Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
Abstract: When do machine learning systems fail to generalize, and what mechanisms could improve their generalization? Here, we draw inspiration from cognitive science to argue that one weakness of machine learning systems is their failure to exhibit latent learning -- learning information that is not relevant to the task at hand, but that might be useful in a future task. We show how this perspective links failures ranging from the reversal curse in language modeling to new findings on agent-based navigation. We then highlight how cognitive science points to episodic memory as a potential part of the solution to these issues. Correspondingly, we show that a system with an oracle retrieval mechanism can use learning experiences more flexibly to generalize better across many of these challenges. We also identify some of the essential components for effectively using retrieval, including the importance of within-example in-context learning for acquiring the ability to use information across retrieved examples. In summary, our results illustrate one possible contributor to the relative data inefficiency of current machine learning systems compared to natural intelligence, and help to understand how retrieval methods can complement parametric learning to improve generalization.

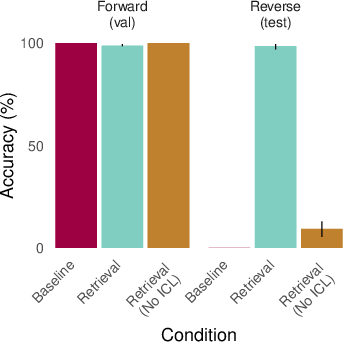
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences”
What this paper is about (overview)
This paper asks a simple question: Why do today’s AI systems often fail to use what they’ve learned in new, slightly different situations—something humans do all the time? The authors argue that one big reason is that most AI systems don’t do “latent learning”: learning information that isn’t needed right now, but could be useful later. They show that adding an “episodic memory” (a way to retrieve specific past experiences) helps AI use what it has already seen in more flexible ways, much like how human memory supports quick problem solving.
The main questions the paper tries to answer
The paper focuses on a few clear questions in kid-friendly terms:
- When do AI systems miss “hidden” or indirect information that’s sitting inside their training data?
- Why do AIs often know how to solve something only when the helpful facts are right in front of them, but not when those facts are missing from the prompt?
- Can giving an AI a way to recall specific past experiences (episodic memory) fix this?
- What ingredients are needed for retrieval to actually help (for example, does the AI need to practice learning from examples inside the prompt)?
How the researchers tested their ideas (methods, explained simply)
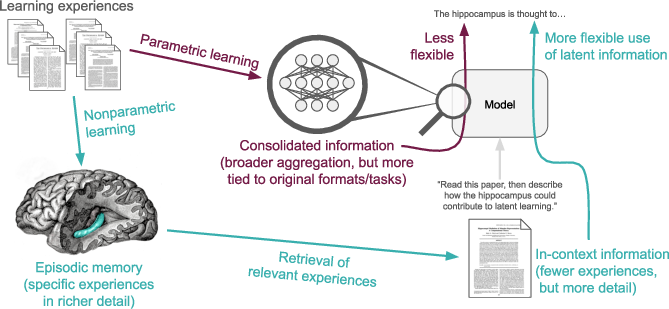
Think of two kinds of learning:
- Parametric learning: what the AI “burns into its brain wiring” during training (its weights).
- Episodic memory and retrieval: keeping a scrapbook of past experiences and pulling out the right pages when needed.
The authors ran several tests (benchmarks) where an AI could succeed only if it could use information that was present in training but not directly trained for the test task:
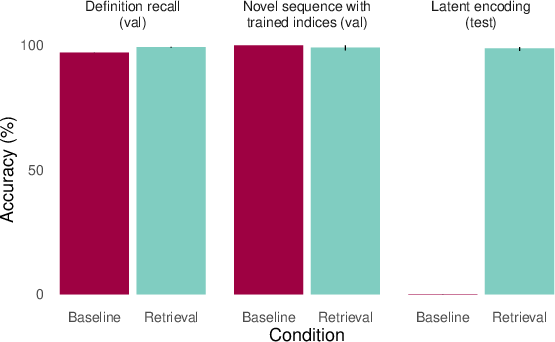
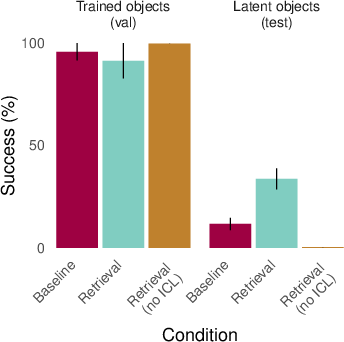
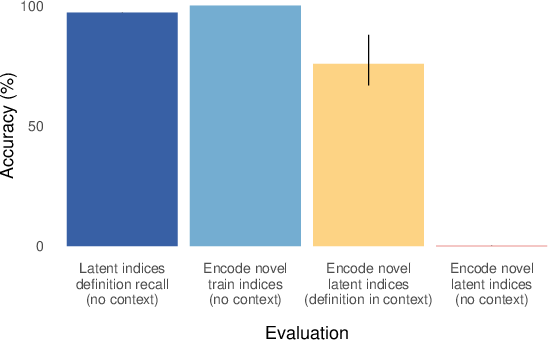
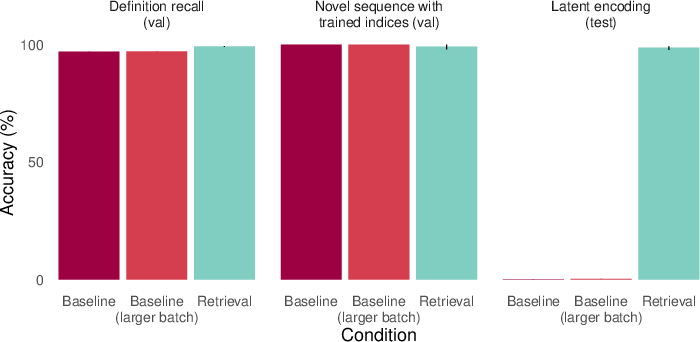
- Codebooks: Like secret codes. The AI sees a dictionary of symbol→symbol mappings (the codebook) and examples of encodings. But for some codes, certain pairs are never used in training encodings. At test time, the AI must encode using those “unused” pairs. This checks whether the AI learned the “latent” parts of the codebook.
