- The paper presents a large-scale 5M-sample dataset for code LLM instruction tuning with integrated unit tests and LLM judgments.
- It utilizes a Genetic-Instruct framework combining evol-instruct and self-instruct methods to enhance sample diversity and accuracy.
- Fine-tuning experiments reveal marked performance gains on benchmarks like HumanEval and MBPP even with 500K samples.
OpenCodeInstruct: A Large-scale Instruction Tuning Dataset for Code LLMs
Overview of OpenCodeInstruct and Dataset Generation Pipeline
OpenCodeInstruct addresses the acute limitation in publicly available, high-quality supervised fine-tuning (SFT) datasets for code-centric LLM instruction tuning. The dataset, at 5M samples, represents a substantial increase over prior corpora. Each sample comprises a programming question, executable solution, LLM-generated unit tests, the pass/fail rates from execution feedback, and multi-faceted LLM-based quality assessments.
The development pipeline initiates with two seed sets: 1.43M Python functions extracted from Github (via OSS-Instruct methodology), and 25,443 algorithmic problems from TACO—reflecting broad domain and skill diversity. Synthetic samples are then generated using the Genetic-Instruct framework, combining evol-instruct (problem mutation and local diversification) and self-instruct (domain generalization through recombination), with rigorous deduplication and decontamination. Solutions to generated instructions are provided using capable code-specialized LLMs (Qwen2.5-Coder variants), and a thorough metadata layer is appended via automated unit tests and LLM judgments for each sample.
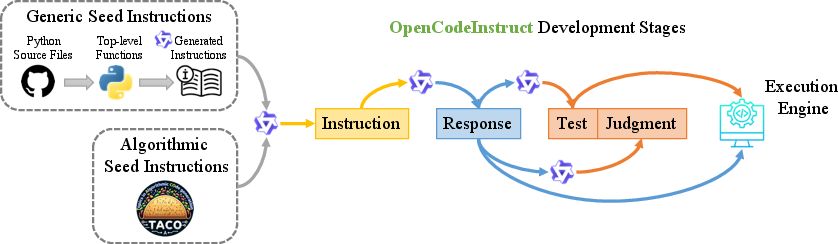
Figure 1: Overview of the OpenCodeInstruct development stages, demonstrating seed collection, synthetic instruction and solution generation, filtering, and annotation.
Dataset Structure, Skill Coverage, and Quality
OpenCodeInstruct integrates multiple evaluation layers for dataset quality: LLM-generated assertion unit tests (ten per sample) and scoring via LLM-as-a-judge using a quantitative rubric for requirement conformance, logical correctness, and edge case handling. Histograms of these scores highlight bimodal tendencies in solution correctness, typically reflecting self-consistency bias in LLM output.
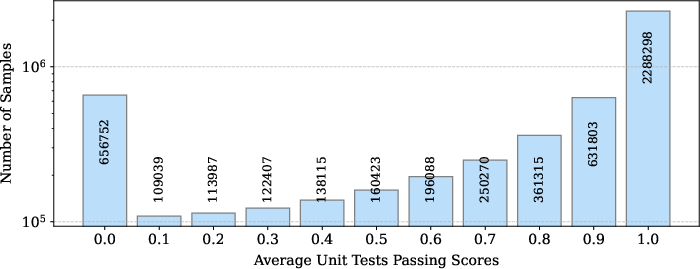
Figure 2: Histogram of average unit test pass rates for OpenCodeInstruct samples, indicating clusters of fully-correct and fully-incorrect solutions.
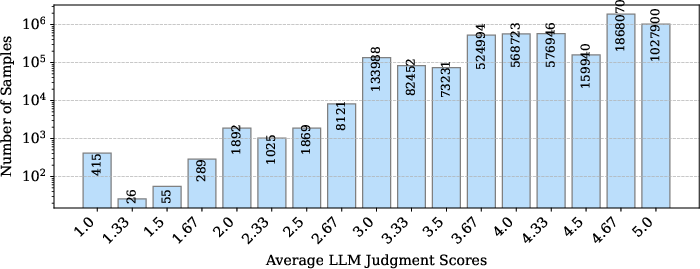
Figure 3: Histogram of average LLM-as-a-judge scores for OpenCodeInstruct samples, showcasing the concentration of high-judgment scores and outlier regions.
The included skills metadata, indexed for each solution, demonstrates extensive coverage across canonical data structure and algorithm categories. The variety within generated samples is substantial, confirmed both statistically and visually.

Figure 4: Visualization of LLM generated skills used or demonstrated in code solutions, with dense representation from arrays, search algorithms, and dynamic programming.
Model Finetuning and Benchmark Evaluation
Fine-tuning Llama3 and Qwen2.5-Coder models using OpenCodeInstruct at multiple parameter scales (1B+, 3B+, 7B+) yields pronounced gains on canonical code generation benchmarks: HumanEval, MBPP, LiveCodeBench, and BigCodeBench. Strong performance increments relative to existing instruct-tuned models indicate the importance of dataset size, diversity, and verification quality. Notably, fine-tuning with just 500K OpenCodeInstruct samples is sufficient to surpass the performance of the base instruct-tuned models.
