adaptive tokenization and generative de-tokenizers, enables strong performance across both tasks without modality-specific designs. This approach demonstrates that a fully discrete, semantic representation can facilitate efficient and effective multimodal learning.