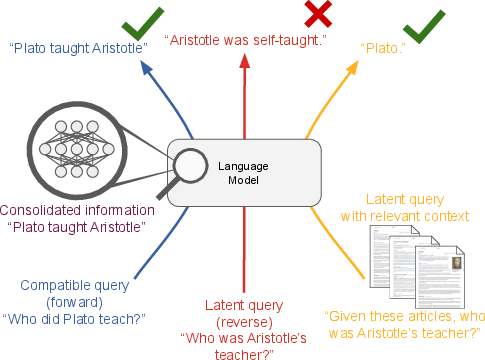
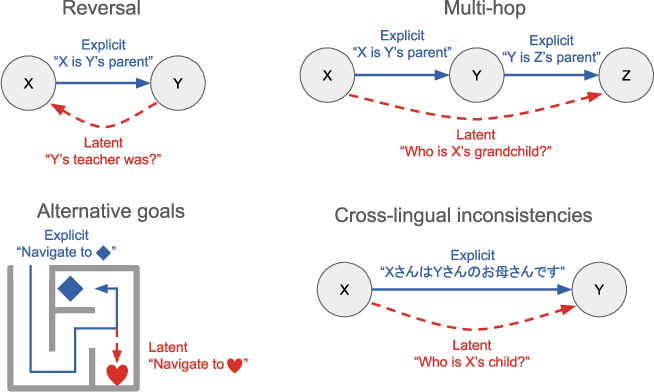
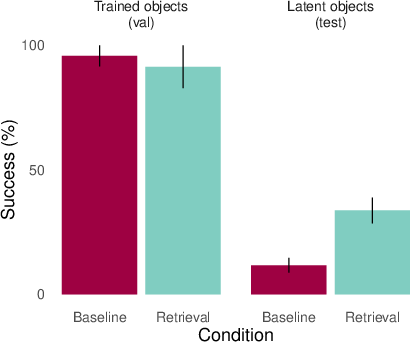
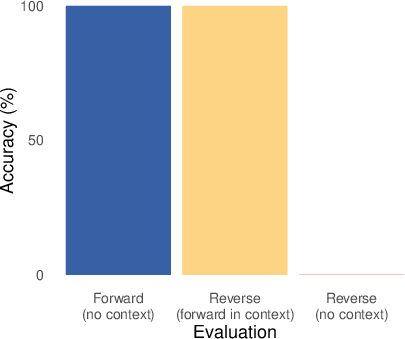
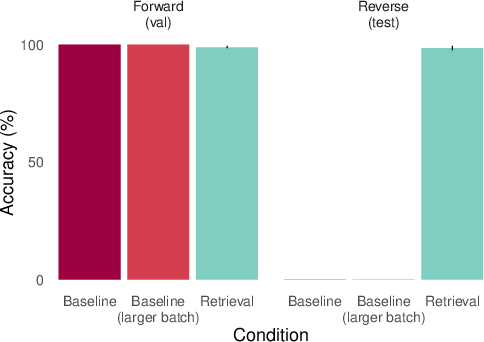
- Simple reversals: If the AI learns “Plato taught Aristotle,” can it also answer “Who taught Aristotle?” without seeing the sentence in the prompt? Humans can do this easily; many models can only do it when the original sentence is present in context.
