- The paper introduces Steering Vector Decoding (SVDecode) as a novel method that aligns LLM output distributions using KL divergence gradients.
- It employs a warm-start fine-tuning phase and logit-space projection to adjust responses without updating model weights.
- Experiments demonstrate that SVDecode improves multiple-choice accuracy by 5% and open-ended response truthfulness by 2% on commonsense tasks.
Distribution-Aligned Decoding for Efficient LLM Task Adaptation
Abstract Summary
The paper presents a novel method for adapting LLMs to downstream tasks with reduced computational cost, focusing on output distribution alignment during decoding instead of traditional fine-tuning approaches. The proposed Steering Vector Decoding (SVDecode) leverages a task-aware steering vector derived from KL divergence gradients between pre-trained and warm-started models, allowing efficient task adaptation compatible with parameter-efficient fine-tuning (PEFT) methods.
Introduction
LLMs like DeepSeek-R1 and OpenAI o1 have demonstrated impressive capabilities in numerous AI tasks but require substantial computational resources. Parameter-efficient fine-tuning (PEFT) aims to address this by modifying minimal model parameters, yet still indirectly alters model weights to achieve task-specific distribution alignment, leading to inefficiencies.
SVDecode reconceptualizes task adaptation as a direct process of steering decoding output distribution toward task-specific targets, removing reliance on weight updates. By computing a steering vector using the KL divergence gradient, it guides the model's generation output distribution, aligning it to the downstream task-specific target. The method theoretically matches the gradient step of full fine-tuning and offers robust empirical improvements across a range of tasks and benchmarks.
Methodology
Steering Vector Construction
The construction of the steering vector incorporates the following:
- Warm-Start Phase: The model undergoes limited fine-tuning in the downstream dataset to approximate the task-specific target distribution, updating parameters to yield Pϕ(y∣x).
- KL Gradient Signal: Calculate the gradient of KL divergence between the warm-started and pre-trained distributions, then utilize the negative gradient as the steering vector in output-space.
- Logit-Space Projection: The steering signal is projected into the logit space, balancing simplex geometry constraints and probabilistic normalization.
- Confidence-Aware Constraints: Suppress irrelevant tokens using confidence thresholding to ensure robust steering vector application in decoding.
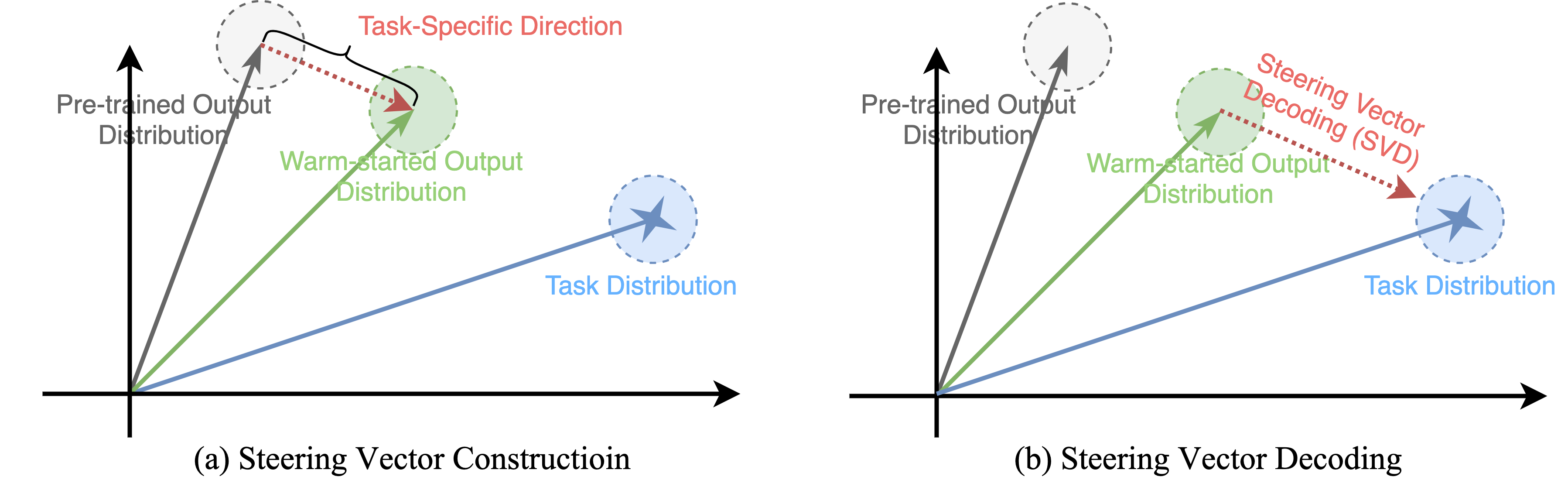
Figure 1: Illustration of Steering Vector Decoding framework.
Task-Aware Decoding
During decoding:
- Logit Adjustment: Incorporate the calculated steering vector to adjust model logits before application of the softmax function.
- Optimization of Steering Strength (μ): The step length μ is derived to optimize KL divergence alignment dynamically per task, computed using a Gauss-Newton approximation, with a globally averaged solution for decoding uniformity.
Experiments
Extensive evaluations across multiple downstream tasks demonstrate SVDecode's notable performance improvement over traditional methods, enhancing multiple-choice accuracy and open-ended response truthfulness without introducing additional trainable parameters.
Multi-Choice and Open-Ended Tasks
SVDecode shows robust performance gains, adding 5 percentage points to multiple-choice accuracy and 2 percentage points to truthfulness in open-ended tasks, validating its efficiency in steering-based adaptation.
Commonsense Reasoning Tasks
It consistently improves performance across commonsense datasets like BoolQ, PIQA, SIQA, reinforcing that direct steering, as opposed to weight adjustment, provides significant adaptation efficiency and accuracy.
Conclusion
SVDecode presents a transformative approach for large-scale LLM adaptation, offering low-cost, high-performance task alignment by steering decoding outputs directly. Bridging the gap between decoding control and traditional fine-tuning, SVDecode sets a new precedent for efficient AI model adaptation in resource-constrained environments.
The method's compatibility with established PEFT approaches and empirical validation across diverse tasks suggests potential wide-ranging applications for LLM deployment, pushing forward the boundaries of efficient AI task adaptation strategies.