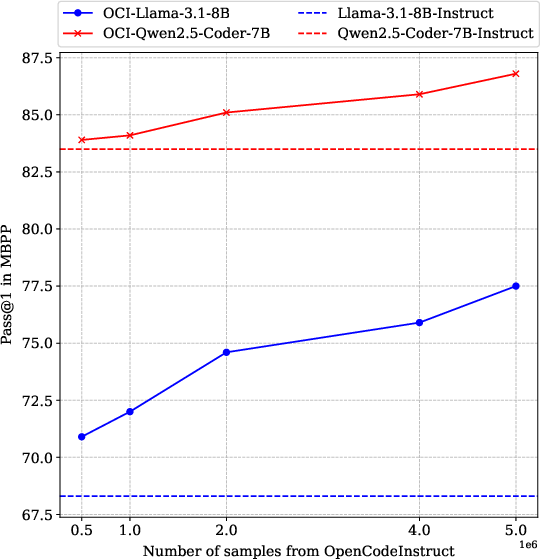
Figure 5: Finetuned model performances (Pass@1) on MBPP tasks when finetuned with increasing numbers of OpenCodeInstruct samples, demonstrating monotonic scaling behavior.
Further, head-to-head comparisons demonstrate that Qwen2.5-Coder models trained with OpenCodeInstruct outperform those trained with OSS-Instruct samples, confirming superior sample design and metadata's impact.
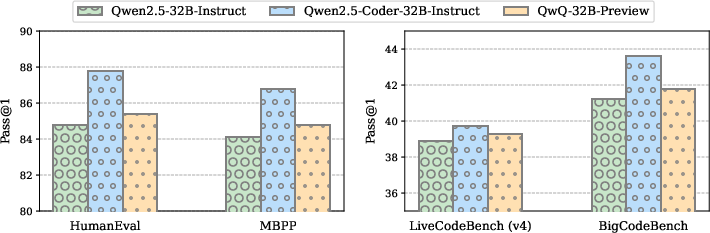
Figure 6: Performance comparison of finetuning Qwen2.5-Coder-7B using OpenCodeInstruct, across benchmarks when solutions are generated by three different LLMs.
Ablation and Analysis: Verification, Instruction, and Seed Strategy
A systematic ablation demonstrates the value of both execution-based unit test filtering and LLM-judgment-based selection. LLM judgment as a filter delivers highest downstream accuracy, more effectively capturing solution correctness and diversity than execution-only selection.
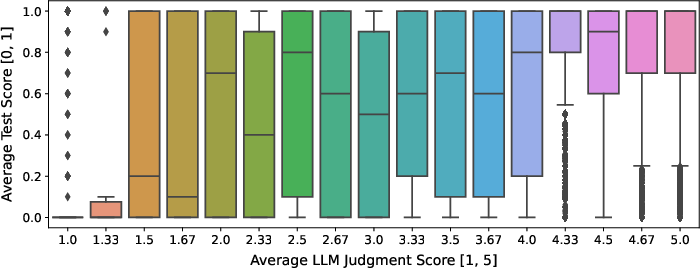
Figure 7: Visualization of the relationship between average unit test scores and average LLM judgment scores, highlighting correlations and outlier behaviors.
Instruction generation algorithms differ in their benchmark impact; evol-instruct provides local diversity and difficulty calibration, while self-instruct broadens domain coverage. Utilizing both in the Genetic-Instruct framework is empirically demonstrated to maximize benchmark performance. Seed set scale and domain diversity are directly proportional to final model efficacy, as evidenced by comparisons between algorithmic-only and generic instruction populations.
Instruction formatting study reveals that NL-to-Code (natural language to code synthesis) prompts consistently outperform code-to-code formulating, suggesting that natural language operationalization enables broader generalization and skill transfer in code LLMs.
Error Analysis and Verification Strategies
Detailed error categorization in failed test cases includes function execution errors, assertion mismatches, timeouts, and syntactic anomalies. The bimodal distribution in test pass rates motivates more nuanced evaluation approaches for large-scale instruction-tuning data.
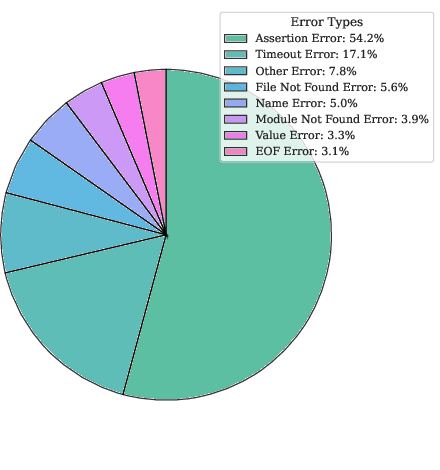
Figure 8: Fraction of error types in failed generated test cases, informing future directions for sample filtering and robustness improvements.
Practical and Theoretical Implications
The practical impact of OpenCodeInstruct lies in its scale, openness, and metadata richness—enabling rapid progress in code-centric LLM research without reliance on proprietary datasets. The robust annotation pipeline (unit tests, judgment, skills) provides a multi-use asset for benchmarking, RLHF, verification, and skill mapping. Theoretically, findings regarding seed diversity, instruction format, and verification methods chart next steps in synthetic data generation, hinting at instruction-tuning as a primary lever for advancing code reasoning and synthesis in LLMs.
OpenCodeInstruct's fully open-source availability sets a new standard for transparency and reproducibility in code LLM development. Its multifaceted verification apparatus is likely to inspire more sophisticated filtering, hybrid evaluation, and adaptive dataset creation methods in future research.
Conclusion
OpenCodeInstruct sets a new benchmark in scale and diversity for code instruction-tuning datasets. Empirical evaluations validate substantial improvements in downstream code generation performance, and the analyses delineate key dataset construction and fine-tuning parameters influencing model efficacy. Its open design and rich metadata support future innovation in code LLM verification, skill analysis, and benchmark construction. Future directions may include expanding language support, incorporating more advanced execution verification techniques, and leveraging multi-modal feedback for further improvement.