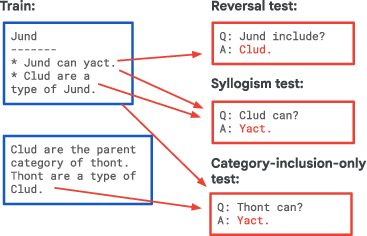
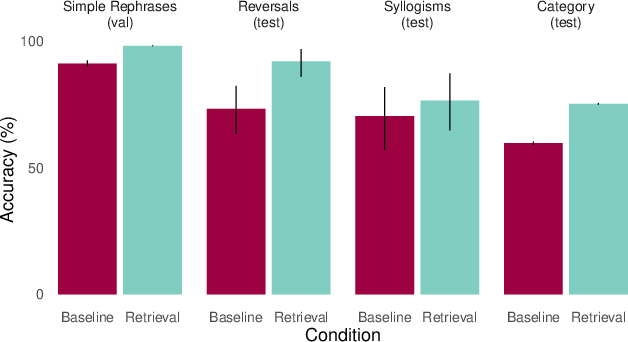
- Semantic structure: More natural sentences about categories and facts (like animals and their features). Tests include reversals, two-step logic (syllogisms), and tougher cases where the obvious clues are removed. This checks whether the model can reuse facts in new ways.
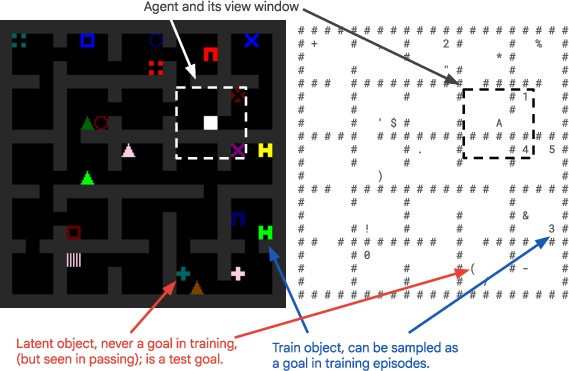
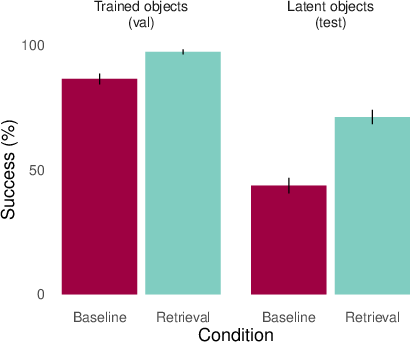
- Gridworld navigation (mazes): Like the classic rat-in-a-maze studies. An agent learns to navigate to some objects (goals) but often passes by other objects that are never asked for. Later, can it go to those “latent” objects it saw during training but was never told to reach? This was tested in two ways:
- RL (reinforcement learning) from pixels (playing to get rewards).
- BC (behavioral cloning), learning from example paths.
Key idea tested: Oracle retrieval. Instead of hoping the AI figures out what to remember, the researchers “hand” the AI a relevant past example (or a few) at train and test time—like giving it the right scrapbook page to read inside its prompt. This is a clean way to check if memory retrieval could help, without also testing whether the AI can pick the right memory by itself.
They also examined an important ingredient: in-context learning (ICL). That’s when the AI learns how to use examples shown inside the prompt to solve the current task. The authors tested whether having training sequences that explicitly contain “learn-and-apply in the same context” makes retrieval more effective.
What they found (main results)
Across all tasks, a pattern appeared:
- Baseline AIs often fail at latent learning.
- They can remember facts (e.g., the codebook definitions).
- They can use those facts if the helpful information is included in the prompt (in-context).
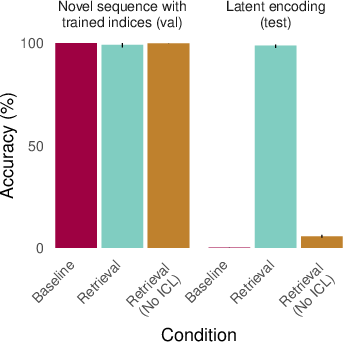
- But they usually fail when asked to use that information without seeing it again. Example: They can answer “Who taught Aristotle?” only if “Plato taught Aristotle.” is in the prompt; otherwise, they struggle—even though they “learned” the original fact during training.
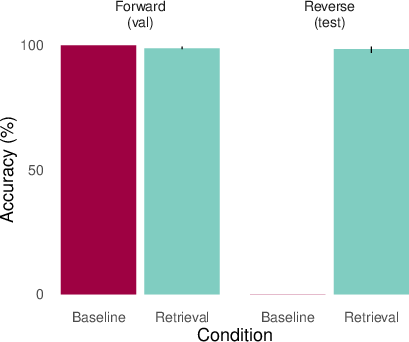
- Adding retrieval (episodic memory) helps a lot.
- When the AI is given a relevant past example (oracle retrieval), it suddenly succeeds on many of these “latent” tests. It’s like reminding it of the right page from its scrapbook so it can use that information on the spot.
- Associations can sometimes mask the problem.
- In the semantic structure tests, if there are strong associative clues (e.g., birds often have wings, so “eagle has wings” is easy to guess), even baseline models do okay. When these clues are removed, retrieval makes a clearer difference.
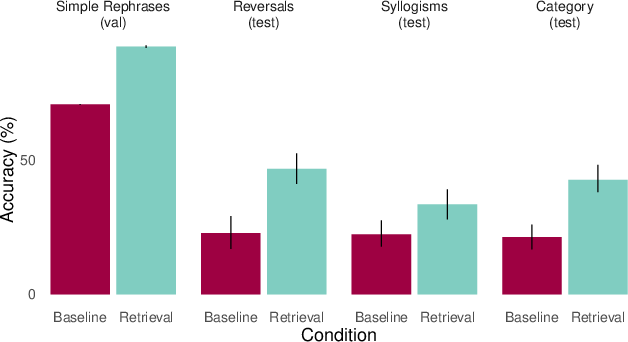
- The AI has to practice learning from examples inside the prompt.
- Retrieval works best when the AI has already learned how to learn from examples shown in-context. Without training that encourages in-context learning, retrieval helped less. In other words, the AI not only needs the right memory—it needs to know how to read and use it.
- In mazes, retrieval helps but it’s still hard.
- For the navigation tasks, retrieval improved performance on “latent goals” (objects never used as targets during training) in both RL and BC settings, but the task remained challenging. Planning long action sequences from retrieved memories is harder than answering a single question.
Why this matters (implications and impact)
- Better generalization with less data: Humans often learn things that aren’t immediately useful but pay off later. Giving AIs an episodic memory and good retrieval moves them closer to that human-like efficiency.
- Rethinking how we build AI: Instead of storing everything only in weights (parametric learning), we should combine it with strong memory systems (like Retrieval-Augmented Generation) that can bring the right experiences into the prompt when needed.
- Practical design tip: For retrieval to shine, train models with tasks that teach them to learn from in-prompt examples (in-context learning). Don’t just add a memory—teach the model how to use it.
- Toward more human-like intelligence: The paper connects AI to how the brain may work—fast episodic memory (hippocampus-like) plus slower, general knowledge—suggesting a roadmap for building AIs that can flexibly reuse what they’ve experienced.
In short: Today’s AIs often don’t “latent learn” like we do. But giving them a way to recall specific past experiences—and training them to use those memories in context—can dramatically improve how flexibly they use what they have already seen.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- Oracle retrieval assumption: the work presumes perfect access to at least one highly relevant episode; it does not develop or evaluate a learned retrieval system (indexing, query formulation, negative sampling, or approximate search) that would work under realistic noise and recall/precision constraints.
- Retrieval robustness: no analysis of performance under retrieval errors, conflicting episodes, higher distractor ratios, partial matches, or adversarially misleading memories.
- Write policy and memory management: the paper does not address what to store, when to store, how to compress or evict, and how to prevent memory bloat or redundancy over long horizons.
- Consolidation via replay: while motivated by complementary learning systems, the work does not study how episodic memories should be replayed to parametric networks, which experiences to prioritize, or how to avoid catastrophic interference during consolidation.
- Test-time-only retrieval: the paper always enables retrieval at both train and test; it does not isolate whether exposure to retrieval only at inference suffices, how it compares to training-with-retrieval, or the dynamics of zero-shot adoption of memory at test.
- Sensitivity to the quantity/quality of ICL scaffolding: the findings hinge on “within-example ICL” being present in training; it remains open how much, what kinds, and how diverse such scaffolding needs to be, and how to induce it in naturally occurring data.
- Alternative ways to teach memory use: the paper does not compare retrieval to other mechanisms that could teach flexible reuse (e.g., self-augmentation, planning traces, program induction, tools, synthetic counterfactuals) under equal compute and data budgets.
- Scaling laws for latent learning: no characterization of how latent generalization scales with model size, data size, memory size, or retrieval quality; no sample-compute trade-off curves to quantify efficiency gains.
- Parametric ceilings: it is unclear whether larger models, longer training, different objectives, or architectural changes (e.g., memory layers, latent variable models, structured decoders) could close some latent-learning gaps without retrieval.
- Formal theory is incomplete: the “sketch” leaves open a precise definition and taxonomy of latent learning, necessary and sufficient conditions, lower bounds, and provable guarantees for when parametric learning must fail vs can succeed.
- Task generality: benchmarks are mostly synthetic or stylized; the paper does not test real-world settings where latent learning is critical (e.g., cross-lingual transfer, multi-hop QA on long corpora, code reuse across repos, scientific discovery).
- Breadth of latent phenomena: only a subset of latent tasks is studied (reversals, syllogisms, alternative navigation goals); broader forms (analogy, abstraction, causal/temporal inversion, counterfactual planning, compositional tool reuse) remain untested.
- Gridworld performance remains low: despite retrieval, latent-object navigation is far from ceiling; the work does not analyze bottlenecks (e.g., long-horizon credit assignment, memory chaining, partial observability) or propose remedies.
- RL memory interface: RL results use cached memory states (not raw episodes) but there is no ablation of different interfaces (state vs text, embeddings vs tokens, learned read heads vs prepend), nor of how many and which episodes to retrieve per step.
- Retrieval granularity: no study of chunk sizing (sentence vs document vs trajectory segments), temporal segmentation in RL, or how retrieval context length and ordering affect latent generalization.
- Conflicts and versioning: the system’s behavior under inconsistent memories (e.g., facts that changed over time, environment alterations) is not examined; strategies for disambiguation and recency priors are unspecified.
- Negative transfer and spurious association: the risk that retrieval encourages shortcut exploitation or introduces harmful biases is not measured; there is no calibration or reliability analysis under memory-induced distribution shift.
- Compute and latency costs: the paper does not quantify the runtime/memory overhead of retrieval, indexing, and longer contexts, nor compare overall cost-effectiveness vs stronger parametric baselines or data augmentation.
- Privacy and safety: storing and retrieving episodic data raises privacy, IP leakage, and safety issues; policies for redaction, access control, and safe memory usage are not discussed.
- Evaluation breadth and rigor: small numbers of runs in RL, limited statistical power, and absence of standardized baselines (e.g., leading RAG, kNN-LM, memory-augmented networks) leave open the strength and generality of claims.
- Pretraining effects: all major experiments train from scratch; how large-scale pretraining (text, code, multimodal) interacts with latent learning and retrieval remains unexamined.
- Interaction with instruction tuning/test-time training: the paper does not compare against strong baselines such as TTT, LoRA-on-the-fly, or retrieval-tuned adapters that might also unlock latent knowledge.
- Objective design: models are trained with reconstruction-style objectives; it is an open question whether alternative losses (contrastive, sequence-to-graph, planning objectives) better encode latent structure parametrically or improve memory use.
- Memory selection learned end-to-end: the work stops short of training retrieval and usage policies jointly (e.g., differentiable retrieval, learned querying, credit assignment to memories), which is likely crucial in realistic settings.
- Neurocognitive grounding: the hippocampal analogy is motivating but not tested; predictions about human behavior (e.g., effects of hippocampal impairment on analogous tasks) and neural signatures of “latent retrieval” remain to be validated.
- Failure mode diagnostics: the paper shows aggregate gaps but does not provide mechanistic analyses (e.g., attention patterns, probing, causal tracing) to pinpoint why parametric models fail or how retrieval specifically enables success.
- Generalization under multilingual/cross-domain shifts: though cited as motivating cases, cross-lingual and cross-domain latent learning are not experimentally evaluated; how retrieval sources need to be curated across languages and domains is unknown.
- Multi-hop memory composition: there is no evaluation of tasks requiring chaining across multiple retrieved episodes (beyond single-hop reversals); robustness and planning over memory graphs remain open.
- Lifelong operation: continual accumulation of episodes, online indexing, and long-run stability (forgetting, drift, compaction) are not addressed; practical recipes for lifelong latent learning are missing.
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting existing retrieval systems (e.g., RAG) and workflows to explicitly support latent learning—i.e., making relevant prior episodes available in context so models can flexibly reuse experiences beyond the original training task or format.
- Latent-aware RAG for knowledge work (software)
- Description: Enhance retrieval pipelines to fetch episodes that make implicit relationships explicit (e.g., reverse relations, multi-hop chains, alternative goals), not just documents that contain verbatim answers. Pair prompts with retrieved exemplars that demonstrate the needed transformation (e.g., forward relation + a reversal exemplar).
- Sector: Software, legal, compliance, research
- Tools/workflows: Reranking tuned for “format diversity,” episodic stores of prior Q&A, chain-of-thought traces; prompt templates that include minimal in-context learning (ICL) demonstrations
- Assumptions/dependencies: High-quality relevance retrieval; sufficient context length; storage of episodes and permission to reuse them; presence of ICL-supporting sequences so the model can learn to use retrieved info across examples
- Consistency and reconciliation checks in knowledge graphs (software/enterprise)
- Description: Use retrieval to surface episodes that contain forward facts when answering reversed queries (and vice versa), enabling cross-checking and automatic generation of inverse edges (e.g., “X is Y’s child” → “Y is X’s parent”).
- Sector: Enterprise data platforms, search
- Tools/workflows: Graph-RAG, inverse-edge generators, audit dashboards
- Assumptions/dependencies: Schema alignment; robust entity resolution; careful handling of contradictions
- Code assistants that execute functions and their inverses (software)
- Description: Retrieve usage examples and unit tests for functions seen in training and use ICL to execute them at test time (e.g., learned function
encode()→ inferdecode()via reversed mapping). Inspired by the “codebooks” and function execution findings. - Sector: Software engineering
- Tools/workflows: Example-based code search; episodic repositories of traces/tests; prompt scaffolds that include both forward and reverse examples
- Assumptions/dependencies: Codebase coverage; correct function semantics; limits of model’s sandbox/execution
- Description: Retrieve usage examples and unit tests for functions seen in training and use ICL to execute them at test time (e.g., learned function
- Customer support triage with episode reuse (industry)
- Description: Retrieve prior tickets that encode causal sequences or role relations in different formats to solve “reversed” cases (e.g., who caused vs who was affected; root-cause vs symptom-first investigations).
- Sector: Customer support, operations
- Tools/workflows: Ticket memory stores; latent-aware retrieval filters; prompt recipes with contrastive exemplars
- Assumptions/dependencies: Anonymization/compliance; sufficient episode diversity; retriever quality
- Regulatory/compliance Q&A with alternative task framing (policy/finance)
- Description: When asked questions framed differently from training (e.g., interpreting obligations from the regulated party’s perspective vs the regulator’s), retrieve policy episodes in varied formats to bridge the framing gap.
- Sector: Policy, finance (compliance/AML), legal
- Tools/workflows: Policy episodic index; multi-format retrieval; rationale logging
- Assumptions/dependencies: Up-to-date corpus; traceable reasoning; legal review for deployment
- Clinical decision support with episodic case retrieval (healthcare)
- Description: Retrieve prior patient case episodes that present alternative diagnostic paths or reversed relations (symptom→cause vs cause→symptom) to improve generalization across task framings.
- Sector: Healthcare
- Tools/workflows: Case-based retrieval, episodic memory of longitudinal visits; structured prompts with differential diagnosis exemplars
- Assumptions/dependencies: Regulatory approval; de-identification; human-in-the-loop review; validated performance before clinical use
- Educational tutors leveraging student episodic histories (education)
- Description: Retrieve past student interactions to infer latent skills/goals and adapt content (e.g., reverse reasoning tasks, multi-hop problems).
- Sector: Education
- Tools/workflows: Student episode stores; retrieval-guided lesson planning; ICL exemplars aligned to skill gaps
- Assumptions/dependencies: Privacy/consent; calibration to avoid overfitting to idiosyncratic episodes
- BI/analytics assistants for “reverse metric” queries (finance/operations)
- Description: When asked to invert a known pipeline (e.g., “Which suppliers lead to delays in product X?” vs “Which products are delayed by supplier Y?”), retrieve episodic dashboard narratives and ETL examples to contextualize the inversion.
- Sector: Finance, operations, supply chain
- Tools/workflows: Narrative retrieval from analytics logs; ETL episode indexing; prompt templates that show structured inversions
- Assumptions/dependencies: Data lineage availability; robust entity matching
- Robotics/navigation with prior route retrieval (robotics)
- Description: Use episodic trajectory retrieval (e.g., gridworld analog) to plan routes to targets never explicitly trained as goals but frequently observed, improving zero-shot navigation to latent goals.
- Sector: Robotics, autonomous systems
- Tools/workflows: Trajectory memory; map-index retrievers; context-augmented planners
- Assumptions/dependencies: Map generalization; localization accuracy; compute on-device for retrieval
- Model evaluation harnesses for latent learning (academia/industry)
- Description: Incorporate tests like codebooks, simple reversals, semantic structure, and navigation analogs into CI pipelines to audit whether models generalize beyond explicit training tasks/formats.
- Sector: Academia, MLOps
- Tools/workflows: Latent-learning benchmark suites; report cards with reversal/multi-hop scores
- Assumptions/dependencies: Domain-specific instantiations; clear success metrics
- Training data curation for ICL (academia/industry)
- Description: Increase the prevalence of within-example ICL-supporting sequences (e.g., paired forward/reverse relations, multi-hop chains) and bursty/long-tailed episodes to teach models to use retrieved info across episodes.
- Sector: ML platform teams
- Tools/workflows: Data augmentation focused on format diversity; curriculum design; episodic replay during training
- Assumptions/dependencies: Avoiding data leakage/label bias; cost of longer contexts
Long-Term Applications
The following require further research, scaling, or development—particularly in episodic memory architectures, retrieval quality, and training regimes that teach models to generalize across retrieved episodes.
- Integrated episodic memory modules for LLMs (software/AI systems)
- Description: Build hippocampus-like index layers that store compressed episodes and support rapid reinstatement into context, complementing parametric knowledge.
- Sector: Software/AI platforms
- Tools/products: Memory indexing layers; learned retrieval; selective replay
- Assumptions/dependencies: Efficient storage and recall; alignment and privacy; standardized APIs; non-oracle retrieval performance
- Latent task discovery and prospective learning (academia/AI research)
- Description: Agents that proactively identify tasks latent in their environment/data and cache solutions (“preplay”), improving future adaptation without explicit task signals.
- Sector: AI research, robotics
- Tools/products: Task-agnostic episodic caches; planners that hypothesize counterfactual goals; adaptive curricula
- Assumptions/dependencies: Reliable task inference; evaluation protocols; safety constraints
- Retrieval-centric RL in complex environments (robotics/games)
- Description: Agents that leverage episodic retrieval (trajectories, state abstractions) to plan toward goals never trained explicitly, scaling the latent gridworld concept to real-world settings.
- Sector: Robotics, autonomous driving, logistics
- Tools/products: Behavior-cloning plus retrieval hybrids; memory-augmented planners; map-semantic stores
- Assumptions/dependencies: Robust sim-to-real transfer; continual learning with replay; compute budgets
- Cross-lingual latent knowledge transfer via episodic memory (education/software)
- Description: Use episodic retrieval to transfer knowledge across languages and formats (e.g., retrieve episodes in language A to answer in language B).
- Sector: Education technology, multilingual enterprise systems
- Tools/products: Multilingual memory stores; format-bridging retrievers; cross-lingual ICL templates
- Assumptions/dependencies: High-quality translation/alignment; careful evaluation of cultural/semantic drift
- Enterprise knowledge graph auto-augmentation (software/enterprise)
- Description: Automatically generate reversed and multi-hop edges by retrieving diverse episodes that imply them, improving coverage and consistency.
- Sector: Enterprise knowledge management
- Tools/products: Latent-edge generators; audit tools; provenance tracking
- Assumptions/dependencies: Governance; error correction; source reliability
- Healthcare longitudinal memory systems (healthcare)
- Description: Episodic memory of patient trajectories to enable latent diagnostic reasoning and alternative goal planning (e.g., treatment to symptom relief vs symptom to cause).
- Sector: Healthcare
- Tools/products: Secure episodic EHR modules; retrieval-enhanced clinical decision support
- Assumptions/dependencies: Regulatory scrutiny; clinical validation; bias monitoring; human oversight
- Financial crime detection with episodic transaction memory (finance)
- Description: Retrieve episodic transaction sequences to detect latent patterns (e.g., alternative pathways that imply the same risk) beyond explicit rules.
- Sector: Finance (AML/fraud)
- Tools/products: Sequence-memory risk engines; contrastive retrieval; case-based reasoning layers
- Assumptions/dependencies: Data sharing constraints; false-positive mitigation; regulatory acceptance
- Energy/IoT fault diagnosis using latent signal retrieval (energy/industrial)
- Description: Episodic retrieval of prior incident sequences to recognize latent causes from alternative symptom sets or reversed causal narratives.
- Sector: Energy, manufacturing, IoT
- Tools/products: Incident memory stores; causal-structure retrieval; ICL-based diagnosticians
- Assumptions/dependencies: Sensor fidelity; labeling; integration with control systems
- Standards and governance for memory systems (policy/industry)
- Description: Develop policies for episodic data retention, privacy, relevance criteria, and evaluation metrics specific to latent learning and retrieval.
- Sector: Policy, industry consortia
- Tools/products: Governance frameworks; audit protocols; public benchmarks
- Assumptions/dependencies: Cross-industry buy-in; compliance frameworks; transparent reporting
- Offline replay strategies to separate learning from environment statistics (academia/AI research)
- Description: Use prioritized replay of episodic memories to consolidate generalizable knowledge without being tightly bound to the immediate environment distribution.
- Sector: AI research, platform teams
- Tools/products: Replay schedulers; memory-aware optimizers; consolidation pipelines
- Assumptions/dependencies: Avoid catastrophic forgetting; storage/compute trade-offs; curriculum design
- Memory-native application platforms (software)
- Description: Platforms that treat episodic memory as a first-class primitive—exposing APIs for episode write/read, relevance scoring, and context reinstatement—so product teams can build latent-learning-aware features by default.
- Sector: Software/platform engineering
- Tools/products: Memory SDKs; observability for retrieval; cost controls
- Assumptions/dependencies: Developer adoption; interoperability with model providers; performance guarantees
Notes on feasibility across applications:
- The paper’s empirical gains rely on oracle retrieval; real systems must approximate this with high-quality retrievers, indexing, and relevance scoring.
- Benefits are largest when training contains ICL-supporting sequences; data curation and curriculum design are critical dependencies.
- Associative cues can mask latent-learning deficits; evaluation should include tests that remove associative shortcuts.
- Context-length, privacy, storage, and compute constraints meaningfully affect performance and viability; governance and human oversight are necessary in sensitive domains (healthcare, finance, policy).
Glossary
- ADAM: An optimization algorithm for training neural networks using adaptive moment estimation. "using ADAM \citep{kingma2014adam}"
- autoregressive prediction: A modeling approach where the next token is predicted based on previous tokens in sequence. "trained via autoregressive prediction on sequences of the form "
- auxiliary reconstruction losses: Additional objectives that force a model to reconstruct inputs to improve representation learning. "including auxiliary reconstruction losses that force the agent to reconstruct its visual and textual inputs \citep[cf.] []{chan2022data}"
- behavioral cloning (BC): A supervised learning method where an agent learns to imitate expert actions from demonstrations. "agents are trained either with reinforcement learning (RL) from pixels or with behavioral cloning (BC) from an ASCII representation."
- bootstrap confidence intervals (CIs): Uncertainty estimates computed by resampling the data. "(For RL they are bootstrap CIs across 3 runs.)"
- bursty and long-tailed learning experiences: Data distributions with sporadic bursts and heavy tails that can foster in-context learning. "the presence of bursty and long-tailed learning experiences incentivize ICL while remaining ecologically plausible."
- cached memory states: Stored internal states retrieved for reuse without recomputation. "in the RL environment they are retrieved as cached memory states."
- causal language-modeling objective: A training objective for predicting the next token based on past tokens in a left-to-right manner. "we train a decoder-only transformer on a standard causal language-modeling objective using ADAM"
- complementary learning systems: A theory that fast, episodic hippocampal learning complements slower, generalized neocortical learning. "complementary learning systems \citep{mcclelland1995there,kumaran2016learning}"
- decoder-only transformer: A transformer architecture composed solely of a decoder for autoregressive generation. "we train a decoder-only transformer"
- episodic memory: Memory of specific experiences that can be reinstated to guide flexible behavior. "Episodic memory complements parametric consolidated knowledge."
- gridworld: A discrete, maze-like environment used to study navigation and reinforcement learning. "We finally show results on the more complex gridworld environment"
- hippocampus: A brain region critical for episodic memory and indexing experiences for later retrieval. "approximate the role of the hippocampus as a memory index in natural intelligence \citep{teyler1986hippocampal}"
- IMPALA: A scalable distributed reinforcement learning algorithm. "using IMPALA \citep{espeholt2018impala}"
- in-context learning (ICL): The ability of a model to learn and apply patterns from examples provided in its input context without parameter updates. "12.5\% of ICL sequences that have both forward and backward relations in the context."
- LMs: Models that learn distributions over text to perform tasks like generation and question answering. "LMs show surprising failures to generalize to reversals of their training"
- latent learning: Learning information not immediately relevant to the current task but useful for future tasks. "failure to exhibit latent learning---learning information that is not relevant to the task at hand, but that might be useful in a future task."
- marginalization: Integrating over multiple possibilities, such as documents, to aggregate evidence or predictions. "additional marginalization over multiple documents"
- medial temporal lobe (MTL): A brain region (including the hippocampus) implicated in episodic memory and certain generalizations. "medial temporal lobe (MTL; including the hippocampus)"
- meta-learning: Learning to learn across tasks or contexts so that a system can rapidly adapt to new tasks. "this capability can be meta-learned"
- multi-hop inference: Reasoning that requires chaining multiple facts or relations. "failures of multi-hop inference"
- neocortex: A brain region associated with slower, generalized learning and knowledge consolidation. "within the neocortex."
- non-injective: A mapping where distinct inputs can produce the same output. "Note that may be non-injective;"
- nonparametric learning systems: Memory-based systems that store and retrieve specific experiences rather than relying solely on learned parameters. "explicit retrieval from nonparametric learning systems complements the broader knowledge of parametric learning"
- oracle retrieval: An idealized mechanism that supplies the most relevant past experiences or documents to the model at train/test time. "a system with an oracle retrieval mechanism can use learning experiences more flexibly"
- prioritized replay: A learning process that replays select experiences (often high-value or informative) more frequently during offline learning. "the prioritized replay of episodic memories during offline learning separates the parametric knowledge representation from the statistics of the external environment"
- prospective learning: Learning oriented toward anticipated future tasks or changes in distribution. "a form of ``prospective learning'' \citep{desilva2023prospective}"
- reinforcement learning (RL): Learning to act via trial-and-error interactions to maximize cumulative reward. "agents are trained either with reinforcement learning (RL) from pixels"
- Retrieval Augmented Generation (RAG): A technique that augments a model’s context by retrieving relevant documents to improve generation or QA. "Retrieval Augmented Generation \citep[RAG;] []{lewis2020retrieval}"
- reversal curse: A phenomenon where models fail to generalize learned relations to their reversals outside of context. "The reversal curse \citep{berglund2024reversal}"
- semantic structure benchmark: An evaluation suite probing reversals, syllogisms, and category-inclusion holdouts in naturalistic text. "This dataset is adapted from the semantic structure benchmark of \citet{lampinen2025generalization}"
- syllogisms: Two-step logical inferences deriving a conclusion from two premises. "syllogisms (two-step logical inferences)"
- task cue: An input that specifies which task the model should perform in a given context. "task-cue-modulated mapping to an output space "
- transformer attention mechanisms: The attention operations in transformers that relate tokens and enable context-dependent processing. "transformer attention mechanisms and episodic memory in the brain"
- Zipfian distribution: A heavy-tailed probability distribution where frequency is inversely proportional to rank. "according to a skewed, Zipfian distribution"
Collections
Sign up for free to add this paper to one or more collections.